







简介
哈希表/散列表(HashTable)是一种根据关键字(key)直接进行访问数据存储位置的数据结构。他通过一个关键字的函数把数据映射到表中的储存位置,这个映射函数叫做散列函数或者哈希函数,存放数据的数组就叫做散列表,即哈希表。
哈希表的应用
哈希表经常被用于信息安全方面,因为哈希表可以把数据和存放地址映射起来,从而实现加密。或者说他是把一些不同长度的信息转化成杂乱的编码,这些编码叫做哈希值。
哈希表也用于数据库中的数据查找,因为哈希表的特性,让它成为了一种高效的查找结构体,时间复杂度一般都在O(N)。
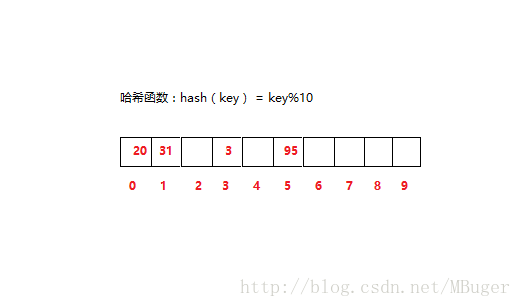
如图是哈希函数为一个hash(key)= key%10(这里模的数为哈希表容量大小)的哈希表,并按照计算结果存放了20、31、3、95。
哈希表的结点设计
哈希表因为是一种搜索结构,所以在每个哈希结点中有关键字key值和value值,结点里还给出了一个状态值status,表示这个结点的当前储存状态,分别为EXIST(存在)DELETE(被删除)EMPTY(空)。为了方便查找最后这些结点被存放在一个vector里。
enum Status
{
EXIST,
DELETE,
EMPTY,
};
template<class K, class V>
struct HashNode
{
K _key;
V _value;
Status _status;
HashNode(const K& key = K(), const V& value = V())
:_key(key)
, _value(value)
, _status(EMPTY)
{}
};
看到这里一些人肯定会有疑问,如果出现计算结果相同的情况应该怎么办?这里便出现了一个新的概念叫做哈希冲突。
哈希冲突
不同的key值经过哈希函数处理之后可能产生相同的值即哈希地址相同,这就叫做哈希冲突,任何的哈希函数都不能避免这个问题。
为了解决哈希冲突的问题这里给出了两种常用的解决方法。
1.开放地址法
这种方法的主要思想是当出现哈希冲突时使用探测的方法在哈希表中形成一个探测序列,按照这个序列逐个的探查,直到碰到一个开放的地址即该哈希地址为空为止。
如图,如果再向哈希表中插入41,哈希函数计算结果发现和31冲突,则往右一个一个探测,探测到2位置为空,放入41。
再插入11,算得哈希地址和31冲突,往右进行探查,2位置不空,往右偏移,3位置不空,继续偏移,4位置空,放入11。
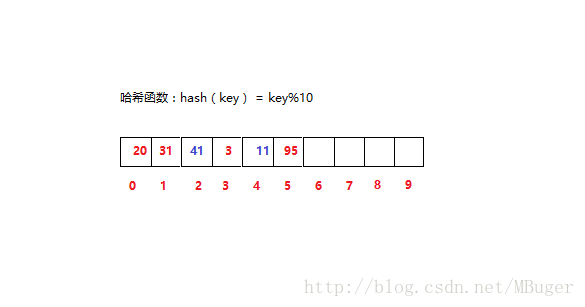
这种探查测方法叫做线性探查,他的思想就是如果出现哈希冲突则按照线性规则依次探测,直到解决哈希冲突。除了这种方式我们还有类似的二次探测,也就是出现哈希冲突后按照hash(key)+i^2的规则探测。
代码实现
//定义仿函数
template<typename K>
struct __HashFunc
{
size_t operator()(const K& key)
{
return key;
}
};
//特化string的版本
template<>
struct __HashFunc<string>
{
static size_t BKDRHash(const char*str)
{
unsigned int seed = 131;// 31 131 1313 13131 131313
unsigned int hash = 0;
while (*str)
{
hash = hash*seed + (*str++);
}
return(hash & 0x7FFFFFFF);
}
size_t operator ()(const string &key)
{
return BKDRHash(key.c_str());
}
};
//给出素数表,表内为哈希表的容量,素数降低哈希冲突
const int _PrimeSize = 28;
static const unsigned long _PrimeList[_PrimeSize] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul,
786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul,
25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul,
805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};以上是给出的哈希函数和素数表。为了方便不同类型的数据存储哈希函数给出了仿函数的形式,并在下面给出了string类的特化形式。特化后的哈希函数使用了BKDR哈希函数处理。
素数表里存放的是哈希表的容量,用素数作为容量可以在一定程度上减少哈希冲突。
template<typename K, typename V, typename HashFunc = __HashFunc<K>>
class HashTable
{
typedef HashNode<K, V> Node;
public:
HashTable()
{}
HashTable(size_t size)
:_size(0)
{
assert(size > 0);
_v.resize(size);
}
//将K值转换成哈希值
size_t __HashFunC(const K& key)
{
HashFunc hf;//定义一个HashFunc的变量hf
size_t hash = hf(key);//用变量hf调用HashFunc的仿函数,返回对应的整型
return hash % _v.size();//算出哈希值,并返回
}
pair<Node*, bool> Insert(const K& key,const V& value)
{
//检查是否需要扩容
CheckCapacity();
//对K值进行取余,判断插入的位置
size_t index = HashFunC(key);
//如果存在,则循环着继续寻找
while (_v[index]._status == EXIST)
{
index++;
if (index == _v.size())
index = 0;
}
_v[index]._key = key;
_v[index]._value = value;
_v[index]._status = EXIST;
_size++;
return make_pair<Node*,bool>(&_v[index] ,true);
}
Node* find(const K& key)
{
//对K值进行取余,判断插入的位置
size_t index = HashFunC(key);
//如果存在,则继续寻找
while (_v[index]._status == EXIST)
{
//若相等,判断状态是否是删除
//若删除,则没找到,返回空
//若没删除,则返回该位置的地址
if (_v[index]._key == key)
{
if (_v[index]._status == DELETE)
return NULL;
return &_v[index];
}
index++;
if (index == _size)
index = 0;
}
return &_v[index];
}
void Remove(const K& key)
{
//删除仅需要将状态修改
Node* delNode = find(key);
if (delNode)
delNode->_status = DELETE;
}
protected:
vector<Node> _v;
size_t _size;
protected:
//交换两个哈希表
void Swap(HashTable<K, V> &h)
{
swap(_v, h._v);
swap(_size, h._size);
return;
}
void CheckCapacity()
{
//如果_v为空,则扩容到7
if (_v.empty())
{
_v.resize(_PrimeList[0]);
return;
}
//如果超过比例系数,则需要扩容
if (_size*10 / _v.size() >= 7)
{
/*size_t newSize = 2 * _v.size();*/
//找到更大一个的素数
size_t index = 0;
while (_PrimeList[index] < _v.size())
{
index++;
}
size_t newSize = _PrimeList[index];
//用一个临时变量来存储新生成的哈希表
//生成完成后,将其和_v交换
HashTable<K, V> tmp(newSize);
for (size_t i = 0; i < _v.size(); ++i)
{
//如果存在,则将该位置的哈希值插入到临时的哈希表中
if (_v[i]._status == EXIST)
tmp.Insert(_v[i]._key,_v[i]._value);
}
//交换两个哈希表
Swap(tmp);
}
}
};时间复杂度
哈希表的线性探测实现方法在查找删除的操作上的时间复杂度基本为O(1),这正是因为哈希地址就与数组下标地址相同,通过数组下标直接访问数组就可以找到value。并且只要使用合适的哈希函数就可以使时间复杂度和空间复杂度都最优。
线性探查解决方案的缺陷
①.当数据过多而哈希表的长度不够时,则会出现溢出。处理这种问题往往会在哈希表之外再给上一个溢出表用来存放溢出数据。
②.容易产生堆聚现象,当发生冲突时,如果按照线性探测的方式解决,数据就会成为哈希表中的连续序列,这种连续序列越长,那么当插入新数据时发生哈希冲突的可能性就越大。成为一种恶性循环。















 3189
3189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









