







注:本文源码是JDK8的版本,与之前的版本有较大差异
ConcurrentHashMap是conccurrent家族中的一个类,由于它可以高效地支持并发操作,以及被广泛使用,经典的开源框架spring的底层数据结构就是使用ConcurrentHashMap实现的。与同是线程安全的老大哥HashTable相比,它已经更胜一筹,因此它的锁更加细化,而不是像HashTable一样为几乎每个方法都添加了synchronized锁,这样的锁无疑会影响到性能。
本文的分析的源码是JDK8的版本,与JDK6的版本有很大的差异。实现线程安全的思想也已经完全变了,它摒弃了Segment(锁段)的概念,而是启用了一种全新的方式实现,利用CAS算法。它沿用了与它同时期的HashMap版本的思想,底层依然由“数组”+链表+红黑树的方式思想,但是为了做到并发,又增加了很多辅助的类,例如TreeBin,Traverser等对象内部类。
1 重要的属性
首先来看几个重要的属性,与HashMap相同的就不再介绍了,这里重点解释一下sizeCtl这个属性。可以说它是ConcurrentHashMap中出镜率很高的一个属性,因为它是一个控制标识符,在不同的地方有不同用途,而且它的取值不同,也代表不同的含义。
- 负数代表正在进行初始化或扩容操作
- -1代表正在初始化
- -N 表示有N-1个线程正在进行扩容操作
- 正数或0代表hash表还没有被初始化,这个数值表示初始化或下一次进行扩容的大小,这一点类似于扩容阈值的概念。还后面可以看到,它的值始终是当前ConcurrentHashMap容量的0.75倍,这与loadfactor是对应的。
- /**
- * 盛装Node元素的数组 它的大小是2的整数次幂
- * Size is always a power of two. Accessed directly by iterators.
- */
- transient volatile Node<K,V>[] table;
- /**
- * Table initialization and resizing control. When negative, the
- * table is being initialized or resized: -1 for initialization,
- * else -(1 + the number of active resizing threads). Otherwise,
- * when table is null, holds the initial table size to use upon
- * creation, or 0 for default. After initialization, holds the
- * next element count value upon which to resize the table.
- hash表初始化或扩容时的一个控制位标识量。
- 负数代表正在进行初始化或扩容操作
- -1代表正在初始化
- -N 表示有N-1个线程正在进行扩容操作
- 正数或0代表hash表还没有被初始化,这个数值表示初始化或下一次进行扩容的大小
- */
- private transient volatile int sizeCtl;
- // 以下两个是用来控制扩容的时候 单线程进入的变量
- /**
- * The number of bits used for generation stamp in sizeCtl.
- * Must be at least 6 for 32bit arrays.
- */
- private static int RESIZE_STAMP_BITS = 16;
- /**
- * The bit shift for recording size stamp in sizeCtl.
- */
- private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
- /*
- * Encodings for Node hash fields. See above for explanation.
- */
- static final int MOVED = -1; // hash值是-1,表示这是一个forwardNode节点
- static final int TREEBIN = -2; // hash值是-2 表示这时一个TreeBin节点
2 重要的内部类
2.1 Node
Node是最核心的内部类,它包装了key-value键值对,所有插入ConcurrentHashMap的数据都包装在这里面。它与HashMap中的定义很相似,但是但是有一些差别它对value和next属性设置了volatile同步锁,它不允许调用setValue方法直接改变Node的value域,它增加了find方法辅助map.get()方法。
- static class Node<K,V> implements Map.Entry<K,V> {
- final int hash;
- final K key;
- volatile V val;//带有同步锁的value
- volatile Node<K,V> next;//带有同步锁的next指针
- Node(int hash, K key, V val, Node<K,V> next) {
- this.hash = hash;
- this.key = key;
- this.val = val;
- this.next = next;
- }
- public final K getKey() { return key; }
- public final V getValue() { return val; }
- public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
- public final String toString(){ return key + "=" + val; }
- //不允许直接改变value的值
- public final V setValue(V value) {
- throw new UnsupportedOperationException();
- }
- public final boolean equals(Object o) {
- Object k, v, u; Map.Entry<?,?> e;
- return ((o instanceof Map.Entry) &&
- (k = (e = (Map.Entry<?,?>)o).getKey()) != null &&
- (v = e.getValue()) != null &&
- (k == key || k.equals(key)) &&
- (v == (u = val) || v.equals(u)));
- }
- /**
- * Virtualized support for map.get(); overridden in subclasses.
- */
- Node<K,V> find(int h, Object k) {
- Node<K,V> e = this;
- if (k != null) {
- do {
- K ek;
- if (e.hash == h &&
- ((ek = e.key) == k || (ek != null && k.equals(ek))))
- return e;
- } while ((e = e.next) != null);
- }
- return null;
- }
- }
- 这个Node内部类与HashMap中定义的Node类很相似,但是有一些差别
- 它对value和next属性设置了volatile同步锁
- 它不允许调用setValue方法直接改变Node的value域
- 它增加了find方法辅助map.get()方法
2.2 TreeNode
树节点类,另外一个核心的数据结构。当链表长度过长的时候,会转换为TreeNode。但是与HashMap不相同的是,它并不是直接转换为红黑树,而是把这些结点包装成TreeNode放在TreeBin对象中,由TreeBin完成对红黑树的包装。而且TreeNode在ConcurrentHashMap集成自Node类,而并非HashMap中的集成自LinkedHashMap.Entry<K,V>类,也就是说TreeNode带有next指针,这样做的目的是方便基于TreeBin的访问。
2.3 TreeBin
这个类并不负责包装用户的key、value信息,而是包装的很多TreeNode节点。它代替了TreeNode的根节点,也就是说在实际的ConcurrentHashMap“数组”中,存放的是TreeBin对象,而不是TreeNode对象,这是与HashMap的区别。另外这个类还带有了读写锁。
这里仅贴出它的构造方法。可以看到在构造TreeBin节点时,仅仅指定了它的hash值为TREEBIN常量,这也就是个标识为。同时也看到我们熟悉的红黑树构造方法
- /**
- * Creates bin with initial set of nodes headed by b.
- */
- TreeBin(TreeNode<K,V> b) {
- super(TREEBIN, null, null, null);
- this.first = b;
- TreeNode<K,V> r = null;
- for (TreeNode<K,V> x = b, next; x != null; x = next) {
- next = (TreeNode<K,V>)x.next;
- x.left = x.right = null;
- if (r == null) {
- x.parent = null;
- x.red = false;
- r = x;
- }
- else {
- K k = x.key;
- int h = x.hash;
- Class<?> kc = null;
- for (TreeNode<K,V> p = r;;) {
- int dir, ph;
- K pk = p.key;
- if ((ph = p.hash) > h)
- dir = -1;
- else if (ph < h)
- dir = 1;
- else if ((kc == null &&
- (kc = comparableClassFor(k)) == null) ||
- (dir = compareComparables(kc, k, pk)) == 0)
- dir = tieBreakOrder(k, pk);
- TreeNode<K,V> xp = p;
- if ((p = (dir <= 0) ? p.left : p.right) == null) {
- x.parent = xp;
- if (dir <= 0)
- xp.left = x;
- else
- xp.right = x;
- r = balanceInsertion(r, x);
- break;
- }
- }
- }
- }
- this.root = r;
- assert checkInvariants(root);
- }
2.5 ForwardingNode
一个用于连接两个table的节点类。它包含一个nextTable指针,用于指向下一张表。而且这个节点的key value next指针全部为null,它的hash值为-1. 这里面定义的find的方法是从nextTable里进行查询节点,而不是以自身为头节点进行查找
- /**
- * A node inserted at head of bins during transfer operations.
- */
- static final class ForwardingNode<K,V> extends Node<K,V> {
- final Node<K,V>[] nextTable;
- ForwardingNode(Node<K,V>[] tab) {
- super(MOVED, null, null, null);
- this.nextTable = tab;
- }
- Node<K,V> find(int h, Object k) {
- // loop to avoid arbitrarily deep recursion on forwarding nodes
- outer: for (Node<K,V>[] tab = nextTable;;) {
- Node<K,V> e; int n;
- if (k == null || tab == null || (n = tab.length) == 0 ||
- (e = tabAt(tab, (n - 1) & h)) == null)
- return null;
- for (;;) {
- int eh; K ek;
- if ((eh = e.hash) == h &&
- ((ek = e.key) == k || (ek != null && k.equals(ek))))
- return e;
- if (eh < 0) {
- if (e instanceof ForwardingNode) {
- tab = ((ForwardingNode<K,V>)e).nextTable;
- continue outer;
- }
- else
- return e.find(h, k);
- }
- if ((e = e.next) == null)
- return null;
- }
- }
- }
- }
3 Unsafe与CAS
在ConcurrentHashMap中,随处可以看到U, 大量使用了U.compareAndSwapXXX的方法,这个方法是利用一个CAS算法实现无锁化的修改值的操作,他可以大大降低锁代理的性能消耗。这个算法的基本思想就是不断地去比较当前内存中的变量值与你指定的一个变量值是否相等,如果相等,则接受你指定的修改的值,否则拒绝你的操作。因为当前线程中的值已经不是最新的值,你的修改很可能会覆盖掉其他线程修改的结果。这一点与乐观锁,SVN的思想是比较类似的。
3.1 unsafe静态块
unsafe代码块控制了一些属性的修改工作,比如最常用的SIZECTL 。 在这一版本的concurrentHashMap中,大量应用来的CAS方法进行变量、属性的修改工作。 利用CAS进行无锁操作,可以大大提高性能。
- private static final sun.misc.Unsafe U;
- private static final long SIZECTL;
- private static final long TRANSFERINDEX;
- private static final long BASECOUNT;
- private static final long CELLSBUSY;
- private static final long CELLVALUE;
- private static final long ABASE;
- private static final int ASHIFT;
- static {
- try {
- U = sun.misc.Unsafe.getUnsafe();
- Class<?> k = ConcurrentHashMap.class;
- SIZECTL = U.objectFieldOffset
- (k.getDeclaredField("sizeCtl"));
- TRANSFERINDEX = U.objectFieldOffset
- (k.getDeclaredField("transferIndex"));
- BASECOUNT = U.objectFieldOffset
- (k.getDeclaredField("baseCount"));
- CELLSBUSY = U.objectFieldOffset
- (k.getDeclaredField("cellsBusy"));
- Class<?> ck = CounterCell.class;
- CELLVALUE = U.objectFieldOffset
- (ck.getDeclaredField("value"));
- Class<?> ak = Node[].class;
- ABASE = U.arrayBaseOffset(ak);
- int scale = U.arrayIndexScale(ak);
- if ((scale & (scale - 1)) != 0)
- throw new Error("data type scale not a power of two");
- ASHIFT = 31 - Integer.numberOfLeadingZeros(scale);
- } catch (Exception e) {
- throw new Error(e);
- }
- }
3.2 三个核心方法
ConcurrentHashMap定义了三个原子操作,用于对指定位置的节点进行操作。正是这些原子操作保证了ConcurrentHashMap的线程安全。
- @SuppressWarnings("unchecked")
- //获得在i位置上的Node节点
- static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
- return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
- }
- //利用CAS算法设置i位置上的Node节点。之所以能实现并发是因为他指定了原来这个节点的值是多少
- //在CAS算法中,会比较内存中的值与你指定的这个值是否相等,如果相等才接受你的修改,否则拒绝你的修改
- //因此当前线程中的值并不是最新的值,这种修改可能会覆盖掉其他线程的修改结果 有点类似于SVN
- static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
- Node<K,V> c, Node<K,V> v) {
- return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
- }
- //利用volatile方法设置节点位置的值
- static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
- U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
- }
4 初始化方法initTable
对于ConcurrentHashMap来说,调用它的构造方法仅仅是设置了一些参数而已。而整个table的初始化是在向ConcurrentHashMap中插入元素的时候发生的。如调用put、computeIfAbsent、compute、merge等方法的时候,调用时机是检查table==null。
初始化方法主要应用了关键属性sizeCtl 如果这个值〈0,表示其他线程正在进行初始化,就放弃这个操作。在这也可以看出ConcurrentHashMap的初始化只能由一个线程完成。如果获得了初始化权限,就用CAS方法将sizeCtl置为-1,防止其他线程进入。初始化数组后,将sizeCtl的值改为0.75*n
- /**
- * Initializes table, using the size recorded in sizeCtl.
- */
- private final Node<K,V>[] initTable() {
- Node<K,V>[] tab; int sc;
- while ((tab = table) == null || tab.length == 0) {
- //sizeCtl表示有其他线程正在进行初始化操作,把线程挂起。对于table的初始化工作,只能有一个线程在进行。
- if ((sc = sizeCtl) < 0)
- Thread.yield(); // lost initialization race; just spin
- else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {//利用CAS方法把sizectl的值置为-1 表示本线程正在进行初始化
- try {
- if ((tab = table) == null || tab.length == 0) {
- int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
- @SuppressWarnings("unchecked")
- Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
- table = tab = nt;
- sc = n - (n >>> 2);//相当于0.75*n 设置一个扩容的阈值
- }
- } finally {
- sizeCtl = sc;
- }
- break;
- }
- }
- return tab;
- }
5 扩容方法 transfer
当ConcurrentHashMap容量不足的时候,需要对table进行扩容。这个方法的基本思想跟HashMap是很像的,但是由于它是支持并发扩容的,所以要复杂的多。原因是它支持多线程进行扩容操作,而并没有加锁。我想这样做的目的不仅仅是为了满足concurrent的要求,而是希望利用并发处理去减少扩容带来的时间影响。因为在扩容的时候,总是会涉及到从一个“数组”到另一个“数组”拷贝的操作,如果这个操作能够并发进行,那真真是极好的了。
整个扩容操作分为两个部分-
第一部分是构建一个nextTable,它的容量是原来的两倍,这个操作是单线程完成的。这个单线程的保证是通过RESIZE_STAMP_SHIFT这个常量经过一次运算来保证的,这个地方在后面会有提到;
- 第二个部分就是将原来table中的元素复制到nextTable中,这里允许多线程进行操作。
先来看一下单线程是如何完成的:
它的大体思想就是遍历、复制的过程。首先根据运算得到需要遍历的次数i,然后利用tabAt方法获得i位置的元素:
-
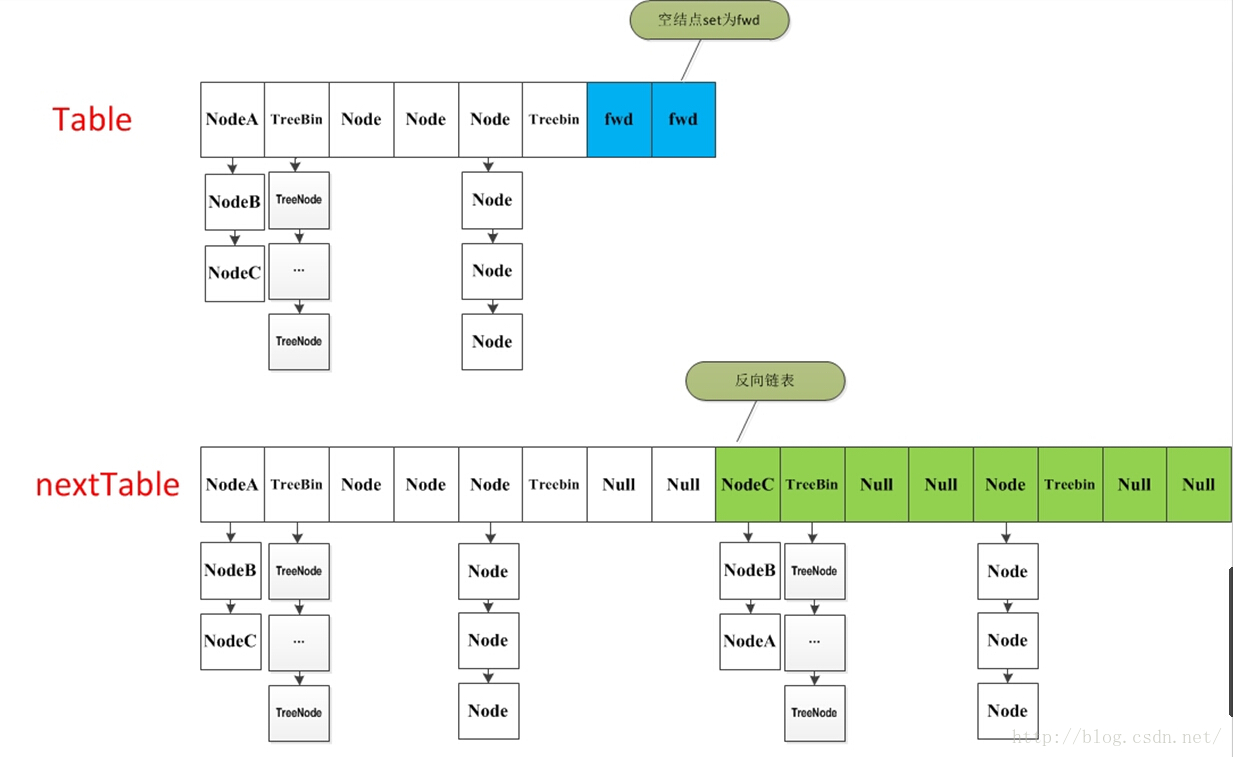
如果这个位置为空,就在原table中的i位置放入forwardNode节点,这个也是触发并发扩容的关键点;
-
如果这个位置是Node节点(fh>=0),如果它是一个链表的头节点,就构造一个反序链表,把他们分别放在nextTable的i和i+n的位置上
-
如果这个位置是TreeBin节点(fh<0),也做一个反序处理,并且判断是否需要untreefi,把处理的结果分别放在nextTable的i和i+n的位置上
- 遍历过所有的节点以后就完成了复制工作,这时让nextTable作为新的table,并且更新sizeCtl为新容量的0.75倍 ,完成扩容。
在代码的69行有一个判断,如果遍历到的节点是forward节点,就向后继续遍历,再加上给节点上锁的机制,就完成了多线程的控制。多线程遍历节点,处理了一个节点,就把对应点的值set为forward,另一个线程看到forward,就向后遍历。这样交叉就完成了复制工作。而且还很好的解决了线程安全的问题。 这个方法的设计实在是让我膜拜。
- /**
- * 一个过渡的table表 只有在扩容的时候才会使用
- */
- private transient volatile Node<K,V>[] nextTable;
- /**
- * Moves and/or copies the nodes in each bin to new table. See
- * above for explanation.
- */
- private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
- int n = tab.length, stride;
- if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
- stride = MIN_TRANSFER_STRIDE; // subdivide range
- if (nextTab == null) { // initiating
- try {
- @SuppressWarnings("unchecked")
- Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];//构造一个nextTable对象 它的容量是原来的两倍
- nextTab = nt;
- } catch (Throwable ex) { // try to cope with OOME
- sizeCtl = Integer.MAX_VALUE;
- return;
- }
- nextTable = nextTab;
- transferIndex = n;
- }
- int nextn = nextTab.length;
- ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);//构造一个连节点指针 用于标志位
- boolean advance = true;//并发扩容的关键属性 如果等于true 说明这个节点已经处理过
- boolean finishing = false; // to ensure sweep before committing nextTab
- for (int i = 0, bound = 0;;) {
- Node<K,V> f; int fh;
- //这个while循环体的作用就是在控制i-- 通过i--可以依次遍历原hash表中的节点
- while (advance) {
- int nextIndex, nextBound;
- if (--i >= bound || finishing)
- advance = false;
- else if ((nextIndex = transferIndex) <= 0) {
- i = -1;
- advance = false;
- }
- else if (U.compareAndSwapInt
- (this, TRANSFERINDEX, nextIndex,
- nextBound = (nextIndex > stride ?
- nextIndex - stride : 0))) {
- bound = nextBound;
- i = nextIndex - 1;
- advance = false;
- }
- }
- if (i < 0 || i >= n || i + n >= nextn) {
- int sc;
- if (finishing) {
- //如果所有的节点都已经完成复制工作 就把nextTable赋值给table 清空临时对象nextTable
- nextTable = null;
- table = nextTab;
- sizeCtl = (n << 1) - (n >>> 1);//扩容阈值设置为原来容量的1.5倍 依然相当于现在容量的0.75倍
- return;
- }
- //利用CAS方法更新这个扩容阈值,在这里面sizectl值减一,说明新加入一个线程参与到扩容操作
- if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
- if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
- return;
- finishing = advance = true;
- i = n; // recheck before commit
- }
- }
- //如果遍历到的节点为空 则放入ForwardingNode指针
- else if ((f = tabAt(tab, i)) == null)
- advance = casTabAt(tab, i, null, fwd);
- //如果遍历到ForwardingNode节点 说明这个点已经被处理过了 直接跳过 这里是控制并发扩容的核心
- else if ((fh = f.hash) == MOVED)
- advance = true; // already processed
- else {
- //节点上锁
- synchronized (f) {
- if (tabAt(tab, i) == f) {
- Node<K,V> ln, hn;
- //如果fh>=0 证明这是一个Node节点
- if (fh >= 0) {
- int runBit = fh & n;
- //以下的部分在完成的工作是构造两个链表 一个是原链表 另一个是原链表的反序排列
- Node<K,V> lastRun = f;
- for (Node<K,V> p = f.next; p != null; p = p.next) {
- int b = p.hash & n;
- if (b != runBit) {
- runBit = b;
- lastRun = p;
- }
- }
- if (runBit == 0) {
- ln = lastRun;
- hn = null;
- }
- else {
- hn = lastRun;
- ln = null;
- }
- for (Node<K,V> p = f; p != lastRun; p = p.next) {
- int ph = p.hash; K pk = p.key; V pv = p.val;
- if ((ph & n) == 0)
- ln = new Node<K,V>(ph, pk, pv, ln);
- else
- hn = new Node<K,V>(ph, pk, pv, hn);
- }
- //在nextTable的i位置上插入一个链表
- setTabAt(nextTab, i, ln);
- //在nextTable的i+n的位置上插入另一个链表
- setTabAt(nextTab, i + n, hn);
- //在table的i位置上插入forwardNode节点 表示已经处理过该节点
- setTabAt(tab, i, fwd);
- //设置advance为true 返回到上面的while循环中 就可以执行i--操作
- advance = true;
- }
- //对TreeBin对象进行处理 与上面的过程类似
- else if (f instanceof TreeBin) {
- TreeBin<K,V> t = (TreeBin<K,V>)f;
- TreeNode<K,V> lo = null, loTail = null;
- TreeNode<K,V> hi = null, hiTail = null;
- int lc = 0, hc = 0;
- //构造正序和反序两个链表
- for (Node<K,V> e = t.first; e != null; e = e.next) {
- int h = e.hash;
- TreeNode<K,V> p = new TreeNode<K,V>
- (h, e.key, e.val, null, null);
- if ((h & n) == 0) {
- if ((p.prev = loTail) == null)
- lo = p;
- else
- loTail.next = p;
- loTail = p;
- ++lc;
- }
- else {
- if ((p.prev = hiTail) == null)
- hi = p;
- else
- hiTail.next = p;
- hiTail = p;
- ++hc;
- }
- }
- //如果扩容后已经不再需要tree的结构 反向转换为链表结构
- ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
- (hc != 0) ? new TreeBin<K,V>(lo) : t;
- hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
- (lc != 0) ? new TreeBin<K,V>(hi) : t;
- //在nextTable的i位置上插入一个链表
- setTabAt(nextTab, i, ln);
- //在nextTable的i+n的位置上插入另一个链表
- setTabAt(nextTab, i + n, hn);
- //在table的i位置上插入forwardNode节点 表示已经处理过该节点
- setTabAt(tab, i, fwd);
- //设置advance为true 返回到上面的while循环中 就可以执行i--操作
- advance = true;
- }
- }
- }
- }
- }
- }
6 Put方法
前面的所有的介绍其实都为这个方法做铺垫。ConcurrentHashMap最常用的就是put和get两个方法。现在来介绍put方法,这个put方法依然沿用HashMap的put方法的思想,根据hash值计算这个新插入的点在table中的位置i,如果i位置是空的,直接放进去,否则进行判断,如果i位置是树节点,按照树的方式插入新的节点,否则把i插入到链表的末尾。ConcurrentHashMap中依然沿用这个思想,有一个最重要的不同点就是ConcurrentHashMap不允许key或value为null值。另外由于涉及到多线程,put方法就要复杂一点。在多线程中可能有以下两个情况
-
如果一个或多个线程正在对ConcurrentHashMap进行扩容操作,当前线程也要进入扩容的操作中。这个扩容的操作之所以能被检测到,是因为transfer方法中在空结点上插入forward节点,如果检测到需要插入的位置被forward节点占有,就帮助进行扩容;
-
如果检测到要插入的节点是非空且不是forward节点,就对这个节点加锁,这样就保证了线程安全。尽管这个有一些影响效率,但是还是会比hashTable的synchronized要好得多。
整体流程就是首先定义不允许key或value为null的情况放入 对于每一个放入的值,首先利用spread方法对key的hashcode进行一次hash计算,由此来确定这个值在table中的位置。
如果这个位置是空的,那么直接放入,而且不需要加锁操作。
如果这个位置存在结点,说明发生了hash碰撞,首先判断这个节点的类型。如果是链表节点(fh>0),则得到的结点就是hash值相同的节点组成的链表的头节点。需要依次向后遍历确定这个新加入的值所在位置。如果遇到hash值与key值都与新加入节点是一致的情况,则只需要更新value值即可。否则依次向后遍历,直到链表尾插入这个结点。 如果加入这个节点以后链表长度大于8,就把这个链表转换成红黑树。如果这个节点的类型已经是树节点的话,直接调用树节点的插入方法进行插入新的值。- public V put(K key, V value) {
- return putVal(key, value, false);
- }
- /** Implementation for put and putIfAbsent */
- final V putVal(K key, V value, boolean onlyIfAbsent) {
- //不允许 key或value为null
- if (key == null || value == null) throw new NullPointerException();
- //计算hash值
- int hash = spread(key.hashCode());
- int binCount = 0;
- //死循环 何时插入成功 何时跳出
- for (Node<K,V>[] tab = table;;) {
- Node<K,V> f; int n, i, fh;
- //如果table为空的话,初始化table
- if (tab == null || (n = tab.length) == 0)
- tab = initTable();
- //根据hash值计算出在table里面的位置
- else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
- //如果这个位置没有值 ,直接放进去,不需要加锁
- if (casTabAt(tab, i, null,
- new Node<K,V>(hash, key, value, null)))
- break; // no lock when adding to empty bin
- }
- //当遇到表连接点时,需要进行整合表的操作
- else if ((fh = f.hash) == MOVED)
- tab = helpTransfer(tab, f);
- else {
- V oldVal = null;
- //结点上锁 这里的结点可以理解为hash值相同组成的链表的头结点
- synchronized (f) {
- if (tabAt(tab, i) == f) {
- //fh〉0 说明这个节点是一个链表的节点 不是树的节点
- if (fh >= 0) {
- binCount = 1;
- //在这里遍历链表所有的结点
- for (Node<K,V> e = f;; ++binCount) {
- K ek;
- //如果hash值和key值相同 则修改对应结点的value值
- if (e.hash == hash &&
- ((ek = e.key) == key ||
- (ek != null && key.equals(ek)))) {
- oldVal = e.val;
- if (!onlyIfAbsent)
- e.val = value;
- break;
- }
- Node<K,V> pred = e;
- //如果遍历到了最后一个结点,那么就证明新的节点需要插入 就把它插入在链表尾部
- if ((e = e.next) == null) {
- pred.next = new Node<K,V>(hash, key,
- value, null);
- break;
- }
- }
- }
- //如果这个节点是树节点,就按照树的方式插入值
- else if (f instanceof TreeBin) {
- Node<K,V> p;
- binCount = 2;
- if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
- value)) != null) {
- oldVal = p.val;
- if (!onlyIfAbsent)
- p.val = value;
- }
- }
- }
- }
- if (binCount != 0) {
- //如果链表长度已经达到临界值8 就需要把链表转换为树结构
- if (binCount >= TREEIFY_THRESHOLD)
- treeifyBin(tab, i);
- if (oldVal != null)
- return oldVal;
- break;
- }
- }
- }
- //将当前ConcurrentHashMap的元素数量+1
- addCount(1L, binCount);
- return null;
- }
6.1 helpTransfer方法
这是一个协助扩容的方法。这个方法被调用的时候,当前ConcurrentHashMap一定已经有了nextTable对象,首先拿到这个nextTable对象,调用transfer方法。回看上面的transfer方法可以看到,当本线程进入扩容方法的时候会直接进入复制阶段。
- /**
- * Helps transfer if a resize is in progress.
- */
- final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
- Node<K,V>[] nextTab; int sc;
- if (tab != null && (f instanceof ForwardingNode) &&
- (nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
- int rs = resizeStamp(tab.length);//计算一个操作校验码
- while (nextTab == nextTable && table == tab &&
- (sc = sizeCtl) < 0) {
- if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
- sc == rs + MAX_RESIZERS || transferIndex <= 0)
- break;
- if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
- transfer(tab, nextTab);
- break;
- }
- }
- return nextTab;
- }
- return table;
- }
6.2 treeifyBin方法
这个方法用于将过长的链表转换为TreeBin对象。但是他并不是直接转换,而是进行一次容量判断,如果容量没有达到转换的要求,直接进行扩容操作并返回;如果满足条件才链表的结构抓换为TreeBin ,这与HashMap不同的是,它并没有把TreeNode直接放入红黑树,而是利用了TreeBin这个小容器来封装所有的TreeNode.
- private final void treeifyBin(Node<K,V>[] tab, int index) {
- Node<K,V> b; int n, sc;
- if (tab != null) {
- if ((n = tab.length) < MIN_TREEIFY_CAPACITY)//如果table.length<64 就扩大一倍 返回
- tryPresize(n << 1);
- else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
- synchronized (b) {
- if (tabAt(tab, index) == b) {
- TreeNode<K,V> hd = null, tl = null;
- //构造了一个TreeBin对象 把所有Node节点包装成TreeNode放进去
- for (Node<K,V> e = b; e != null; e = e.next) {
- TreeNode<K,V> p =
- new TreeNode<K,V>(e.hash, e.key, e.val,
- null, null);//这里只是利用了TreeNode封装 而没有利用TreeNode的next域和parent域
- if ((p.prev = tl) == null)
- hd = p;
- else
- tl.next = p;
- tl = p;
- }
- //在原来index的位置 用TreeBin替换掉原来的Node对象
- setTabAt(tab, index, new TreeBin<K,V>(hd));
- }
- }
- }
- }
- }
本人注:
你说的是JDK1.8之前的吧,那种叫做头插法,1.8的时候是插入尾部的
是的,就是1.6的这种表头插入所以在多并发情况下可能会导致死循环
如果这个位置是Node节点(fh>=0),如果它是一个链表的头节点,就构造一个反序链表,把他们分别放在nextTable的i和i+n的位置上
如果这个位置是TreeBin节点(fh<0),也做一个反序处理,并且判断是否需要untreefi,把处理的结果分别放在nextTable的i和i+n的位置上
----------------------------
这里是有问题的,说的不是很清楚,不是说结果分别放在nextTable的i和i+n的位置上,
这个原理和hashmap的一样,因为是2的n次房的容量,所以hash的新的位置的索引if ((ph & n) == 0) 时就在原位置,否则就在i+n的位置上。
这个地方是没有构建反向链表,因为元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),
因此链表根据高位为0或者1分为两个子链表,
高位为0的节点桶位置没有发生变化,高位为1的节点桶位置增加了n,所以有setTabAt(nextTab, i, ln);和 setTabAt(nextTab, i + n, hn);
7 get方法
get方法比较简单,给定一个key来确定value的时候,必须满足两个条件 key相同 hash值相同,对于节点可能在链表或树上的情况,需要分别去查找.
- public V get(Object key) {
- Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
- //计算hash值
- int h = spread(key.hashCode());
- //根据hash值确定节点位置
- if ((tab = table) != null && (n = tab.length) > 0 &&
- (e = tabAt(tab, (n - 1) & h)) != null) {
- //如果搜索到的节点key与传入的key相同且不为null,直接返回这个节点
- if ((eh = e.hash) == h) {
- if ((ek = e.key) == key || (ek != null && key.equals(ek)))
- return e.val;
- }
- //如果eh<0 说明这个节点在树上 直接寻找
- else if (eh < 0)
- return (p = e.find(h, key)) != null ? p.val : null;
- //否则遍历链表 找到对应的值并返回
- while ((e = e.next) != null) {
- if (e.hash == h &&
- ((ek = e.key) == key || (ek != null && key.equals(ek))))
- return e.val;
- }
- }
- return null;
- }
8 Size相关的方法
对于ConcurrentHashMap来说,这个table里到底装了多少东西其实是个不确定的数量,因为不可能在调用size()方法的时候像GC的“stop the world”一样让其他线程都停下来让你去统计,因此只能说这个数量是个估计值。对于这个估计值,ConcurrentHashMap也是大费周章才计算出来的。
8.1 辅助定义
为了统计元素个数,ConcurrentHashMap定义了一些变量和一个内部类
- /**
- * A padded cell for distributing counts. Adapted from LongAdder
- * and Striped64. See their internal docs for explanation.
- */
- @sun.misc.Contended static final class CounterCell {
- volatile long value;
- CounterCell(long x) { value = x; }
- }
- /******************************************/
- /**
- * 实际上保存的是hashmap中的元素个数 利用CAS锁进行更新
- 但它并不用返回当前hashmap的元素个数
- */
- private transient volatile long baseCount;
- /**
- * Spinlock (locked via CAS) used when resizing and/or creating CounterCells.
- */
- private transient volatile int cellsBusy;
- /**
- * Table of counter cells. When non-null, size is a power of 2.
- */
- private transient volatile CounterCell[] counterCells;
8.2 mappingCount与Size方法
mappingCount与size方法的类似 从Java工程师给出的注释来看,应该使用mappingCount代替size方法 两个方法都没有直接返回basecount 而是统计一次这个值,而这个值其实也是一个大概的数值,因此可能在统计的时候有其他线程正在执行插入或删除操作。
- public int size() {
- long n = sumCount();
- return ((n < 0L) ? 0 :
- (n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
- (int)n);
- }
- /**
- * Returns the number of mappings. This method should be used
- * instead of {@link #size} because a ConcurrentHashMap may
- * contain more mappings than can be represented as an int. The
- * value returned is an estimate; the actual count may differ if
- * there are concurrent insertions or removals.
- *
- * @return the number of mappings
- * @since 1.8
- */
- public long mappingCount() {
- long n = sumCount();
- return (n < 0L) ? 0L : n; // ignore transient negative values
- }
- final long sumCount() {
- CounterCell[] as = counterCells; CounterCell a;
- long sum = baseCount;
- if (as != null) {
- for (int i = 0; i < as.length; ++i) {
- if ((a = as[i]) != null)
- sum += a.value;//所有counter的值求和
- }
- }
- return sum;
- }
8.3 addCount方法
在put方法结尾处调用了addCount方法,把当前ConcurrentHashMap的元素个数+1这个方法一共做了两件事,更新baseCount的值,检测是否进行扩容。
- private final void addCount(long x, int check) {
- CounterCell[] as; long b, s;
- //利用CAS方法更新baseCount的值
- if ((as = counterCells) != null ||
- !U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
- CounterCell a; long v; int m;
- boolean uncontended = true;
- if (as == null || (m = as.length - 1) < 0 ||
- (a = as[ThreadLocalRandom.getProbe() & m]) == null ||
- !(uncontended =
- U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
- fullAddCount(x, uncontended);
- return;
- }
- if (check <= 1)
- return;
- s = sumCount();
- }
- //如果check值大于等于0 则需要检验是否需要进行扩容操作
- if (check >= 0) {
- Node<K,V>[] tab, nt; int n, sc;
- while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
- (n = tab.length) < MAXIMUM_CAPACITY) {
- int rs = resizeStamp(n);
- //
- if (sc < 0) {
- if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
- sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
- transferIndex <= 0)
- break;
- //如果已经有其他线程在执行扩容操作
- if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
- transfer(tab, nt);
- }
- //当前线程是唯一的或是第一个发起扩容的线程 此时nextTable=null
- else if (U.compareAndSwapInt(this, SIZECTL, sc,
- (rs << RESIZE_STAMP_SHIFT) + 2))
- transfer(tab, null);
- s = sumCount();
- }
- }
- }
CAS
CAS:Compare and Swap, 翻译成比较并交换。
java.util.concurrent包中借助CAS实现了区别于synchronouse同步锁的一种乐观锁。
本文先从CAS的应用说起,再深入原理解析。
CAS应用
CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
非阻塞算法 (nonblocking algorithms)
一个线程的失败或者挂起不应该影响其他线程的失败或挂起的算法。
现代的CPU提供了特殊的指令,可以自动更新共享数据,而且能够检测到其他线程的干扰,而 compareAndSet() 就用这些代替了锁定。
拿出AtomicInteger来研究在没有锁的情况下是如何做到数据正确性的。
private volatile int value;
首先毫无以为,在没有锁的机制下可能需要借助volatile原语,保证线程间的数据是可见的(共享的)。
这样才获取变量的值的时候才能直接读取。
public final int get() {
return value;
}
然后来看看++i是怎么做到的。
public final int incrementAndGet() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return next;
}
}
在这里采用了CAS操作,每次从内存中读取数据然后将此数据和+1后的结果进行CAS操作,如果成功就返回结果,否则重试直到成功为止。
而compareAndSet利用JNI来完成CPU指令的操作。
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
整体的过程就是这样子的,利用CPU的CAS指令,同时借助JNI来完成Java的非阻塞算法。其它原子操作都是利用类似的特性完成的。
其中
unsafe.compareAndSwapInt(this, valueOffset, expect, update);
类似:
if (this == expect) {
this = update
return true;
} else {
return false;
}
那么问题就来了,成功过程中需要2个步骤:比较this == expect,替换this = update,compareAndSwapInt如何这两个步骤的原子性呢? 参考CAS的原理。
CAS原理
CAS通过调用JNI的代码实现的。JNI:Java Native Interface为JAVA本地调用,允许java调用其他语言。
而compareAndSwapInt就是借助C来调用CPU底层指令实现的。
下面从分析比较常用的CPU(intel x86)来解释CAS的实现原理。
下面是sun.misc.Unsafe类的compareAndSwapInt()方法的源代码:
可以看到这是个本地方法调用。这个本地方法在openjdk中依次调用的c++代码为:unsafe.cpp,atomic.cpp和atomicwindowsx86.inline.hpp。这个本地方法的最终实现在openjdk的如下位置:openjdk-7-fcs-src-b147-27jun2011\openjdk\hotspot\src\oscpu\windowsx86\vm\ atomicwindowsx86.inline.hpp(对应于windows操作系统,X86处理器)。下面是对应于intel x86处理器的源代码的片段:
如上面源代码所示,程序会根据当前处理器的类型来决定是否为cmpxchg指令添加lock前缀。如果程序是在多处理器上运行,就为cmpxchg指令加上lock前缀(lock cmpxchg)。反之,如果程序是在单处理器上运行,就省略lock前缀(单处理器自身会维护单处理器内的顺序一致性,不需要lock前缀提供的内存屏障效果)。
intel的手册对lock前缀的说明如下:
- 确保对内存的读-改-写操作原子执行。在Pentium及Pentium之前的处理器中,带有lock前缀的指令在执行期间会锁住总线,使得其他处理器暂时无法通过总线访问内存。很显然,这会带来昂贵的开销。从Pentium 4,Intel Xeon及P6处理器开始,intel在原有总线锁的基础上做了一个很有意义的优化:如果要访问的内存区域(area of memory)在lock前缀指令执行期间已经在处理器内部的缓存中被锁定(即包含该内存区域的缓存行当前处于独占或以修改状态),并且该内存区域被完全包含在单个缓存行(cache line)中,那么处理器将直接执行该指令。由于在指令执行期间该缓存行会一直被锁定,其它处理器无法读/写该指令要访问的内存区域,因此能保证指令执行的原子性。这个操作过程叫做缓存锁定(cache locking),缓存锁定将大大降低lock前缀指令的执行开销,但是当多处理器之间的竞争程度很高或者指令访问的内存地址未对齐时,仍然会锁住总线。
- 禁止该指令与之前和之后的读和写指令重排序。
- 把写缓冲区中的所有数据刷新到内存中。
备注知识:
关于CPU的锁有如下3种:
3.1 处理器自动保证基本内存操作的原子性
首先处理器会自动保证基本的内存操作的原子性。处理器保证从系统内存当中读取或者写入一个字节是原子的,意思是当一个处理器读取一个字节时,其他处理器不能访问这个字节的内存地址。奔腾6和最新的处理器能自动保证单处理器对同一个缓存行里进行16/32/64位的操作是原子的,但是复杂的内存操作处理器不能自动保证其原子性,比如跨总线宽度,跨多个缓存行,跨页表的访问。但是处理器提供总线锁定和缓存锁定两个机制来保证复杂内存操作的原子性。
3.2 使用总线锁保证原子性
第一个机制是通过总线锁保证原子性。如果多个处理器同时对共享变量进行读改写(i++就是经典的读改写操作)操作,那么共享变量就会被多个处理器同时进行操作,这样读改写操作就不是原子的,操作完之后共享变量的值会和期望的不一致,举个例子:如果i=1,我们进行两次i++操作,我们期望的结果是3,但是有可能结果是2。如下图

原因是有可能多个处理器同时从各自的缓存中读取变量i,分别进行加一操作,然后分别写入系统内存当中。那么想要保证读改写共享变量的操作是原子的,就必须保证CPU1读改写共享变量的时候,CPU2不能操作缓存了该共享变量内存地址的缓存。
处理器使用总线锁就是来解决这个问题的。所谓总线锁就是使用处理器提供的一个LOCK#信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,那么该处理器可以独占使用共享内存。
3.3 使用缓存锁保证原子性
第二个机制是通过缓存锁定保证原子性。在同一时刻我们只需保证对某个内存地址的操作是原子性即可,但总线锁定把CPU和内存之间通信锁住了,这使得锁定期间,其他处理器不能操作其他内存地址的数据,所以总线锁定的开销比较大,最近的处理器在某些场合下使用缓存锁定代替总线锁定来进行优化。
频繁使用的内存会缓存在处理器的L1,L2和L3高速缓存里,那么原子操作就可以直接在处理器内部缓存中进行,并不需要声明总线锁,在奔腾6和最近的处理器中可以使用“缓存锁定”的方式来实现复杂的原子性。所谓“缓存锁定”就是如果缓存在处理器缓存行中内存区域在LOCK操作期间被锁定,当它执行锁操作回写内存时,处理器不在总线上声言LOCK#信号,而是修改内部的内存地址,并允许它的缓存一致性机制来保证操作的原子性,因为缓存一致性机制会阻止同时修改被两个以上处理器缓存的内存区域数据,当其他处理器回写已被锁定的缓存行的数据时会起缓存行无效,在例1中,当CPU1修改缓存行中的i时使用缓存锁定,那么CPU2就不能同时缓存了i的缓存行。
但是有两种情况下处理器不会使用缓存锁定。第一种情况是:当操作的数据不能被缓存在处理器内部,或操作的数据跨多个缓存行(cache line),则处理器会调用总线锁定。第二种情况是:有些处理器不支持缓存锁定。对于Inter486和奔腾处理器,就算锁定的内存区域在处理器的缓存行中也会调用总线锁定。
以上两个机制我们可以通过Inter处理器提供了很多LOCK前缀的指令来实现。比如位测试和修改指令BTS,BTR,BTC,交换指令XADD,CMPXCHG和其他一些操作数和逻辑指令,比如ADD(加),OR(或)等,被这些指令操作的内存区域就会加锁,导致其他处理器不能同时访问它。
CAS缺点
CAS虽然很高效的解决原子操作,但是CAS仍然存在三大问题。ABA问题,循环时间长开销大和只能保证一个共享变量的原子操作
1. ABA问题。因为CAS需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加一,那么A-B-A 就会变成1A-2B-3A。
从Java1.5开始JDK的atomic包里提供了一个类AtomicStampedReference来解决ABA问题。这个类的compareAndSet方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
关于ABA问题参考文档: http://blog.hesey.net/2011/09/resolve-aba-by-atomicstampedreference.html
2. 循环时间长开销大。自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
3. 只能保证一个共享变量的原子操作。当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁,或者有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij。从Java1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行CAS操作。
concurrent包的实现
由于java的CAS同时具有 volatile 读和volatile写的内存语义,因此Java线程之间的通信现在有了下面四种方式:
- A线程写volatile变量,随后B线程读这个volatile变量。
- A线程写volatile变量,随后B线程用CAS更新这个volatile变量。
- A线程用CAS更新一个volatile变量,随后B线程用CAS更新这个volatile变量。
- A线程用CAS更新一个volatile变量,随后B线程读这个volatile变量。
Java的CAS会使用现代处理器上提供的高效机器级别原子指令,这些原子指令以原子方式对内存执行读-改-写操作,这是在多处理器中实现同步的关键(从本质上来说,能够支持原子性读-改-写指令的计算机器,是顺序计算图灵机的异步等价机器,因此任何现代的多处理器都会去支持某种能对内存执行原子性读-改-写操作的原子指令)。同时,volatile变量的读/写和CAS可以实现线程之间的通信。把这些特性整合在一起,就形成了整个concurrent包得以实现的基石。如果我们仔细分析concurrent包的源代码实现,会发现一个通用化的实现模式:
- 首先,声明共享变量为volatile;
- 然后,使用CAS的原子条件更新来实现线程之间的同步;
- 同时,配合以volatile的读/写和CAS所具有的volatile读和写的内存语义来实现线程之间的通信。
AQS,非阻塞数据结构和原子变量类(java.util.concurrent.atomic包中的类),这些concurrent包中的基础类都是使用这种模式来实现的,而concurrent包中的高层类又是依赖于这些基础类来实现的。从整体来看,concurrent包的实现示意图如下:

非阻塞同步算法与CAS(Compare and Swap)无锁算法
锁(lock)的代价
锁是用来做并发最简单的方式,当然其代价也是最高的。内核态的锁的时候需要操作系统进行一次上下文切换,加锁、释放锁会导致比较多的上下文切换和调度延时,等待锁的线程会被挂起直至锁释放。在上下文切换的时候,cpu之前缓存的指令和数据都将失效,对性能有很大的损失。操作系统对多线程的锁进行判断就像两姐妹在为一个玩具在争吵,然后操作系统就是能决定他们谁能拿到玩具的父母,这是很慢的。用户态的锁虽然避免了这些问题,但是其实它们只是在没有真实的竞争时才有效。
Java在JDK1.5之前都是靠synchronized关键字保证同步的,这种通过使用一致的锁定协议来协调对共享状态的访问,可以确保无论哪个线程持有守护变量的锁,都采用独占的方式来访问这些变量,如果出现多个线程同时访问锁,那第一些线线程将被挂起,当线程恢复执行时,必须等待其它线程执行完他们的时间片以后才能被调度执行,在挂起和恢复执行过程中存在着很大的开销。锁还存在着其它一些缺点,当一个线程正在等待锁时,它不能做任何事。如果一个线程在持有锁的情况下被延迟执行,那么所有需要这个锁的线程都无法执行下去。如果被阻塞的线程优先级高,而持有锁的线程优先级低,将会导致优先级反转(Priority Inversion)。
乐观锁与悲观锁
独占锁是一种悲观锁,synchronized就是一种独占锁,它假设最坏的情况,并且只有在确保其它线程不会造成干扰的情况下执行,会导致其它所有需要锁的线程挂起,等待持有锁的线程释放锁。而另一个更加有效的锁就是乐观锁。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。
volatile的问题
与锁相比,volatile变量是一和更轻量级的同步机制,因为在使用这些变量时不会发生上下文切换和线程调度等操作,但是volatile变量也存在一些局限:不能用于构建原子的复合操作,因此当一个变量依赖旧值时就不能使用volatile变量。(参考:谈谈volatiile)
volatile只能保证变量对各个线程的可见性,但不能保证原子性。为什么?见我的另外一篇文章:《为什么volatile不能保证原子性而Atomic可以?》
Java中的原子操作( atomic operations)
原子操作指的是在一步之内就完成而且不能被中断。原子操作在多线程环境中是线程安全的,无需考虑同步的问题。在java中,下列操作是原子操作:
- all assignments of primitive types except for long and double
- all assignments of references
- all operations of java.concurrent.Atomic* classes
- all assignments to volatile longs and doubles
问题来了,为什么long型赋值不是原子操作呢?例如:
|
1
|
long
foo = 65465498L;
|
实时上java会分两步写入这个long变量,先写32位,再写后32位。这样就线程不安全了。如果改成下面的就线程安全了:
|
1
|
private
volatile
long
foo;
|
因为volatile内部已经做了synchronized.
CAS无锁算法
要实现无锁(lock-free)的非阻塞算法有多种实现方法,其中CAS(比较与交换,Compare and swap)是一种有名的无锁算法。CAS, CPU指令,在大多数处理器架构,包括IA32、Space中采用的都是CAS指令,CAS的语义是“我认为V的值应该为A,如果是,那么将V的值更新为B,否则不修改并告诉V的值实际为多少”,CAS是项乐观锁技术,当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。CAS无锁算法的C实现如下:
|
1
2
3
4
5
6
7
8
9
|
int
compare_and_swap (
int
* reg,
int
oldval,
int
newval)
{
ATOMIC();
int
old_reg_val = *reg;
if
(old_reg_val == oldval)
*reg = newval;
END_ATOMIC();
return
old_reg_val;
}
|
CAS(乐观锁算法)的基本假设前提
CAS比较与交换的伪代码可以表示为:
do{
备份旧数据;
基于旧数据构造新数据;
}while(!CAS( 内存地址,备份的旧数据,新数据 ))

(上图的解释:CPU去更新一个值,但如果想改的值不再是原来的值,操作就失败,因为很明显,有其它操作先改变了这个值。)
就是指当两者进行比较时,如果相等,则证明共享数据没有被修改,替换成新值,然后继续往下运行;如果不相等,说明共享数据已经被修改,放弃已经所做的操作,然后重新执行刚才的操作。容易看出 CAS 操作是基于共享数据不会被修改的假设,采用了类似于数据库的 commit-retry 的模式。当同步冲突出现的机会很少时,这种假设能带来较大的性能提升。
CAS的开销(CPU Cache Miss problem)
前面说过了,CAS(比较并交换)是CPU指令级的操作,只有一步原子操作,所以非常快。而且CAS避免了请求操作系统来裁定锁的问题,不用麻烦操作系统,直接在CPU内部就搞定了。但CAS就没有开销了吗?不!有cache miss的情况。这个问题比较复杂,首先需要了解CPU的硬件体系结构:

上图可以看到一个8核CPU计算机系统,每个CPU有cache(CPU内部的高速缓存,寄存器),管芯内还带有一个互联模块,使管芯内的两个核可以互相通信。在图中央的系统互联模块可以让四个管芯相互通信,并且将管芯与主存连接起来。数据以“缓存线”为单位在系统中传输,“缓存线”对应于内存中一个 2 的幂大小的字节块,大小通常为 32 到 256 字节之间。当 CPU 从内存中读取一个变量到它的寄存器中时,必须首先将包含了该变量的缓存线读取到 CPU 高速缓存。同样地,CPU 将寄存器中的一个值存储到内存时,不仅必须将包含了该值的缓存线读到 CPU 高速缓存,还必须确保没有其他 CPU 拥有该缓存线的拷贝。
比如,如果 CPU0 在对一个变量执行“比较并交换”(CAS)操作,而该变量所在的缓存线在 CPU7 的高速缓存中,就会发生以下经过简化的事件序列:
- CPU0 检查本地高速缓存,没有找到缓存线。
- 请求被转发到 CPU0 和 CPU1 的互联模块,检查 CPU1 的本地高速缓存,没有找到缓存线。
- 请求被转发到系统互联模块,检查其他三个管芯,得知缓存线被 CPU6和 CPU7 所在的管芯持有。
- 请求被转发到 CPU6 和 CPU7 的互联模块,检查这两个 CPU 的高速缓存,在 CPU7 的高速缓存中找到缓存线。
- CPU7 将缓存线发送给所属的互联模块,并且刷新自己高速缓存中的缓存线。
- CPU6 和 CPU7 的互联模块将缓存线发送给系统互联模块。
- 系统互联模块将缓存线发送给 CPU0 和 CPU1 的互联模块。
- CPU0 和 CPU1 的互联模块将缓存线发送给 CPU0 的高速缓存。
- CPU0 现在可以对高速缓存中的变量执行 CAS 操作了
以上是刷新不同CPU缓存的开销。最好情况下的 CAS 操作消耗大概 40 纳秒,超过 60 个时钟周期。这里的“最好情况”是指对某一个变量执行 CAS 操作的 CPU 正好是最后一个操作该变量的CPU,所以对应的缓存线已经在 CPU 的高速缓存中了,类似地,最好情况下的锁操作(一个“round trip 对”包括获取锁和随后的释放锁)消耗超过 60 纳秒,超过 100 个时钟周期。这里的“最好情况”意味着用于表示锁的数据结构已经在获取和释放锁的 CPU 所属的高速缓存中了。锁操作比 CAS 操作更加耗时,是因深入理解并行编程
为锁操作的数据结构中需要两个原子操作。缓存未命中消耗大概 140 纳秒,超过 200 个时钟周期。需要在存储新值时查询变量的旧值的 CAS 操作,消耗大概 300 纳秒,超过 500 个时钟周期。想想这个,在执行一次 CAS 操作的时间里,CPU 可以执行 500 条普通指令。这表明了细粒度锁的局限性。
以下是cache miss cas 和lock的性能对比:

JVM对CAS的支持:AtomicInt, AtomicLong.incrementAndGet()
在JDK1.5之前,如果不编写明确的代码就无法执行CAS操作,在JDK1.5中引入了底层的支持,在int、long和对象的引用等类型上都公开了CAS的操作,并且JVM把它们编译为底层硬件提供的最有效的方法,在运行CAS的平台上,运行时把它们编译为相应的机器指令,如果处理器/CPU不支持CAS指令,那么JVM将使用自旋锁。因此,值得注意的是,CAS解决方案与平台/编译器紧密相关(比如x86架构下其对应的汇编指令是lock cmpxchg,如果想要64Bit的交换,则应使用lock cmpxchg8b。在.NET中我们可以使用Interlocked.CompareExchange函数)。
在原子类变量中,如java.util.concurrent.atomic中的AtomicXXX,都使用了这些底层的JVM支持为数字类型的引用类型提供一种高效的CAS操作,而在java.util.concurrent中的大多数类在实现时都直接或间接的使用了这些原子变量类。
Java 1.6中AtomicLong.incrementAndGet()的实现源码为:
由此可见,AtomicLong.incrementAndGet的实现用了乐观锁技术,调用了sun.misc.Unsafe类库里面的 CAS算法,用CPU指令来实现无锁自增。所以,AtomicLong.incrementAndGet的自增比用synchronized的锁效率倍增。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
public
final
int
getAndIncrement() {
for
(;;) {
int
current = get();
int
next = current +
1
;
if
(compareAndSet(current, next))
return
current;
}
}
public
final
boolean
compareAndSet(
int
expect,
int
update) {
return
unsafe.compareAndSwapInt(
this
, valueOffset, expect, update);
}
|
下面是测试代码:可以看到用AtomicLong.incrementAndGet的性能比用synchronized高出几倍。

CAS的例子:非阻塞堆栈
下面是比非阻塞自增稍微复杂一点的CAS的例子:非阻塞堆栈/ConcurrentStack 。ConcurrentStack 中的 push() 和pop() 操作在结构上与NonblockingCounter 上相似,只是做的工作有些冒险,希望在 “提交” 工作的时候,底层假设没有失效。push() 方法观察当前最顶的节点,构建一个新节点放在堆栈上,然后,如果最顶端的节点在初始观察之后没有变化,那么就安装新节点。如果 CAS 失败,意味着另一个线程已经修改了堆栈,那么过程就会重新开始。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
public
class
ConcurrentStack<E> {
AtomicReference<Node<E>> head =
new
AtomicReference<Node<E>>();
public
void
push(E item) {
Node<E> newHead =
new
Node<E>(item);
Node<E> oldHead;
do
{
oldHead = head.get();
newHead.next = oldHead;
}
while
(!head.compareAndSet(oldHead, newHead));
}
public
E pop() {
Node<E> oldHead;
Node<E> newHead;
do
{
oldHead = head.get();
if
(oldHead ==
null
)
return
null
;
newHead = oldHead.next;
}
while
(!head.compareAndSet(oldHead,newHead));
return
oldHead.item;
}
static
class
Node<E> {
final
E item;
Node<E> next;
public
Node(E item) {
this
.item = item; }
}
}
|
在轻度到中度的争用情况下,非阻塞算法的性能会超越阻塞算法,因为 CAS 的多数时间都在第一次尝试时就成功,而发生争用时的开销也不涉及线程挂起和上下文切换,只多了几个循环迭代。没有争用的 CAS 要比没有争用的锁便宜得多(这句话肯定是真的,因为没有争用的锁涉及 CAS 加上额外的处理),而争用的 CAS 比争用的锁获取涉及更短的延迟。
在高度争用的情况下(即有多个线程不断争用一个内存位置的时候),基于锁的算法开始提供比非阻塞算法更好的吞吐率,因为当线程阻塞时,它就会停止争用,耐心地等候轮到自己,从而避免了进一步争用。但是,这么高的争用程度并不常见,因为多数时候,线程会把线程本地的计算与争用共享数据的操作分开,从而给其他线程使用共享数据的机会。
CAS的例子3:非阻塞链表
以上的示例(自增计数器和堆栈)都是非常简单的非阻塞算法,一旦掌握了在循环中使用 CAS,就可以容易地模仿它们。对于更复杂的数据结构,非阻塞算法要比这些简单示例复杂得多,因为修改链表、树或哈希表可能涉及对多个指针的更新。CAS 支持对单一指针的原子性条件更新,但是不支持两个以上的指针。所以,要构建一个非阻塞的链表、树或哈希表,需要找到一种方式,可以用 CAS 更新多个指针,同时不会让数据结构处于不一致的状态。
在链表的尾部插入元素,通常涉及对两个指针的更新:“尾” 指针总是指向列表中的最后一个元素,“下一个” 指针从过去的最后一个元素指向新插入的元素。因为需要更新两个指针,所以需要两个 CAS。在独立的 CAS 中更新两个指针带来了两个需要考虑的潜在问题:如果第一个 CAS 成功,而第二个 CAS 失败,会发生什么?如果其他线程在第一个和第二个 CAS 之间企图访问链表,会发生什么?
对于非复杂数据结构,构建非阻塞算法的 “技巧” 是确保数据结构总处于一致的状态(甚至包括在线程开始修改数据结构和它完成修改之间),还要确保其他线程不仅能够判断出第一个线程已经完成了更新还是处在更新的中途,还能够判断出如果第一个线程走向 AWOL,完成更新还需要什么操作。如果线程发现了处在更新中途的数据结构,它就可以 “帮助” 正在执行更新的线程完成更新,然后再进行自己的操作。当第一个线程回来试图完成自己的更新时,会发现不再需要了,返回即可,因为 CAS 会检测到帮助线程的干预(在这种情况下,是建设性的干预)。
这种 “帮助邻居” 的要求,对于让数据结构免受单个线程失败的影响,是必需的。如果线程发现数据结构正处在被其他线程更新的中途,然后就等候其他线程完成更新,那么如果其他线程在操作中途失败,这个线程就可能永远等候下去。即使不出现故障,这种方式也会提供糟糕的性能,因为新到达的线程必须放弃处理器,导致上下文切换,或者等到自己的时间片过期(而这更糟)。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
public
class
LinkedQueue <E> {
private
static
class
Node <E> {
final
E item;
final
AtomicReference<Node<E>> next;
Node(E item, Node<E> next) {
this
.item = item;
this
.next =
new
AtomicReference<Node<E>>(next);
}
}
private
AtomicReference<Node<E>> head
=
new
AtomicReference<Node<E>>(
new
Node<E>(
null
,
null
));
private
AtomicReference<Node<E>> tail = head;
public
boolean
put(E item) {
Node<E> newNode =
new
Node<E>(item,
null
);
while
(
true
) {
Node<E> curTail = tail.get();
Node<E> residue = curTail.next.get();
if
(curTail == tail.get()) {
if
(residue ==
null
)
/* A */
{
if
(curTail.next.compareAndSet(
null
, newNode))
/* C */
{
tail.compareAndSet(curTail, newNode)
/* D */
;
return
true
;
}
}
else
{
tail.compareAndSet(curTail, residue)
/* B */
;
}
}
}
}
}
|
具体算法相见IBM Developerworks
Java的ConcurrentHashMap的实现原理
Java5中的ConcurrentHashMap,线程安全,设计巧妙,用桶粒度的锁,避免了put和get中对整个map的锁定,尤其在get中,只对一个HashEntry做锁定操作,性能提升是显而易见的。

具体实现中使用了锁分离机制,在这个帖子中有非常详细的讨论。这里有关于Java内存模型结合ConcurrentHashMap的分析。以下是JDK6的ConcurrentHashMap的源码:
Java的ConcurrentLinkedQueue实现方法
ConcurrentLinkedQueue也是同样使用了CAS指令,但其性能并不高因为太多CAS操作。其源码如下:
高并发环境下优化锁或无锁(lock-free)的设计思路
服务端编程的3大性能杀手:1、大量线程导致的线程切换开销。2、锁。3、非必要的内存拷贝。在高并发下,对于纯内存操作来说,单线程是要比多线程快的, 可以比较一下多线程程序在压力测试下cpu的sy和ni百分比。高并发环境下要实现高吞吐量和线程安全,两个思路:一个是用优化的锁实现,一个是lock-free的无锁结构。但非阻塞算法要比基于锁的算法复杂得多。开发非阻塞算法是相当专业的训练,而且要证明算法的正确也极为困难,不仅和具体的目标机器平台和编译器相关,而且需要复杂的技巧和严格的测试。虽然Lock-Free编程非常困难,但是它通常可以带来比基于锁编程更高的吞吐量。所以Lock-Free编程是大有前途的技术。它在线程中止、优先级倒置以及信号安全等方面都有着良好的表现。
- 优化锁实现的例子:Java中的ConcurrentHashMap,设计巧妙,用桶粒度的锁和锁分离机制,避免了put和get中对整个map的锁定,尤其在get中,只对一个HashEntry做锁定操作,性能提升是显而易见的(详细分析见《探索 ConcurrentHashMap 高并发性的实现机制》)。
- Lock-free无锁的例子:CAS(CPU的Compare-And-Swap指令)的利用和LMAX的disruptor无锁消息队列数据结构等。有兴趣了解LMAX的disruptor无锁消息队列数据结构的可以移步slideshare。

另外,在设计思路上除了尽量减少资源争用以外,还可以借鉴nginx/node.js等单线程大循环的机制,用单线程或CPU数相同的线程开辟大的队列,并发的时候任务压入队列,线程轮询然后一个个顺序执行。由于每个都采用异步I/O,没有阻塞线程。这个大队列可以使用RabbitMQueue,或是JDK的同步队列(性能稍差),或是使用Disruptor无锁队列(Java)。任务处理可以全部放在内存(多级缓存、读写分离、ConcurrentHashMap、甚至分布式缓存Redis)中进行增删改查。最后用Quarz维护定时把缓存数据同步到DB中。当然,这只是中小型系统的思路,如果是大型分布式系统会非常复杂,需要分而治理,用SOA的思路,参考这篇文章的图。(注:Redis是单线程的纯内存数据库,单线程无需锁,而Memcache是多线程的带CAS算法,两者都使用epoll,no-blocking io)

深入JVM的OS的无锁非阻塞算法
如果深入 JVM 和操作系统,会发现非阻塞算法无处不在。垃圾收集器使用非阻塞算法加快并发和平行的垃圾搜集;调度器使用非阻塞算法有效地调度线程和进程,实现内在锁。在 Mustang(Java 6.0)中,基于锁的SynchronousQueue 算法被新的非阻塞版本代替。很少有开发人员会直接使用 SynchronousQueue,但是通过Executors.newCachedThreadPool() 工厂构建的线程池用它作为工作队列。比较缓存线程池性能的对比测试显示,新的非阻塞同步队列实现提供了几乎是当前实现 3 倍的速度。在 Mustang 的后续版本(代码名称为 Dolphin)中,已经规划了进一步的改进。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









