







学习爬虫有段日子了,一般的静态页面是比较简单的,但要是遇到了JS加载或者框架之类的就歇菜了,所以根据技能路线,正式开启动态页面的抓取路线学习
PhantomJS
1.PhantomJS是什么?
PhantomJS is a headless WebKit scriptable with a JavaScript API.
PhantomJS是一个可编程的无头浏览器.
无头浏览器:一个完整的浏览器内核,包括js解析引擎,渲染引擎,请求处理等,但是不包括显示和用户交互页面的浏览器。
2.PhantomJS的使用场景
PhantomJS的适用范围就是无头浏览器的适用范围。通常无头浏览器可以用于页面自动化,网页监控,网络爬虫等:
页面自动化测试:希望自动的登陆网站并做一些操作然后检查结果是否正常。
网页监控:希望定期打开页面,检查网站是否能正常加载,加载结果是否符合预期。加载速度如何等。
网络爬虫:获取页面中使用js来下载和渲染信息,或者是获取链接处使用js来跳转后的真实地址。
开始下载地址:http://phantomjs.org/download.html
一、windows版本:
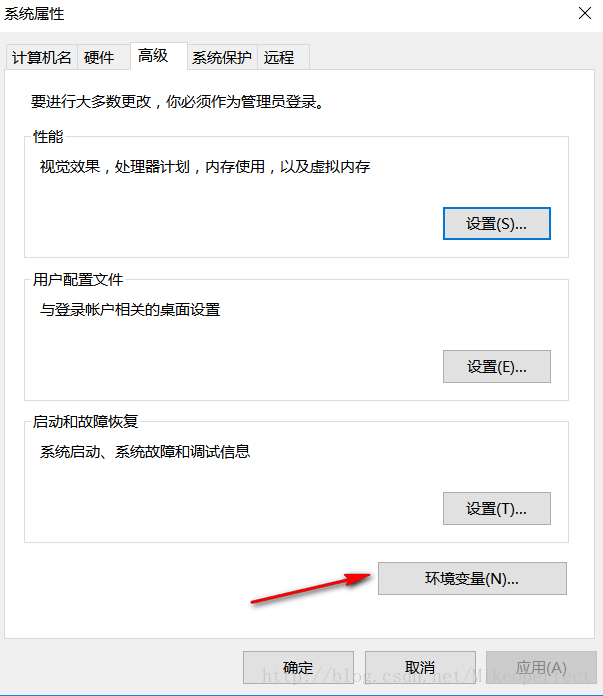
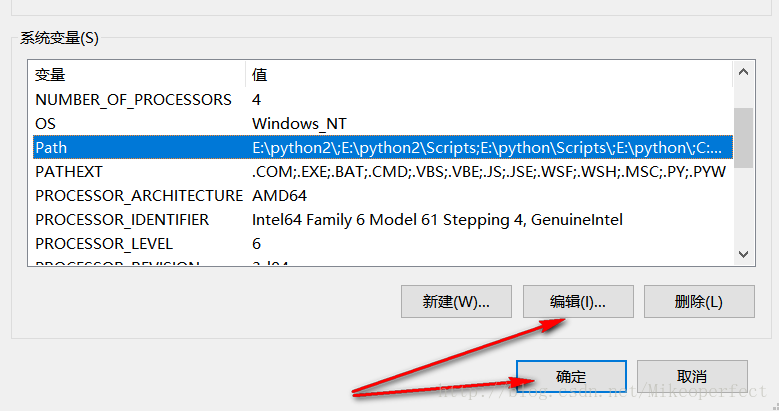
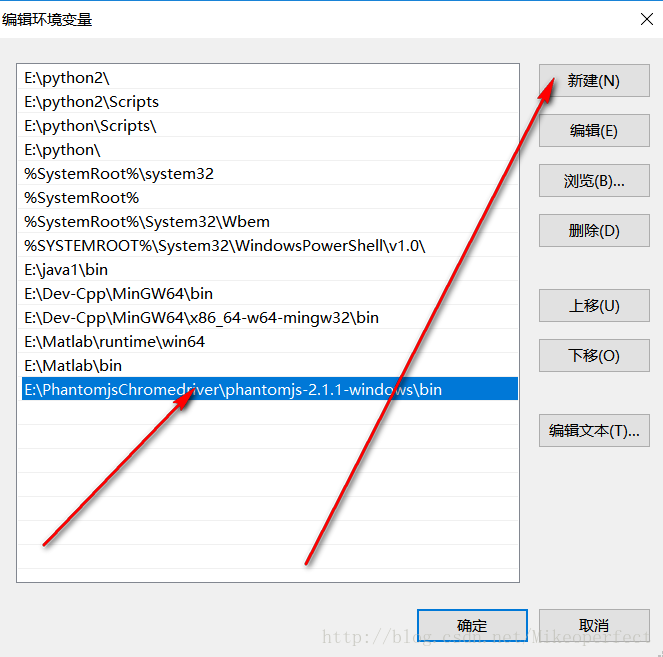
下载后直接解压,然后转到环境变量(记住是系统中的path变量)的配置中进行配置。(这样就可以直接在cmd下输入phantomjs运行了)
path配置说明:
验证是否成功,CMD下输入phantomjs:

Windows版本的phantomjs就安装好了。
二、Ubuntu版本下载:
# 下载好后进行解压(由于是bz2格式,要先进行bzip2解压成tar格式,再使用tar解压)
bzip2 -d phantomjs-2.1.1-linux-x86_64.tar.bz2
# 再使用tar进行解压到/usr/local/目录下边
tar xvf phantomjs-2.1.1-linux-x86_64.tar -C /usr/local/
# 安装依赖软件
yum -y install wget fontconfig
# 重命名(方便以后使用phantomjs命令)
mv /usr/local/phantomjs-2.1.1-linux-x86_64/ /usr/local/phantomjs
# 最后一步就是建立软连接了(在/usr/bin/目录下生产一个phantomjs的软连接,/usr/bin/是啥目录应该清楚,不清楚使用 echo $PATH查看)
ln -s /usr/local/phantomjs/bin/phantomjs /usr/bin/经过上面建立的软连接,你就可以使用了,而且是像使用系统命令一样的进行使用
[root@localhost ~]# phantomjs
phantomjs> Ubuntu版本的phantomjs就安装好了,开始测试!
# 建立一个新文件 并写入: console.log('Hello world!) phantom.exit();
[root@localhost roottest]# gedit test.js
# 查看一下
[root@localhost roottest]# cat test.js
console.log('Hello world!');
phantom.exit(); //这一行表示退出命令行
# 执行一下试试(OK了)
[root@localhost roottest]# phantomjs test.js
Hello world!按 Ctrl + c 组合键退出或者 phantom.exit();即可退出phantomjs命令行了
三、使用PhantomJS
网址1:http://javascript.ruanyifeng.com/tool/phantomjs.html
网址2(官网):http://phantomjs.org/api/webpage/
编写js脚本(保存为test.js):
var page = require('webpage').create();
page.open('http://www.baidu.com', function () {
page.render('baidu.png');
phantom.exit();
}); 执行phantomjs test.js
可得文件,baidu.png


小结
本次认真的学习了phantomjs的用法,对于需要动态爬取网页的需求迈出了坚实的第一步,接下来就是开始配合selenium爬取动态网页了















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









