







ziplist结构在redis运用非常广泛,是列表、字典等数据类型的底层结构之一。ziplist的优点在于能够一定程度地节约内存。
ziplist构成
ziplist结构由zip_header、zip_entry、zip_end三部分组成。

ZIP_HEADER:顾名思义,压缩列表的头部。内部包含ZIP_BYTES、ZIP_TAIL、ZIP_LENGTH属性。
– ZIP_BYTES:ziplist占用的总字节数,uint32_t型;
– ZIP_TAIL:最后一个节点的偏移量,uint32_t型;
– ZIP_LENGTH:ziplist的长度,uint16_t型;
由此,我们可计算出ZIP_HEADER所占用的字节数:4(ZIP_BYTES)+4(ZIP_TAIL)+2(ZIP_LENGTH)=10.
ZIP_ENTRY : ziplist的节点信息, 节点(entry)结构定义位于ziplist.c。
typedef struct zlentry {
//prevrawlensize: 前节点长度所占的字节数
//prevrawlen: 前节点的长度
unsigned int prevrawlensize, prevrawlen;
//lensize: 当前节点的长度所占字节数
//len: 当前节点长度
unsigned int lensize, len;
//entry: header大小
unsigned int headersize;
//当前节点编码
unsigned char encoding;
//指向当前节点的指针
unsigned char *p;
} zlentry;上面各属性的注释已经说明其代表的含义。可以看出zlentry的属性还是比较多的。实际上,ziplist在存储节点信息时,并没有将zlentry数据结构所有属性保存,而是做了简化。

prevlen:前节点的长度。
| prevlen | 字节数 | 结构 |
|---|---|---|
| 小于254 | 1 | xxxxxxxx |
| 大于或等于254 | 5 | 11111110 xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx |
encoding & length : 节点的编码和长度。
节点的编码保存在第一个字节,当字节以“11”开头时,表示节点存储的数据为整型,其他情况视为字符串类型。
由于整型的长度是固定的,因此 只需存储encoding信息,length值可根据编码进行计算得出。
| encoding | 占用字节 | 存储结构 | 取值范围 |
|---|---|---|---|
| ZIP_INT_XX | 1字节 | 11110001~11111101 | 0~12 |
| ZIP_INT_8B | 1字节 | 11111110 | -2^8~2^8-1 |
| ZIP_INT_16B | 2字节 | 11000000 | -2^16~2^16-1 |
| ZIP_INT_24B | 3字节 | 11110000 | -2^24~2^24-1 |
| ZIP_INT_32B | 4字节 | 11010000 | -2^32~2^32-1 |
| ZIP_INT_64B | 8字节 | 11100000 | -2^64~2^64-1 |
与整型数据相比,字符串的设计相对复杂些。尤其是字符串的长度(length)取值,设计得非常灵活、巧妙。
| encoding | 占用字节 | 存储结构 | 字符串范围 | length取值 |
|---|---|---|---|---|
| ZIP_STR_06B | 1字节 | 00XXXXXX | 长度<64 | 后6位 |
| ZIP_STR_14B | 2字节 | 01XXXXXX XXXXXXXX | 长度<16384 | 后14位 |
| ZIP_STR_32B | 5字节 | 10000000 XXXXXXXX XXXXXXXX XXXXXXXX XXXXXXXX | 长度<2^32-1 | 32位 |
ZIP_END:ziplist的结束标识,ZIP_END=255。
ziplist核心函数
ziplistNew: 创建一个ziplist
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
unsigned char *ziplistNew(void) {
unsigned int bytes = ZIPLIST_HEADER_SIZE+1;
//为zl分配空间
unsigned char *zl = zmalloc(bytes);
//初始化bytes值
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
//初始化tail_offset信息
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
//初始化zl_length信息
ZIPLIST_LENGTH(zl) = 0;
//将结束标识添加至尾部
zl[bytes-1] = ZIP_END;
return zl;
}__ziplistInsert : 在指定的节点后,新增一个节点。供ziplistPush和ziplistInsert等函数内部调用。
static unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
......
//计算s的长度
if (zipTryEncoding(s,slen,&value,&encoding)) {
reqlen = zipIntSize(encoding);
} else {
reqlen = slen;
}
//前节点长度所占用的字节数
//prevlen:p前置节点的长度
reqlen += zipPrevEncodeLength(NULL,prevlen);
//新节点的编码及长度所占用的字节数
reqlen += zipEncodeLength(NULL,encoding,slen);
//计算p前节点与新节点长度所占用的字节数之差
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
//重置ziplist的大小
offset = p-zl;
zl = ziplistResize(zl,curlen+reqlen+nextdiff);
p = zl+offset;
if (p[0] != ZIP_END) {
//为新节点腾出空间,向后整体移动
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
//将新节点的长度编码至后置节点
//p+reqlen: 定位到后置节点
zipPrevEncodeLength(p+reqlen,reqlen);
// 更新到达表尾的偏移量
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
zipEntry(p+reqlen, &tail);
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
//新旧节点长度所占用的字节数不一致时,则更新后面节点的信息
if (nextdiff != 0) {
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
//记录前节点的长度
p += zipPrevEncodeLength(p,prevlen);
//记录节点的编码及长度信息
p += zipEncodeLength(p,encoding,slen);
if (ZIP_IS_STR(encoding)) {
//保存字符串数据
memcpy(p,s,slen);
} else {
//保存整型数据
zipSaveInteger(p,value,encoding);
}
//链表长度+1
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}__ziplistInsert函数的代码较多,下面给出一个简单的流程图:
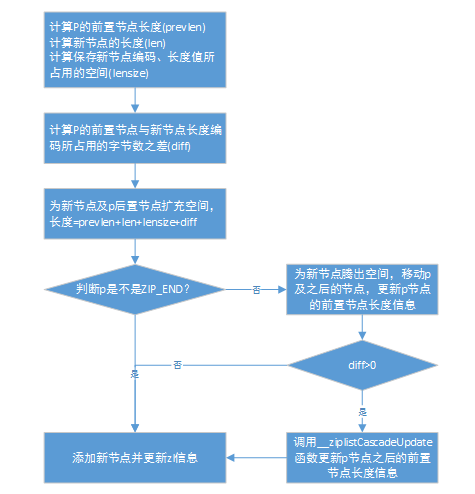
与__ziplistInsert相左,ziplistDelete提供删除节点功能,实现比较简单,这里就不贴代码了。值得注意的是,与新增节点一样,删除节点时也需要更新p之后的节点前置节点长度信息
ziplist还有一个比较特别的函数:ziplistLen,用于计算ziplist的长度,前面有提到ziplist使用2个字节来保存长度信息,当ziplist长度超出2个字节所能表示的范围时,ziplist是怎么存储的?长度又该如何计算呢?
//计算ziplist的长度
unsigned int ziplistLen(unsigned char *zl) {
unsigned int len = 0;
//当 ZIPLIST_LENGTH(zl)<65535 时,则返回其值
if (intrev16ifbe(ZIPLIST_LENGTH(zl)) < UINT16_MAX) {
len = intrev16ifbe(ZIPLIST_LENGTH(zl));
} else {
//当ZIPLIST_LENGTH(zl)=65535 时,需要遍历整个链表,计算其长度
unsigned char *p = zl+ZIPLIST_HEADER_SIZE;
while (*p != ZIP_END) {
p += zipRawEntryLength(p);
len++;
}
/* Re-store length if small enough */
//如果长度小于65535时,更新ziplist的ZIPLIST_LENGTH值
if (len < UINT16_MAX) ZIPLIST_LENGTH(zl) = intrev16ifbe(len);
}
return len;
}ziplist还提供了一些方法,由于篇幅关系,这里就不一一介绍。有兴趣的童鞋可以了解下。
| 方法名 | 功能 |
|---|---|
| ziplistMerge | 合并两个压缩链表 |
| ziplistPush | 向表头/尾添加一个节点 |
| ziplistIndex | 查找第N个节点 |
| ziplistNext | 查找指定节点的后置节点 |
| ziplistPrev | 查找指定节点的前置节点 |
| ziplistGet | 获取指定节点的信息 |
| ziplistInsert | 在指定的节点后新增节点 |
| ziplistDelete | 删除节点 |
| ziplistDeleteRange | 从指定的下标开始,删除N个节点 |
| ziplistCompare | 比较两个节点值 |
| ziplistFind | 查找节点 |
| ziplistBlobLen | 获取链表所占用字节数 |
ziplist连锁更新
前面简单地介绍ziplist的节点构成及几个核心函数。我们知道ziplist的insert和delete节点时,系统会自动更新指定节点之后其他节点的前置节点长度信息。
当某个字符串节点的前置节点长度<254时,使用一个字节进行存储,当前置节点长度>=254,则使用5个字节。试想一下,当将一个长度>=254的节点添加到一段连续的“长度在250~253”节点之前时,此时,插入位置之后的所有节点的前置节点长度信息都将面临更新。这就是所谓的“连锁更新”现象。
下面用实例简单说明下。
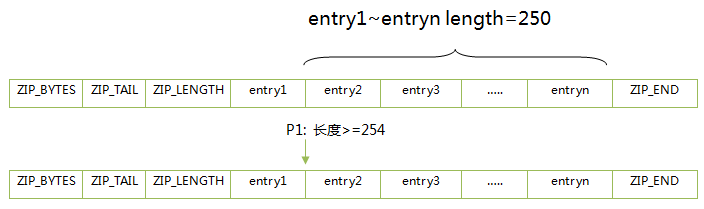
1).当在entry1前插入p1时,entry1前置节点发生变化。由于P1的长度>=254,那么系统需要为entry1分配5个字节用于存储前置节点长度信息。此时, entry1长度由250变为250+5 = 255个字节。

2). 由于entry1长度发生变化(250->255),entry2之前使用一个字节存储entry1长度信息,现在无法容纳新的长度数据,需要系统扩充4个字节的容量进行存储。

3). 依此类推,直到entryn节点更新完成后停止。
总结
ziplist由header、entry、end三部分组成。支持从表头至表尾(ZIP_HEADER)和表尾至表头(ZIP_TAIL)遍历.
ziplist的长度:当zip_length<65535时,zip_length代表ziplist长度。当zip_length=65535时,需遍历整个ziplist进行计算得出。
由于ziplist每个节点保留“前节点的长度”信息,当发生insert、delete等操作时,系统会更新指定节点之后的其他节点的“前节点长度”属性。
虽然ziplist的“连锁更新”现象发生几率较小,但在使用的过程应尽量规避。















 75
75

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









