







SAE与DBM两个都可以用于提取输入集特征。
SAE
SAE是由多个Spase AutoEncoder堆叠而成,单个Spase AutoEncoder的结构如下:
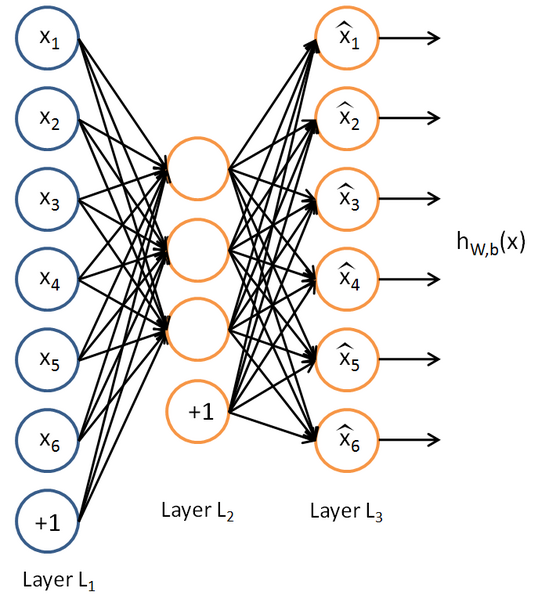
在堆叠成SAE时的结构如下:
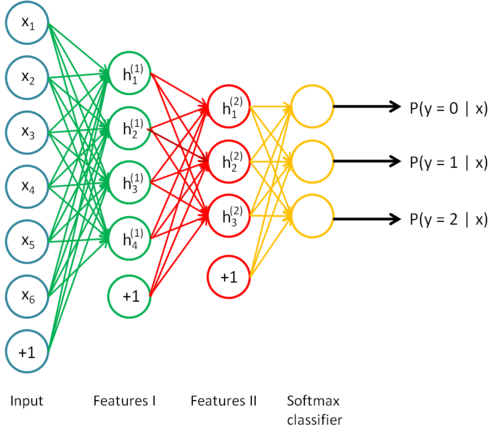
以上SAE的结构可以化分为两个sparse autoencoder和一个 softmax(这里不讨论softmax).其中的两个sparse autoencoder结构如图:
第一层:
第二层: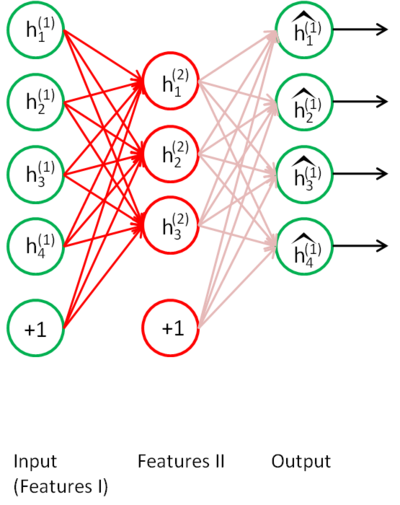
在训练SAE的时候,也是一层一层的进行训练,首先将原始数据输入训练第一层sparse autoencoder,获得了第一层的features(也就是训练获得的参数权重W1和偏置b1),而后根据:
z2 = W1*data+repmat(b1,1,m);
activation = sigmoid(z2);
获得activation作为输入训练第二层sparse autoencoder,以此类推。
DBM
DBM可以说是由多个RBM叠加起来的(注意与DBM的区别)。
DBM由多层神经元构成,这些神经元又分为显性神经元和隐性神经元(以下简称显元和隐元)。显元用于接受输入,隐元用于提取特征。因此隐元也有个别名,叫特征检测器 (feature detectors)。最顶上的两层间的连接是无向的,组成联合内存 (associative memory)。较低的其他层之间有连接上下的有向连接。最底层代表了数据向量 (data vectors),每一个神经元代表数据向量的一维。
DBM 的组成元件是受限玻尔兹曼机 (Restricted Boltzmann Machines, RBM)。训练 DBM 的过程是一层一层地进行的。在每一层中,用数据向量来推断隐层,再把这一隐层当作下一层 (高一层) 的数据向量。
RBM 的训练过程,实际上是求出一个最能产生训练样本的概率分布。
RBM: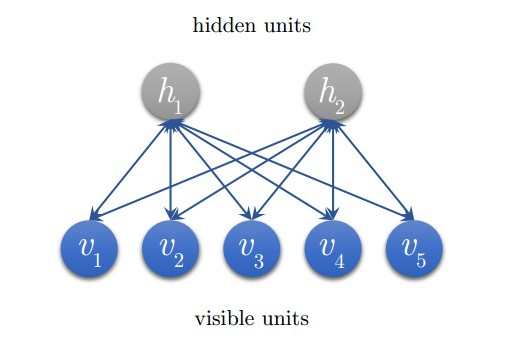
总结
sae是非线性变换找到主特征方向,而dbm是基于样本的概率分布来提取高层表示。两者的的基本单元sparse autoencoder和rbm的基本原理是不同的。训练方法上,sae一般用梯度下降方法,而dbm则是kl散度。sae和dbm训练的整体流程都是一致的,都是一层一层进行训练。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









