







本篇博客主要归纳整理,CNN相关的基础知识和部分经典卷积神经网络的结构与特点。图片大部分来自Fei-Fei Li CNN课程PPT、网络和paper,如有侵犯请及时告知
CNN相关基础知识
卷积神经网络和全连接神经网络的区别
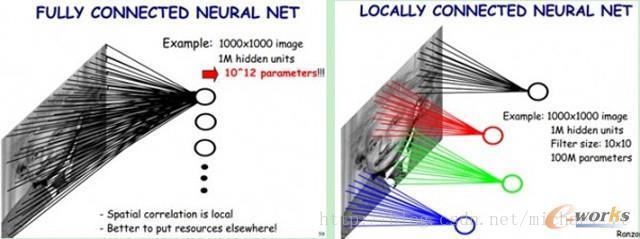
区别:如上图所示,
1. 全连接神经网络中每个神经元或者filter都与输入图像的每个像素相关联,参数量大
2. 卷积神经网络中每个神经元或者filter只与原图中部分像素相关联,即只关心局部信息,参数量小
卷积核
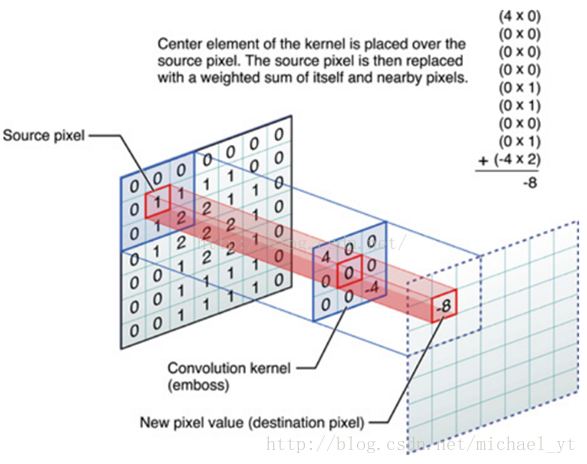
如图所示,一个3*3的卷积核对原图的一个3*3区域(这个区域也叫做卷积核的感受野)做卷积,其具体的计算过程是对应元素相乘再相加。
卷积过程
整体过程
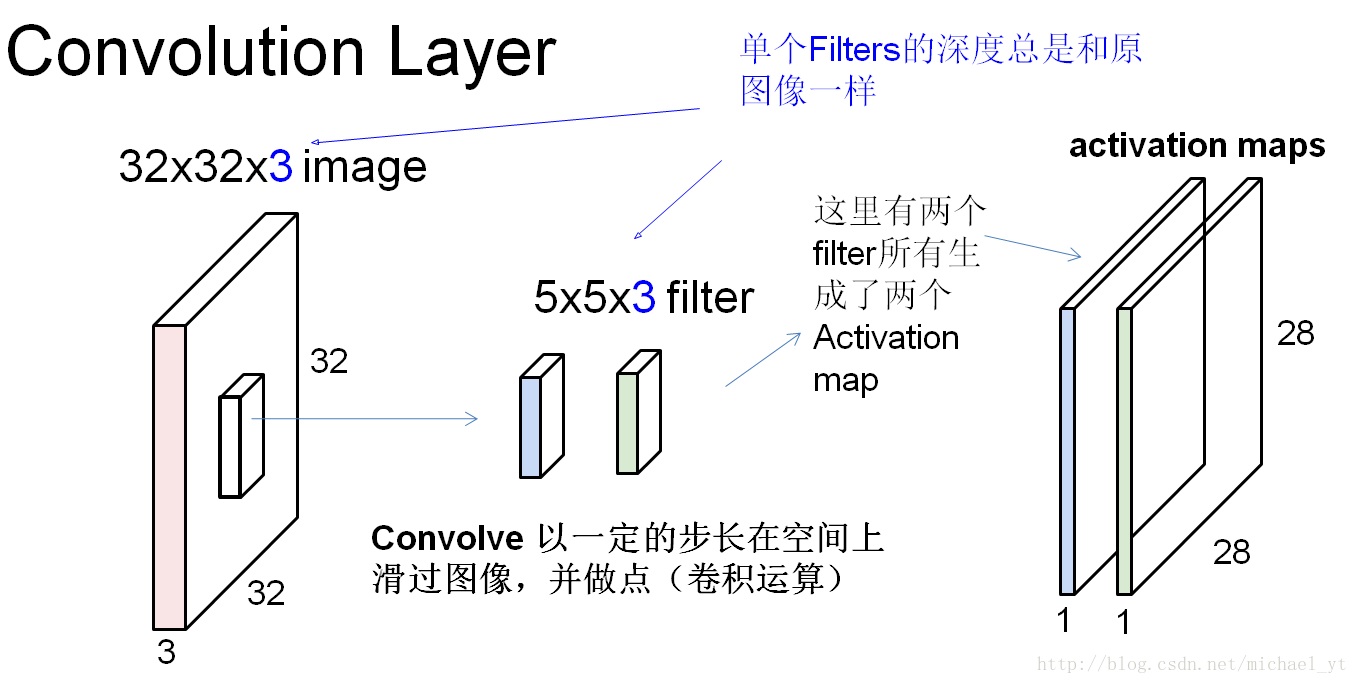
如上图:
- filter从左上角开始以设定的步长移动至右下角,每次移动都会通过点积(卷积)得到一个数值
- 单个filter的深度总是和原图像的通道数一样
- filter的个数决定了生成activation map的个数,一个activation map 代表原图像中某个feature(特征)
- 单个filter的权值是共享的
计算过程
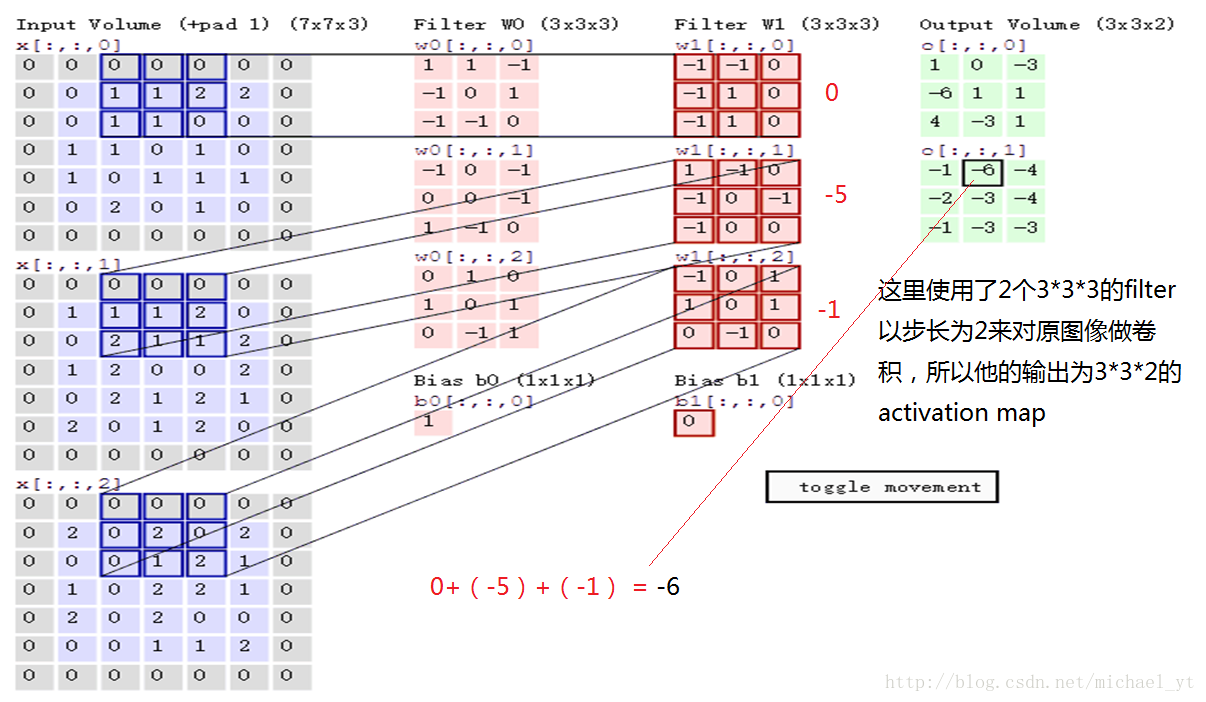
如上图:
- Filter w0 和原图像以步长为2做卷积后,会得到Output Volume 中的第一个3*3的 feature(activation) map
- 单个filter的三个通道做完卷积后会做线性相加,并加上一个偏置项bias,从而得出feature map中的某个数值
feature map大小计算
上图中一个7*7的原图经过3*3的filter以步长为2来做卷积后,为什么输出也是一个3*3的数组呢?
不使用padding 0 填充:
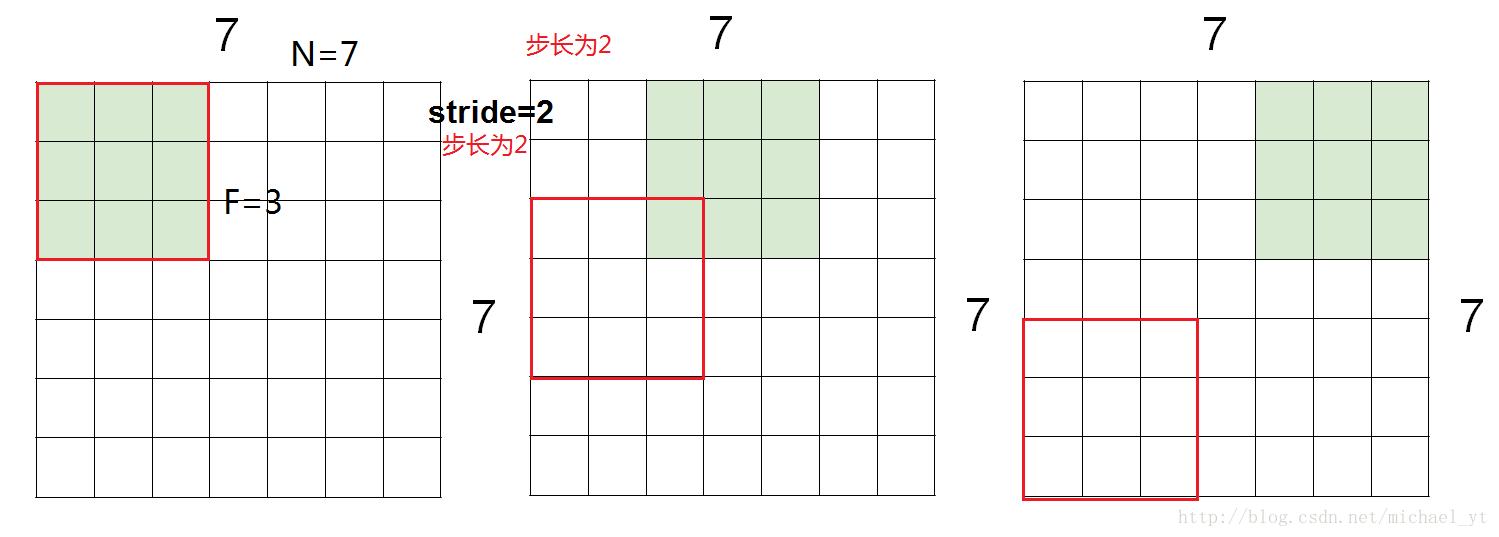
如图所示,每个卷积可以得到一个值,以步长为2,卷积核在原图横向和纵向上都可以卷积三次,所以最后输出的矩阵为3*3,不使用0填充计算输出矩阵的长宽的公式为:Output size = (N - F) / stride + 1
使用padding:
根据上图我们可以发现,如果我们不停的层层卷积下去,那么原来尺寸很大的图片到最后会变得很小,甚至成为一个像素点,在一些想输出图片的应用上这个是我们不想看到的结果,所以我们怎么保证即做卷积运算还不改变输出尺寸呢?
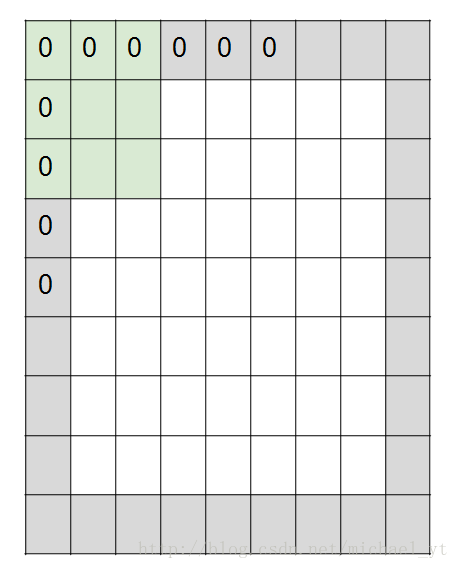
如图所示,我们将原来7*7的图片长宽个加上0填充,这个时候我们使用3*3的filter以步长为1来对原图做卷积,那么它的输出还是 7*7的feature map,计算 padding 的公式为:P = ( F - stride ) / 2 有 padding 输出矩阵长宽公式为:Output size = (N - F + 2P) / stride + 1
激活函数
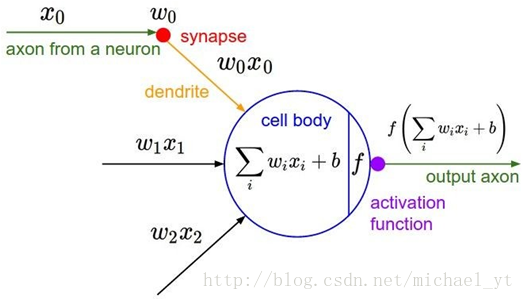
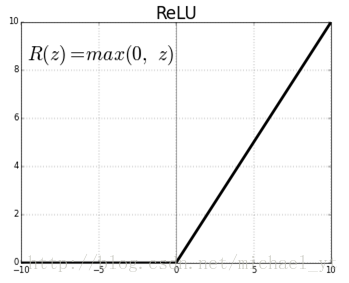
如上图所示,一个filter或者神经元的内部计算过程,我们可以看到通过卷积并加上bias后(其实在感知机那个时代到这一步就可以了,模型就具备了线性分类的能力,但是大千世界我们的分类问题很少是线性函数可以拟合的,所以我们就需要拟合非线性函数),filter还做了一次函数映射运算,这里的函数 f 就是我们的非线性激活函数,它的作用是:使模型不再是线性组合,具有可以逼近任意函数的能力。下图就是我们经常使用激活函数 ReLU,还有sigmoid函数或者tanh函数这些,读者可以自行搜索。
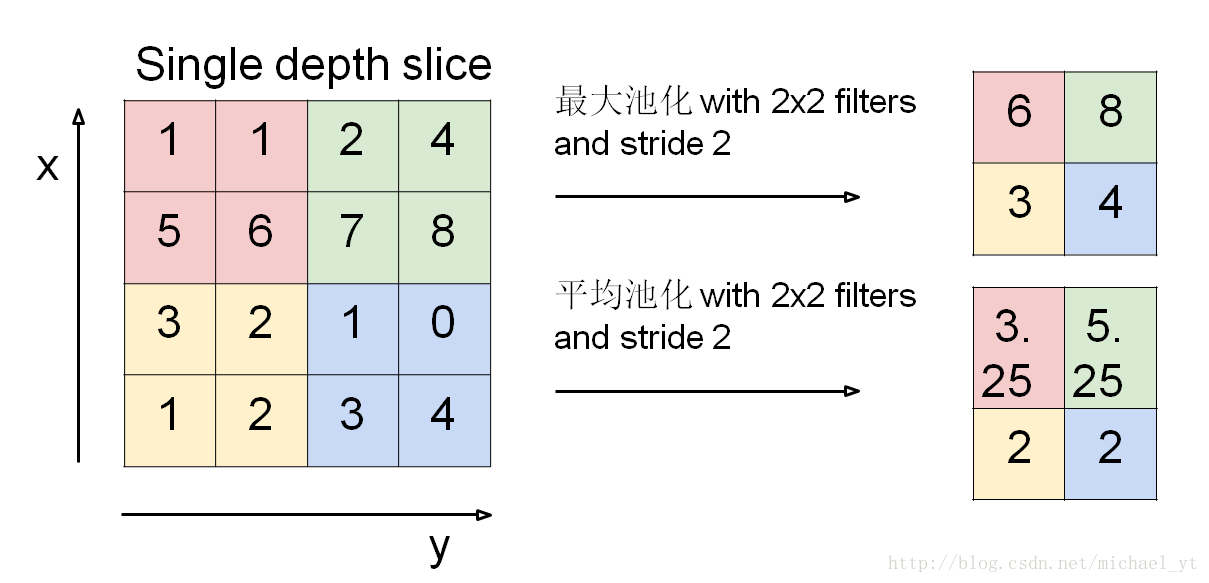
池化过程
池化的作用和特点:
- 降维,减少网络的参数,达到防止过拟合的效果
- 可以实现平移、旋转的不变性
- 只改变图像尺寸,不改变图像深度
- 没有需要训练的参数
- 计算公式为:Output size = (N - F) / stride + 1
以上我们了解了 卷积神经网络 – 卷积核 – 卷积过程 – 池化过程,下面我们就来了解一些经典的卷积神经网络。
经典卷积神经网络
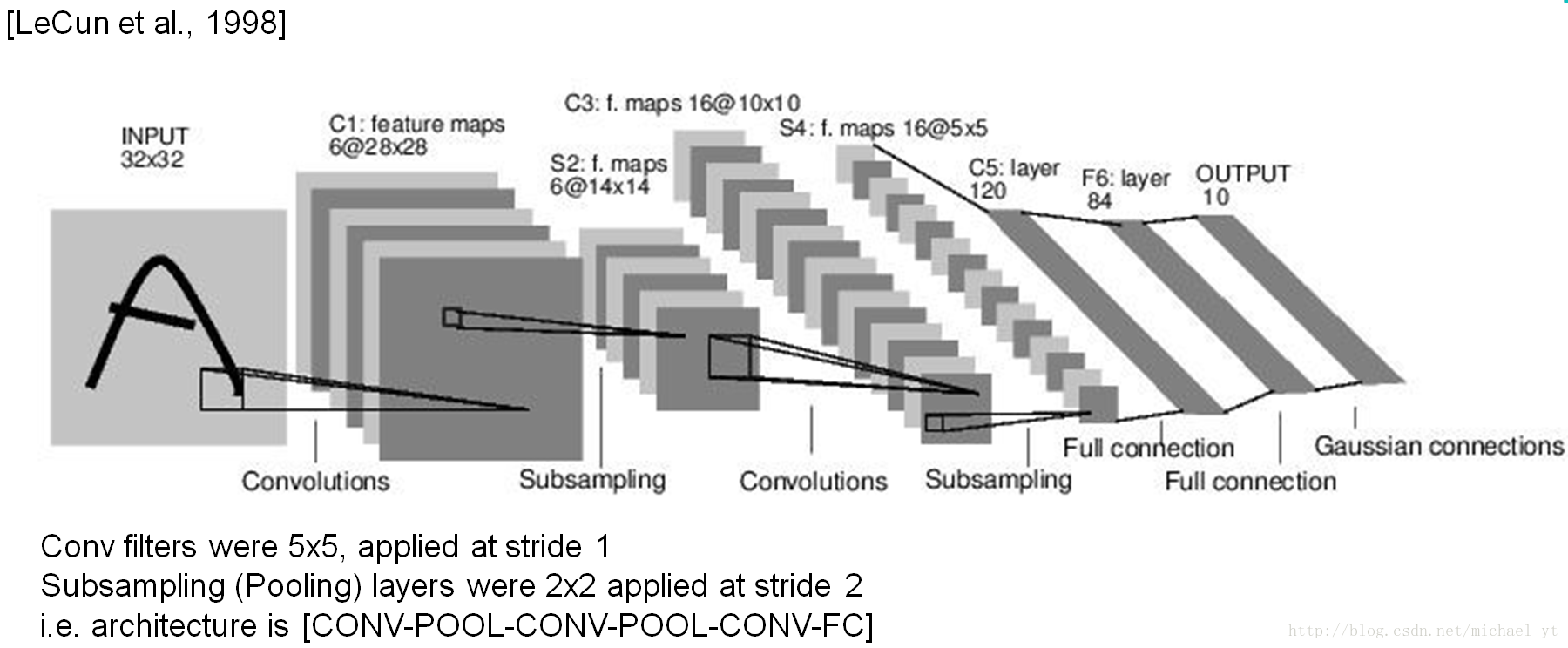
LeNet-5
论文名字:Gradient-Based Learning Applied to Document Recognition
论文地址:
chrome-extension://ikhdkkncnoglghljlkmcimlnlhkeamad/pdf-viewer/web/viewer.html?file=http%3A%2F%2Fwww.dengfanxin.cn%2Fwp-content%2Fuploads%2F2016%2F03%2F1998Lecun.pdf
特点:
- 奠定了现代卷积神经网络的基石
- 不是使用独立像素直接作为输入,使用卷积包含了图像的空间相关性(多个像素共同作用)
- 每个卷积层包含三个部分:卷积、池化和非线性激活函数
- 使用卷积提取空间特征
- 降采样的平均池化层
- 双曲正切(Tanh)或S型(Sigmoid)的激活函数
- MLP(多层感知机,全连接输出)作为最后的分类器
- 层与层之间的稀疏连接减少计算复杂度
AlexNet

论文名字:ImageNet Classification with Deep Convolutional Neural Networks
论文地址:
chrome-extension://ikhdkkncnoglghljlkmcimlnlhkeamad/pdf-viewer/web/viewer.html?file=http%3A%2F%2Fpapers.nips.cc%2Fpaper%2F4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
特点:
- ILSVRC 2012 第一名
- 成功使用Relu作为CNN的激活函数,比sigmoid好:①计算量小,sigmoid涉及指数运算、②不容易出现梯度消失,sigmoid在两头梯度接近于0、③缓解过拟合,会使部分神经元输出为0
- 训练时使用使用dropout避免过拟合
- 使用最大池化,避免平均池化的模糊效果,并让步长比池化核的尺寸小,提升特征丰富性
- 提出了LRN(Local Response Normalization)层,即局部响应归一化层,对局部神经元响应较大的值变得更大并抑制反馈较小的神经元,增强了模型的泛化能力(后面的网络不怎么会使用了,因为效果不明显并且有其它更好的方法)
- 使用CUDA(Compute Unified Device Architecture)通用并行计算架构,加速深度卷积网络的训练
- 数据增强:随机重256的原始图像上截取224大小并水平翻转,预测时取图片四个角加中间共五个位置并左右翻转,共进行10次预测求均值
- 因为当时计算速度的限制,如图,这里有两个分支,即使用了两块GPU同时计算
名词解释:
- SGD:stochastic gradient descent,即随机梯度下降
- Momentum:即动量,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向
- L2:正则化方法
- TOP5:从一千类里面找出5五个最后可能的分类结果,其中你五个判定结果都不对的概率
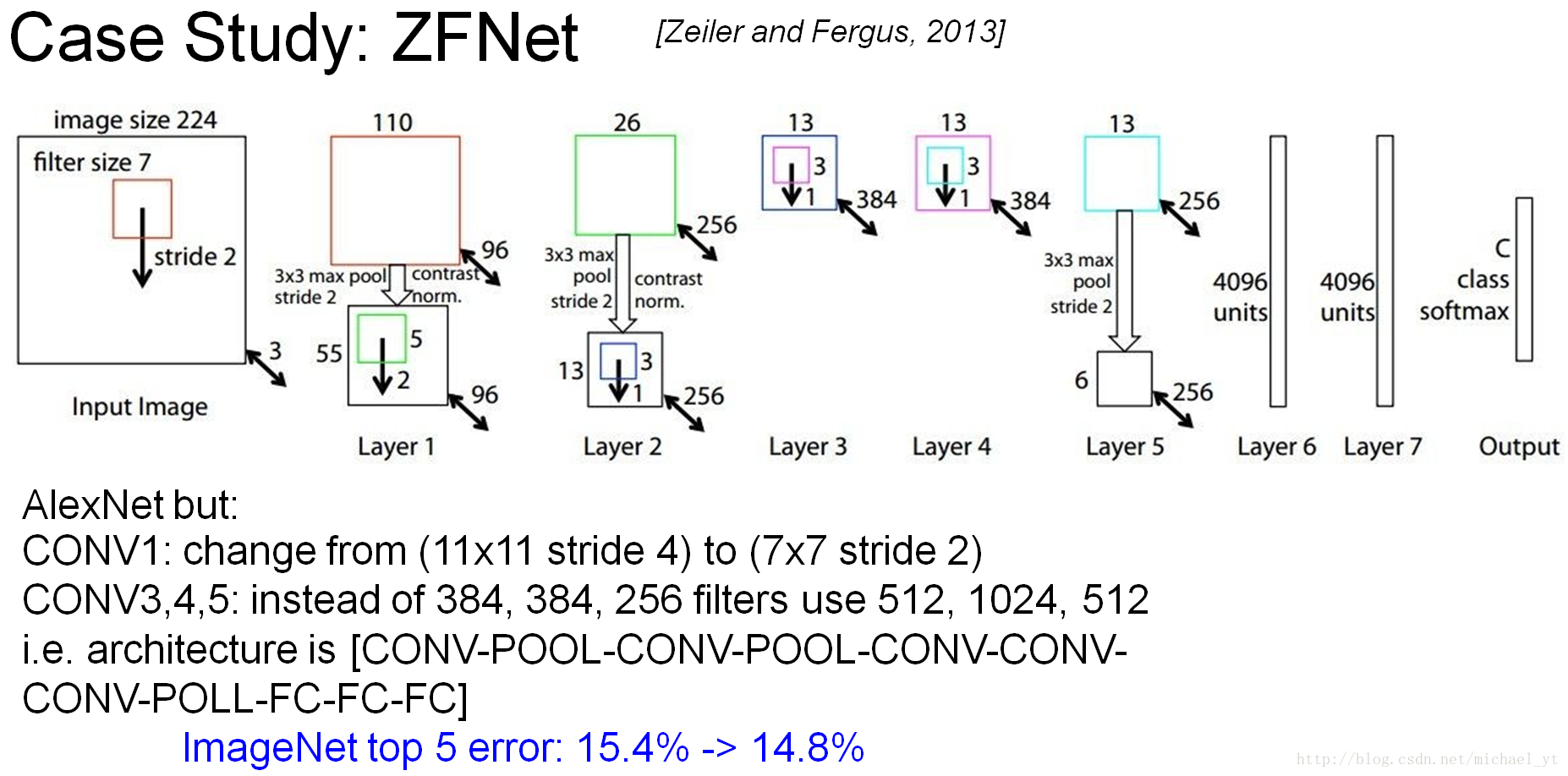
ZFNet
论文名字:Visualizing and Understanding Convolutional Neural Networks
论文地址:
chrome-extension://ikhdkkncnoglghljlkmcimlnlhkeamad/pdf-viewer/web/viewer.html?file=https%3A%2F%2Farxiv.org%2Fpdf%2F1311.2901.pdf
特点:
- ILSVRC 2013 第一名
- 大量阐述了卷积神经网络的直观概念,以及可视化操作的方法值得借鉴
- 基于AlexNet的优化
VGGNet

论文名字:Very Deep Convolutional Networks for Large-Scale Image Recognition
论文地址:
chrome-extension://ikhdkkncnoglghljlkmcimlnlhkeamad/pdf-viewer/web/viewer.html?file=https%3A%2F%2Farxiv.org%2Fpdf%2F1409.1556.pdf
特点:
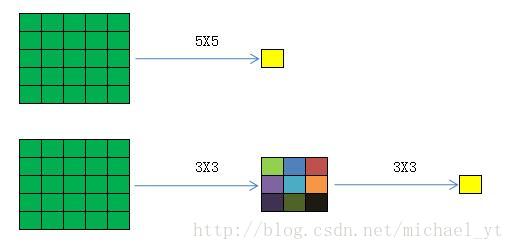
- 只使用了3*3的小型卷积核以及2*2的最大池化层,结构简洁
- 得出了LRN层作用不大
- 得出了越深的网络效果越好
- 1*1的卷积也是很有效的,但是没有3*3的卷积好,大一些的卷积可以学习更大的空间特征
- 2个串联的3*3卷积的感受野和一个5*5的感受野一样,并且拥有比一个5*5的卷积层更多的非线性变换(前者使用了二次ReLU激活函数)
- 得出了越深的网络效果越好
- ILSVRC 2014 第二名
GoogLeNet
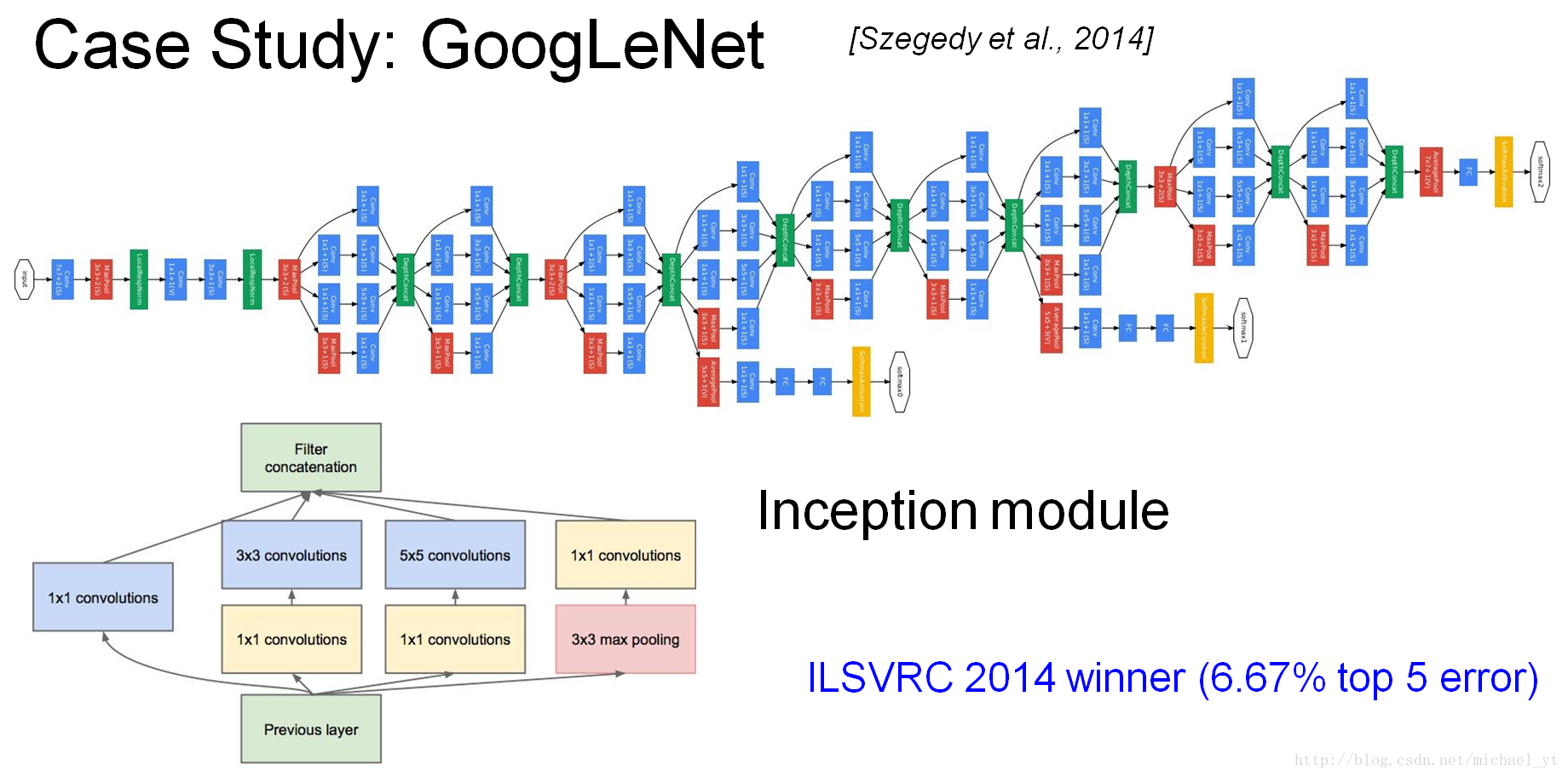
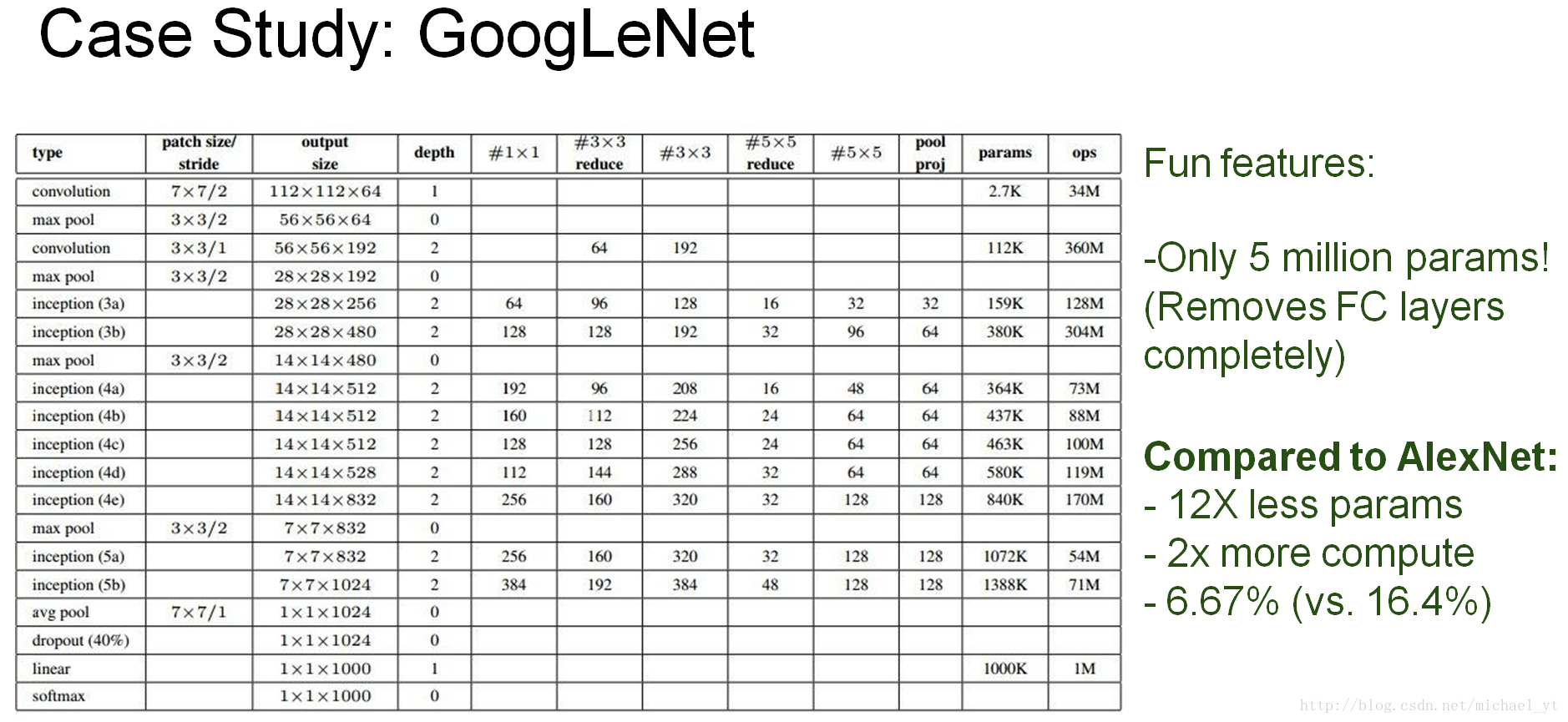
注,这里只是V1模型,Google Inception Net大家族里面还有其它的模型,比如:V2、V3、V4等,读者可以自行了解
论文名字:Going deeper with convolutions
论文地址:
chrome-extension://ikhdkkncnoglghljlkmcimlnlhkeamad/pdf-viewer/web/viewer.html?file=https%3A%2F%2Farxiv.org%2Fpdf%2F1409.4842.pdf
特点:
- 控制了计算量和参数量的同时,获得了非常好的分类性能
- 除去了最后的全连接层,使用全局平均池化层,减少了参数量减轻了过拟合,并且一个通道就代表一个类型的特征
- Inception module模型的精心设计,本身就是一个小网络而且具有分支提高了网络的宽度,通过叠加可以构建一个大网络
- 使用中间层输出分类并加到最终分类结果中,相当于做了模型融合,增加了反向传播的梯度信号,也提供了额外正则化,预测前向传播的时候会将其抛弃
- 大量是用了1*1的卷积核,使用很小的计算量就能增加一层特征变化和非线性化
- ILSVRC 2014 第一名
1*1卷积的好处:
1.实现跨通道特征信息的整合
2.可以对输出通道升维和降维 (3*3、5*5都涵盖了局部信息所以不能像 1*1 一样只考虑通道信息来升降维度,卷积核的深度适合原图像保持一致的,升降维是体现在卷积核的个数上面)
ResNet
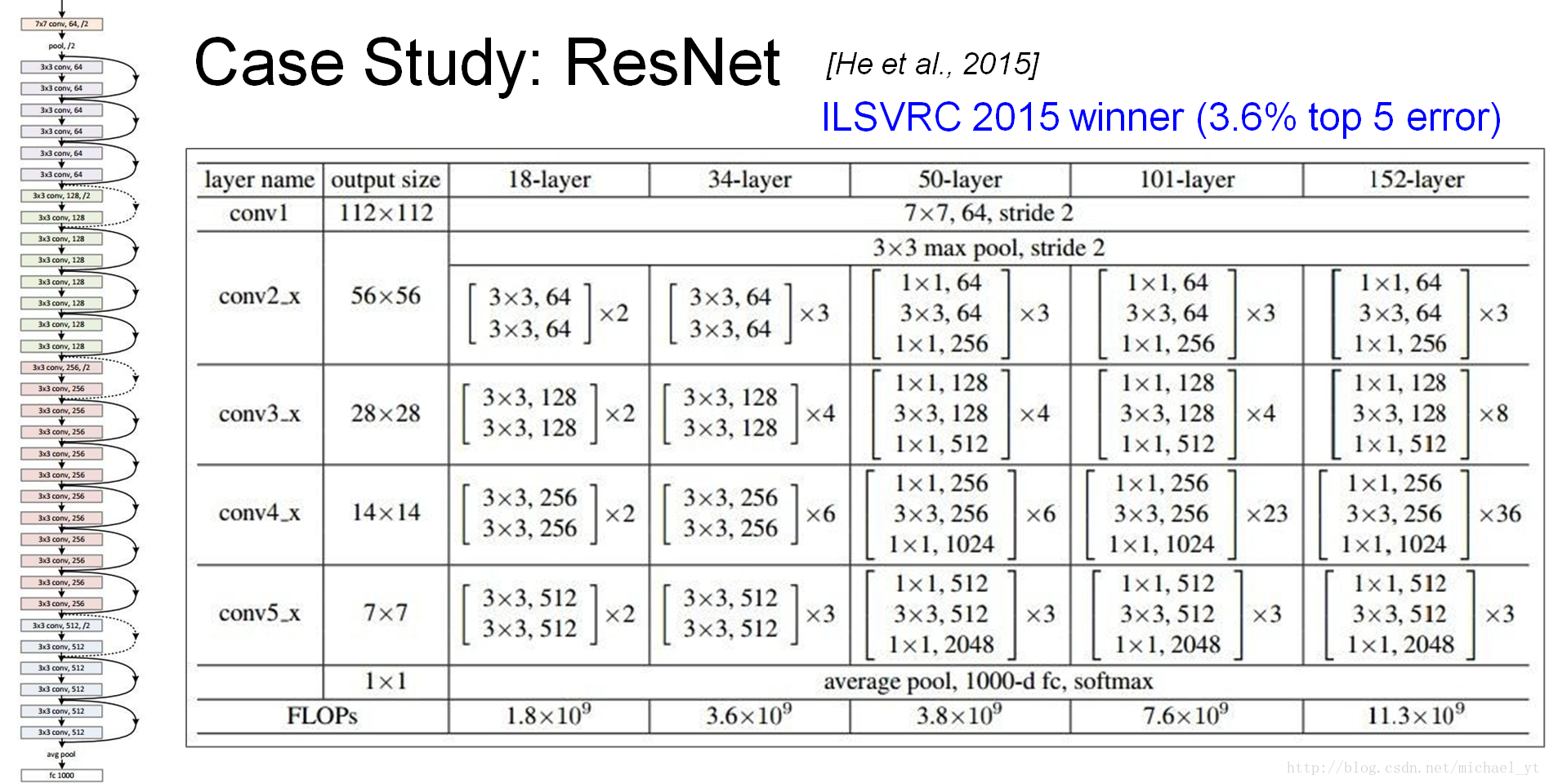
注,人类的top5为5.1%单从这方面考虑它已超越人类
论文名字:Going deeper with convolutions
论文地址:
chrome-extension://ikhdkkncnoglghljlkmcimlnlhkeamad/pdf-viewer/web/viewer.html?file=https%3A%2F%2Farxiv.org%2Fpdf%2F1409.4842.pdf
提出原因
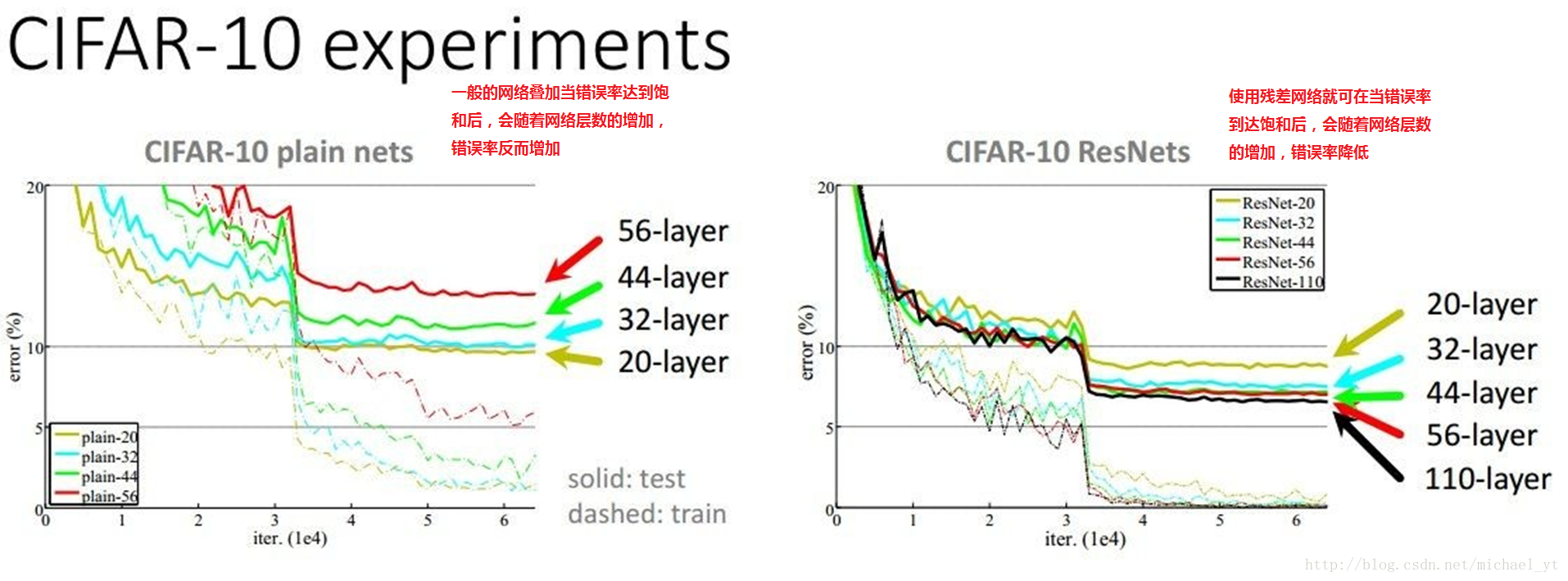
提出的思想
- resnet最初的想法是在训练集上,深层网络不应该比浅层网络差,因为只需要深层网络多的那些层做恒等映射就简化为了浅层网络。所以从学习恒等映射这点出发,考虑到网络要学习一个F(x)=x的映射比学习F(x)=0的映射更难,所以可以把网络结构设计成H(x)= F(x) + x,这样就即完成了恒等映射的学习,又降低了学习难度。这里的x是残差结构的输入,F是该层网络学习的映射,H是整个残差结构的输出。 – 知乎回答
- 网络解释:其实就是将输入x传到输出作为初始结果,那么我们需要学习的目标就是F(x) = H(x) – x ,
H(x)是期望输出,F(x)是学习的映射函数,即学习他们之间的差比学习整个内容容易
基本网络结构
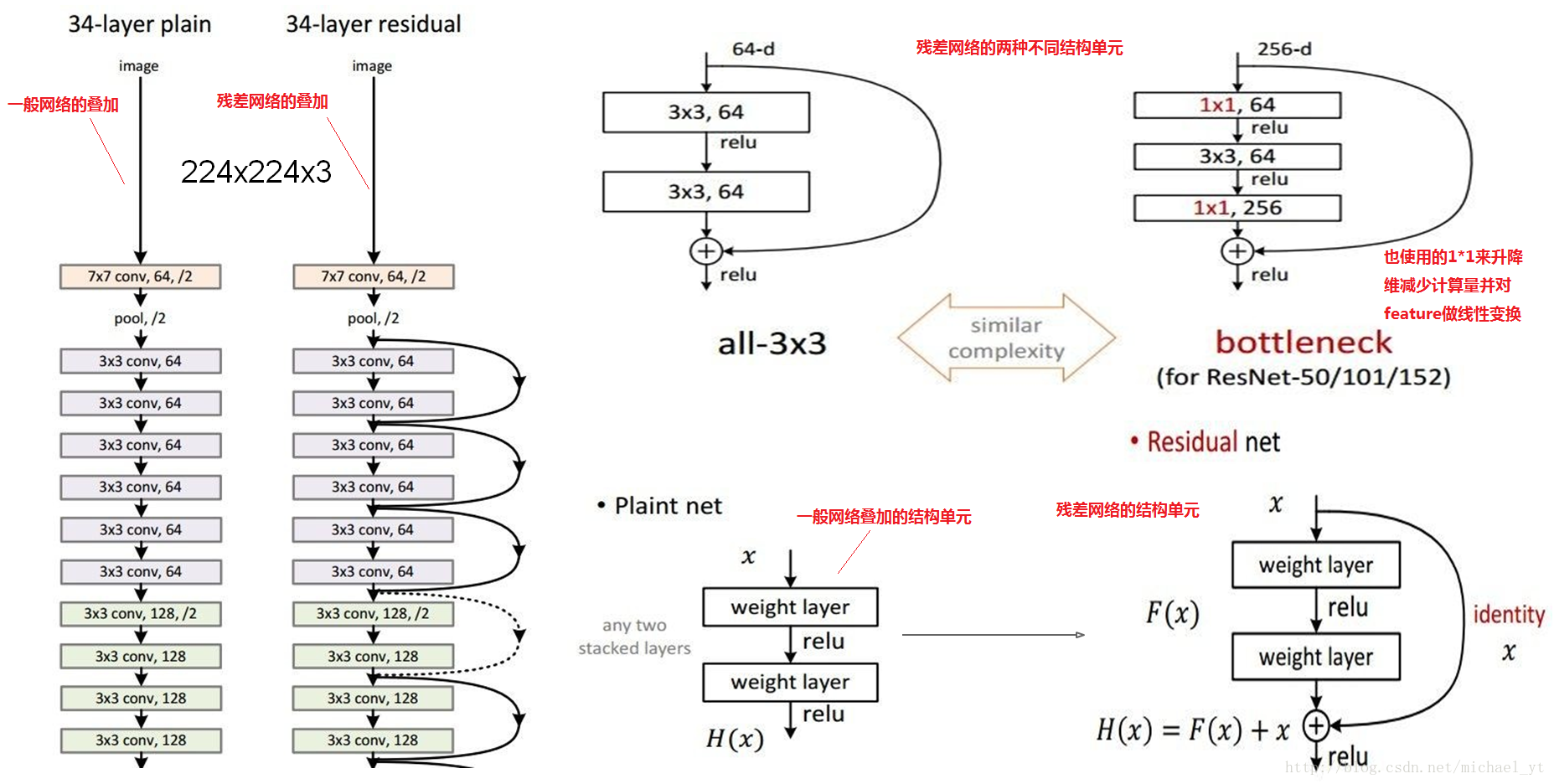
特点:
- 每个CNN层都使用了Batch Normalization :对每个mini-batch数据的内部进行标准化处理,使输出规范化到0-1的正太分布,某种意义上起到了正则化的作用,所以可以减少或者取消dropout并学习率可以设置大一点
- 使用了xavier算法,通过输入和输出神经元的数目自动确定权值矩阵的初始化大小。
- Residual Networks are Exponential Ensembles of Relatively Shallow Networks 论文指出,这个网络其实就是由多个浅层网络叠加而且并不是真正意义上的极深网络,并没有解决梯度消失问题而是规避了
- ILSVRC 2015 第一名
参考:《TensorFlow实战》 – 黄文坚 唐源 、Fei-Fei Li CNN课程PPT、网络相关paper














 944
944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









