







By Ilya Grigorik on January 31, 2013 (翻译:Horky [http://blog.csdn.net/horkychen])
Google Chrome的历史和指导原则
【译注】这部分不再详细翻译,只列出核心意思。
驱动Chrome继续前进的核心原则包括:
- Speed: 做最快的(fastest)的浏览器.
- Security:为用户提供最为安全的(most secure)的上网环境。
- Stability: 提供一个健壮且稳定的(resilient and stable)的Web应用平台。
- Simplicity: 以简练的用户体验(simple user experience)封装精益求精的技术(sophisticated technology)。
关于性能的方方面面
一个现代浏览器就是一个和操作系统一样的平台。在Chrome之前的浏览器都是单进程的应用,所有页面共享相同的地址空间和资源。引入多进程架构这是Chrome最为著名的改进【译注:省略一些反复谈论的细节】。
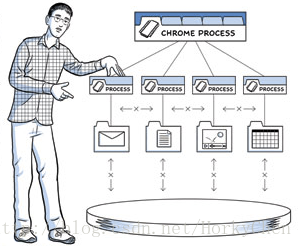
Chrome的渲染引擎是WebKit, JavaScript Engine则使用深入优论的V8 ("V8" JavaScript runtime)。但是,如果网络不畅,无论优化V8的JavaScript执行,还是优化WebKit的解析和渲染,作用其实很有限。巧妇难为无米之炊,数据没来就得等着!
关于Web应用
开始正题前,还是先来了解一下现在网页或者Web应用在网络上的需求。
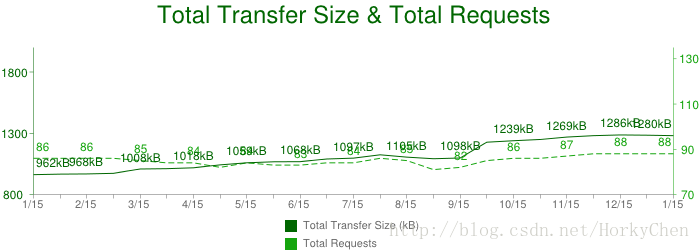
- 1280 KB
- 包含88个资源(Images,JavaScript,CSS ...)
- 连接15个以上的不同主机(distinct hosts)。
一个Resource Request的一生
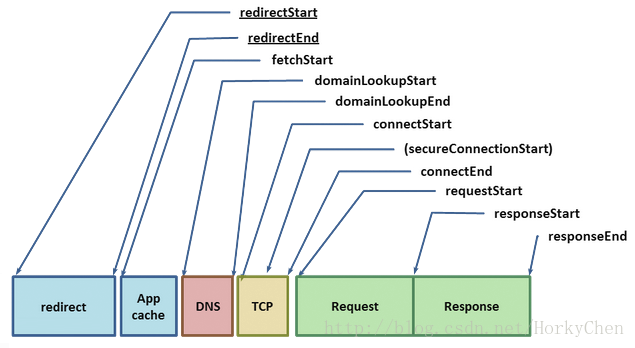

当TCP握手完成了,如果我们连接的是一个HTTPS地址,还有一个SSL握手过程,同时又要增加最多两轮的延迟等待。如果SSL会话被缓存了,就只需一次。
requestStart)。服务器收到请求后,就会传送响应数据(response data)回到客户端。这里包含最少的往返延迟和服务的处理时间。然后一个请求就完成了。但是,如果是一个HTTP重定向(redirect)的话?我们又要从头开始这个过程。如果你的页面里有些冗余的重定向,最好三思一下!- 50ms for DNS
- 80ms for TCP handshake (one RTT)
- 160ms for SSL handshake (two RTT's)
- 40ms (发送请求到服务器)
- 100ms (服务器处理)
- 40ms (服务器回传响应数据)
一个请求花了470毫秒, 其中80%的时间被网络延迟占去了。看到了吧,我们真得有很多事情要做!事实上,470毫秒已经很乐观了:
- 如果服务器没有达到到初始TCP的拥塞窗口(congestion window),即4-15KB,就会引入更多的往返延迟。
- SSL延迟也可能变得更糟。如果需要获取一个没有的认证(certificate)或者执行 online certificate status check (OCSP), 都会让我们需要一个新的TCP连接,又增加了数百至上千毫秒的延迟。
怎样才算"够快"?
前面可以看到服务器响应时间仅是总延迟时间的20%,其它都被DNS,握手等操作占用了。过去用户体验研究( user experience research )表明用户对延迟时间的不同反应:
| 延迟 | 用户反应 |
| 0 - 100ms | 迅速 |
| 100 - 300ms | 有点慢 |
| 300 - 1000ms | 机器还在运行 |
| 1s+ | 想想别的事…... |
| 10s+ | 我一会再来看看吧... |
上表同样适用于页面的性能表现: 渲染页面,至少要在250ms内给个回应来吸引住用户。这就是简单地针对速度。从Google, Amazon, Microsoft,以及其它数千个站点来看,额外的延迟直接影响页面表现:流畅的页面会吸引更多的浏览、以及更强的用户吸引力(engagement)和页面转换率(conversion rates).
现在我们知道了理想的延迟时间是250ms,而前面的示例告诉我们,DNS Lookup, TCP和SSL握手,以及request的准备时间花去了370ms, 即便不考虑服务器处理时间,我们也超出了50%。
对于绝大多数的用户和网页开发者来说,DNS, TCP,以及SSL延迟都是透明,很少有人会想到它。这也就是为什么Chrome的网络模块那么的复杂。
我们已经识别出了问题,下面让我们深入一下实现的细节...
深入Chrome的网络模块
多进程架构
Chrome的多进程架构为浏览器的网络请求处理带来了重要意义,它目前支持四种不同的执行模式( four different execution models ).
默认情况下,桌面的Chrome浏览器使用process-per-site模式, 将不同的网站页面隔离起来, 相同网站的页面组织在一起。举个简单的例子: 每个tab独立一个进程。从网络性能的角度上说,并没什么本质上的不同,只是process-per-tabl模式更易于理解。
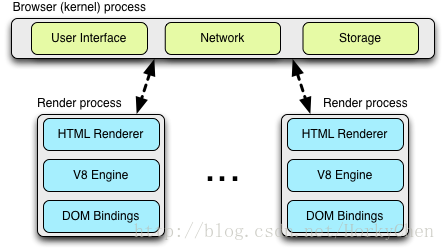
进程间通讯(IPC)和多进程资源加载
渲染进程和内核进程之间的通讯是通过IPC完成的。在Linux和Mac OS上,使用了一个提供异步命名管道通讯方式的socketpair()。每一个渲染进程的消息会被序列化地到一个专用的I/O线程中,然后再由它发到内核进程。在接收端,内核进程提供一个过滤接口(filter interface)用于解析资源相关的IPC请求( ResourceMessageFilter ), 这部分就是网络模块负责的。
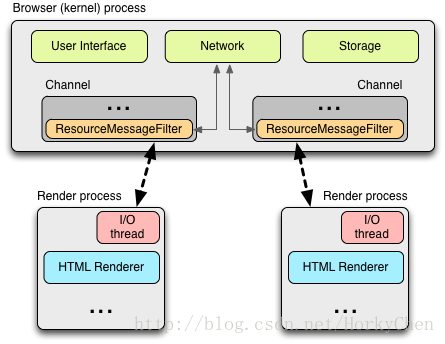
这样做其中一个好处是所有的资源请求都由I/O进程处理,无论是UI产生的活动,或者网络事件触发的交互。在内核进程(browser/kernel process)的I/O线程解析资源请求消息,将转发到一个ResourceDispatcherHost的单例(singleton)对象中处理。
这个单例接口允许浏览器控制每个渲染进程对网络的访问,也能达到有效和一致的资源共享:
- Socket pool 和 connection limits: 浏览器可以限定每一个profile打开256个sockets, 每个proxy打开32个sockets, 而每一组{scheme, host, port}可以打开6个。注意同时针对一组{host,port}最多允计打开6个HTTP和6个HTTPS连接。
- Socket reuse: 在Socket Pool中提供持久可用的TCP connections,以供复用。这样可以为新的连接避免额外建立DNS、TCP和SSL(如果需要的话)所花费的时间。
- Socket late-binding(延迟绑定): 网络请求总是当Scoket准备好发送数据时才与一个TCP连接关连起来,所以首先有机会做到对请求有效分级(prioritization),比如,在socket连接过程中可能会到达到一个更高优先级的请求。同时也可以有更好的吞吐率(throughput),比如,在连接打开过程中,去复用一个刚好可用的socket, 就可以使用到一个完全可用的TCP连接。其实传统的TCP pre-connect(预连接)及其它大量的优化方法也是这个效果。
- Consistent session state (一致的会话状态): 授权、cookies及缓存数据会在所有渲染进程间共享。
- Global resource and network optimizations (全局资源和网络优化): 浏览器能够在所有渲染进程和未处理的请求间做更优的决策。比如给当前tab对应的请求以更好的优先级。
- Predictive optimizations (预测优化): 通过监控网络活动,Chrome会建立并持续改善预测模型来提升性能。
- ... 项目还在增加中.
单就一个渲染进程而言, 透过IPC发送资源请求很容易,只要告诉浏览器内核进程一个唯一ID, 后面就交给内核进程处理了。
跨平台的资源加载
跨平台也是Chrome网络模块的一个主要考量,包括Linux, Windows, OS X, Chrome OS, Android, 和iOS。 为此,网络模块尽量实现成了单进程模式(只分出了独立的cache和proxy进程)的跨平台函数库, 这样就可以在平台间共用基础组件(infrastructure)并分享相同的性能优化,更有机会做到同时为所有平台进行优化。
相关的代码可以在这里找到the "src/net" subdirectory)。本文不会详细展开每个组件,不过了解一下代码结构可以帮助我们理解它的能力结构。 比如:
| net/android | 绑定到Android 运行时(runtime) [译注(Horky):运行时真是一个很烂的术语,翻和没翻一样。] |
| net/base | 公共的网络工具函数。比如,主机解析,cookies, 网络转换侦测(network change detection),以及SSL认证管理 |
| net/cookies | 实现了Cookie的存储、管理及获取 |
| net/disk_cache | 磁盘和内存缓存的实现 |
| net/dns | 实现了一个异步的DNS解析器(DNS resolver) |
| net/http | 实现了HTTP协议 |
| net/proxy | 代理(SOCKS 和 HTTP)配置、解析(resolution) 、脚本抓取(script fetching), ... |
| net/socket | TCP sockets,SSL streams和socket pools的跨平台实现 |
| net/spdy | 实现了SPDY协议 |
| net/url_request | URLRequest, URLRequestContext和URLRequestJob的实现 |
| net/websockets | 实现了WebSockets协议 |
上面每一项都值得好好读读,代码组织的很好,你还会发现大量的单元测试。
Mobile平台上的架构和性能
移动浏览器正在大发展,Chrome团队也视优化移动端的体验为最高优先级。先要说明的是移动版的Chrome的并不是其桌面版本的直接移植,因为那样根本不会带来好的用户体验。移动端的先天特性就决定了它是一个资源严重受限的环境,在运行参数有一些基本的不同:
- 桌面用户使用鼠标操作,可以有重叠的窗口,大的屏幕,也不用担心电池。网络也非常稳定,有大量的存储空间和内存。
- 移动端的用户则是触摸和手势操作,屏幕小,电池电量有限,通过只能用龟速且昂贵的网络,存储空间和内存也是相当受限。
再者,不但没有典型的样板移动设备,反而是有一大批各色硬件的设备。Chrome要做的,只能是设法兼容这些设备。好在Chrome有不同的运行模式(execution models),面对这些问题,游刃有余!
在Android版本上,Chrome同样运用了桌面版本的多进程架构- 一个浏览器内核进程,以及一个或多个渲染进程。但因为内存的限制,移动版的Chrome无法为每一个tabl运行一个特定的渲染进程,而是根据内存情况等条件决定一个最佳的渲染进程个数,然后就会在多个tab间共享这些渲染进程。
如果内存实在不足,或其它原因导致Chrome无法运行多进程,它就会切到单进程、多线程的模式。比如在iOS设备上,因为其沙箱机制的限制,Chrome只能运行在这种模式下。
关于网络性能,首先Chrome在Android和iOS使用的是各其它平台相同的网络模块。这可以做到跨平台的网络优化,这也是Chrome明显领先的优势之一。所不同的是需要经常根据网络情况和设备能力进行些调整,包括推测优化(speculative optimization)的优先级、socket的超时设置和管理逻辑、缓存大小等。
比如,为了延长电池寿命,移动端的Chrome会倾向于延迟关闭空闲的sockets (lazy closing of idle sockets), 通常是为了减少信号(radio)的使用而在打开新的socket时关闭旧的。另外因为预渲染(pre-rendering,稍后会介绍)会使用一定的网络和处理资源,它通常只在WiFi才会使用。
原文地址: http://www.igvita.com/posa/high-performance-networking-in-google-chrome/














 1295
1295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









