







今天帮同学从一个网站上下载点数据, 但是上面有上百个链接, 一个一个点击下载实在是工作量太大。 于是自己就想找一个命令行下载工具并用Python写一个简单的脚本来替代这些工作。
百度了一下, 找到了curl
curl: curl是利用URL语法在命令行方式下工作的文件传输工具。 [百科: http://baike.baidu.com/view/1326315.htm]
官网: http://curl.haxx.se/
其中libcurl有C语言、Python接口(PyCurl: http://pycurl.sourceforge.net/)等等。 curl.exe也可以作为一个命令行下载工具。
将来学习了多线程, 可以改为多线程下载 。
。
最简单的下载语法:
curl -o [filename] <url>
例如:
Microsoft Windows [版本 6.0.6001]
版权所有 (C) 2006 Microsoft Corporation。保留所有权利。
C:\Windows\system32>curl -o E:\MIT_BIH_Arrhythmia_Database\103.dat http://physionet.org/physiobank/database/mitdb/103.dat
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
1 1904k 1 23082 0 0 3582 0 0:09:04 0:00:06 0:08:58 3556curl --head <url>
获取下载文件的大小。例如:
C:\Windows\system32>curl --head http://physionet.org/physiobank/database/mitdb/100.atr
HTTP/1.1 200 OK
Date: Mon, 28 Nov 2011 05:35:46 GMT
Server: Apache/2.2.17 (Fedora)
Last-Modified: Thu, 30 Jul 1992 01:21:18 GMT
ETag: "82c1c18-11ce-287fa5a2e9f80"
Accept-Ranges: bytes
Content-Length: 4558
Connection: close
Content-Type: application/octet-streamcurl --connect-timeout <seconds> <url>
(参考: http://blog.csdn.net/learnhard/article/details/5683703)
连接超时时间设置。
curl -m <seconds> <url>
传输数据超时时间设置。 例如:
C:\Windows\system32>curl -o E:\MIT_BIH_Arrhythmia_Database\104.dat -m 20 "http://physionet.org/physiobank/database/mitdb/104.dat"
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
1 1904k 1 20162 0 0 953 0 0:34:06 0:00:21 0:33:45 377
curl: (28) Operation timed out after 20000 milliseconds with 20162 out of 195000
0 bytes received更多命令请参考:
http://blog.csdn.net/lizhitao/article/details/6039473
# !/usr/bin/env python
# Filename: down.py
# download files from http://physionet.org/physiobank/database/mitdb/
import os
home = r"E:\MIT_BIH_Arrhythmia_Database"
fext = [".atr", ".dat", ".hea"]
hurl = r"http://physionet.org/physiobank/database/mitdb/"
for ext in fext:
for index in range(100, 234):
fname = str(index) + ext
fsave = home + os.path.sep + fname
fget = hurl + fname
if False == os.path.isfile(fsave):
command = "curl -o " + fsave + " " + fget
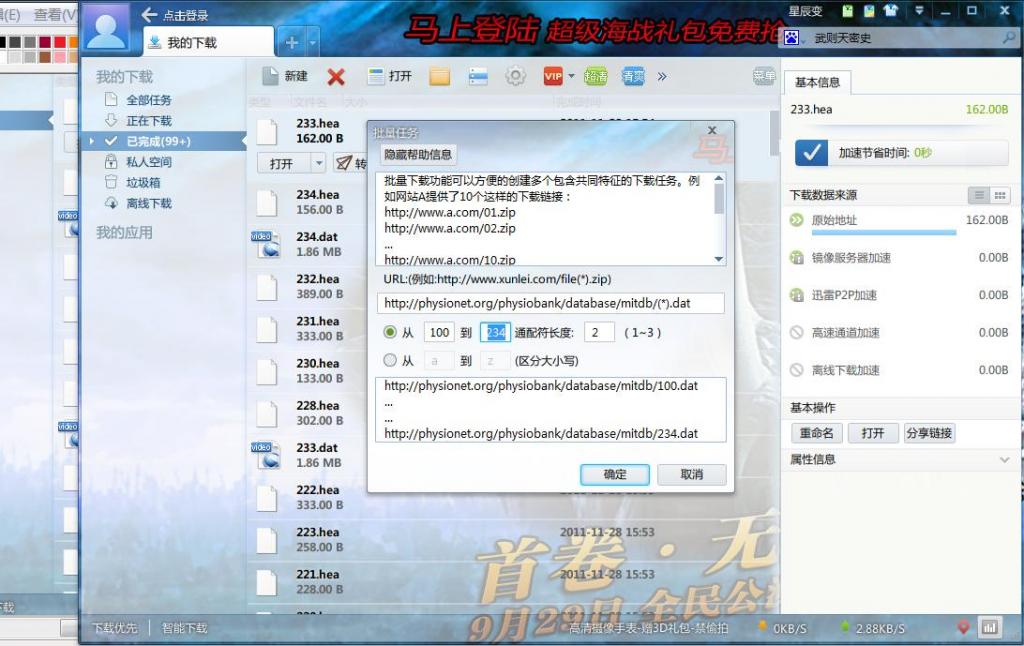
os.system(command)PS: 对于批量下载任务迅雷也有一个功能支持:
















 4884
4884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









