







关于使用pager-taglib分页前端传递中文参数乱码问题的解决方案
1.重现问题
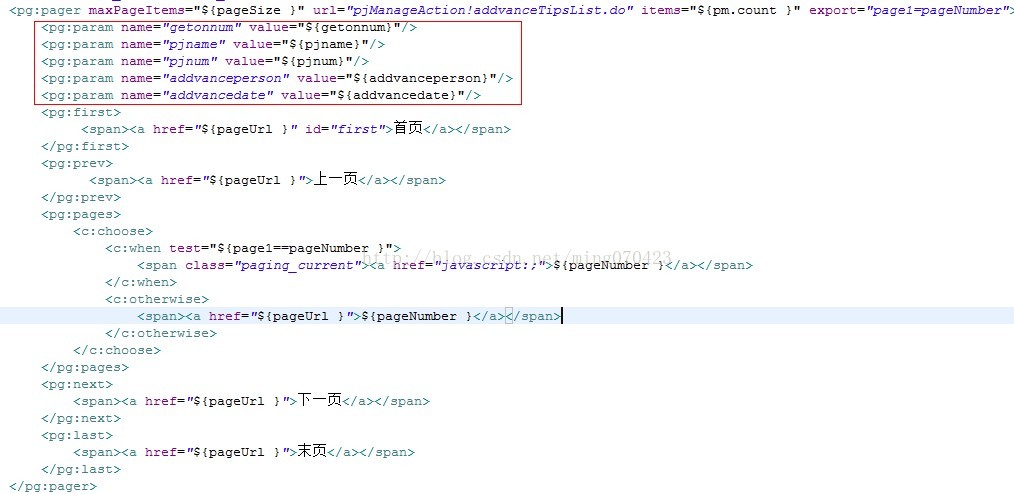
在web项目中有时会用到pager-taglib来作为分页的标签,如上图红色框标识所示,当我们需要把页面参数保持的时候我们会在<pg:param />标签中把参数进行传递。
如果你的页面编码为gb2312那这样写是没有问题的,但是如果你的页面编码是utf-8的话那就会出现乱码问题。我尝试了很多方法,编码过滤器,编码拦截器(struts2),传递
参数的时候进行编码然后后台进行解码,还有WEB(如TomCat等)应用服务器编码。还是觉得这些方法没有从根本上解决问题。既然是用pager-taglib标签进行分页,那我们就
去看看pager-taglib里面关于字符集编码的处理。
2.pager-taglib字符集处理源码
a.首先我们要准备一个pager-taglib-2.0的war包

b.然后我们把它解压
在WEB-INF下面的lib包下面有两个jar包
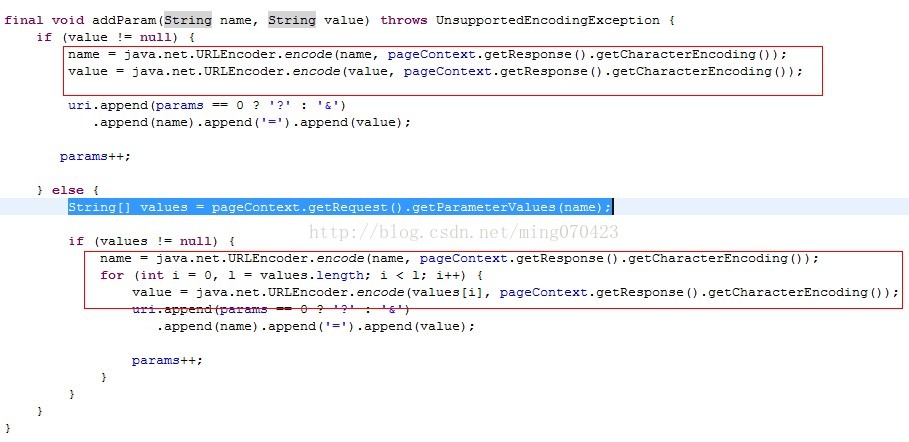
c.pager-src.jar这就是pager-taglib的源码包,我们打开它找到final void addParams(String name, Stringvalue)这个方法
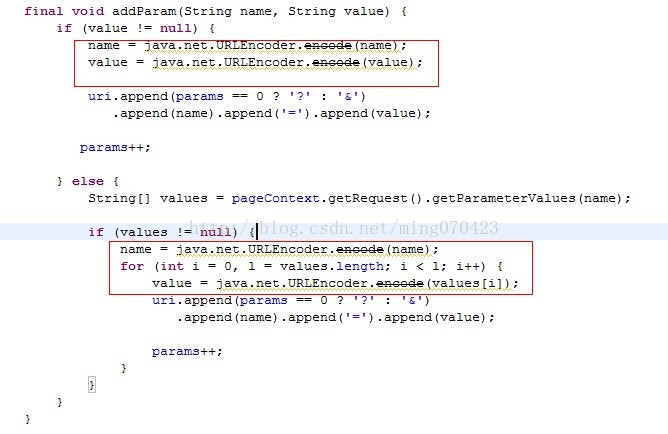
上图标红的几行代码很容易就能看出URLEncoder.encode(value)方法就是在对传递的参数进行字符集编码处理,那具体是怎么处理呢?
我们继续跟进去看源码.
d.URLEncoder源码
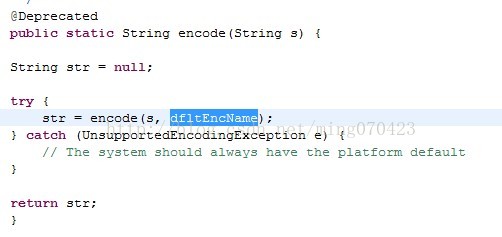
找到这个方法后我们发现它已经被标上了@Deprecated的注解,这是个什么意思,由于英文不好,咱打开翻译工具查一下
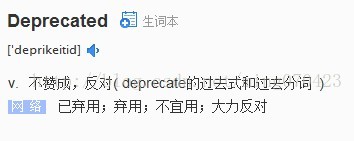
好吧,已经是不推荐的方法了,但是没关系,这个方法它调用了另外一个encode(s, dfltEncName)方法,那咱继续跟进去看
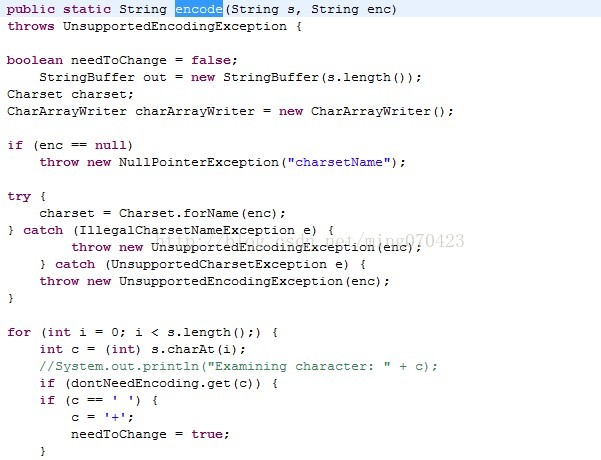
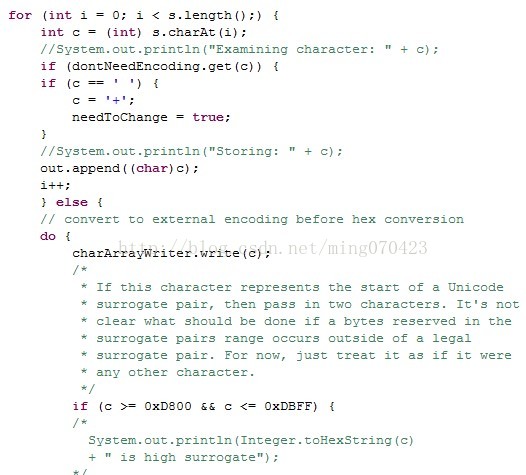
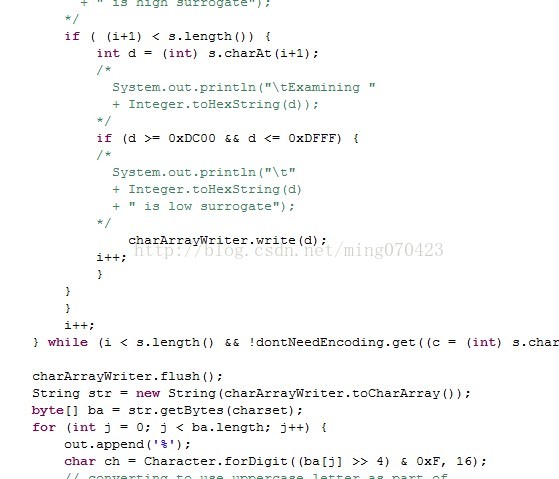
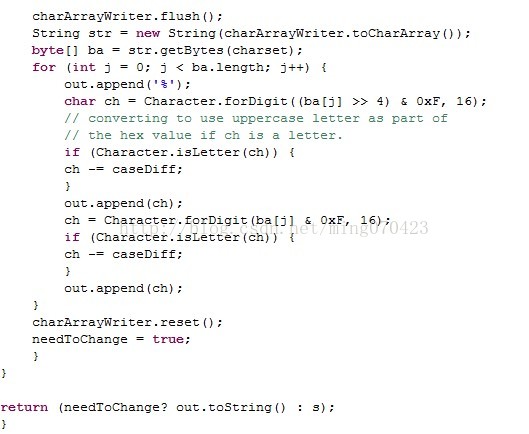
一大段源码,看关键地方
if(enc == null){
throw new NullPointerException("charsetName");
}
我不是技术大牛,但是一看到charstName这个关键字,咱还是知道肯定跟字符集有关,那enc这个参数是什么意思呢?
往上看,这个就是那个过时的encode(s, dfltEncname)传递过来的参数dfltEncName不就是是defaultEncName的缩写?
什么意思呢?默认的环境名称?不清楚继续找看哪里有对这个变量的操作:
然后在这个类的staic静态块里面找到了
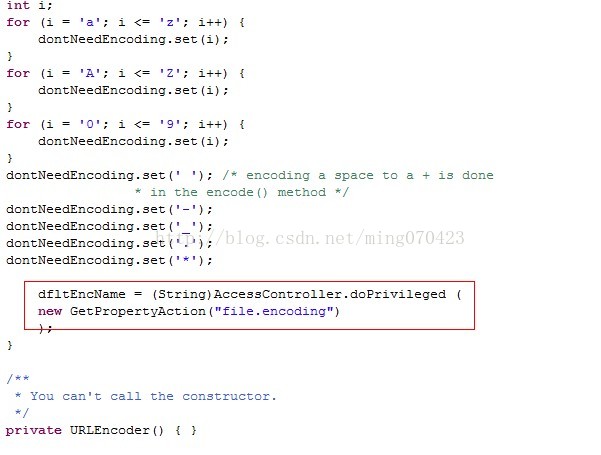
到此咱还是不明白到底是个怎么处理过程,不要急,继续找这个GetPropertyAction("file.encoding")的麻烦,但是看到这个方法是不是很眼熟?
咱要获得咱当前操作系统的字符集编码不是都这么写吗?

然后咱再进GetPropertyAction这个类的源码看看
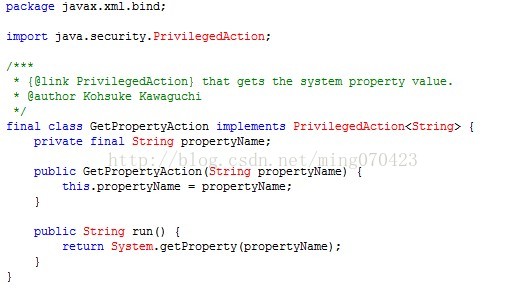
好吧,看到这里想必大家都明白了,原来pager-taglib默认最字符集编码的处理就是使用你当前操作系统的编码方式,
就算你页面设置的其他的字符集编码,它也不会管你的,它还是取得当前系统的字符集编码方式然后处理,突然觉得
编写这个pager-taglib的人好JB蠢。 一般如果咱使用的是window的操作系统,那么编码都是GBK,到此咱就明白了吧。
因为你的页面用的是utf-8编码,而你传递中文参数的时候pager-taglib又默认用GBK编码进行的处理,理所当然就会出现乱码了。
那么解决方案呢?
咱再回到PagerTag类里面,就在encode()方法下面一点,咱仔细一看有这么一行代码
String[] values = pageContext.getRequest().getParameterValues(name);
这不是牛B的pageContext对象吗?那咱是不是可以从这个上下文中拿到页面你设置的编码方式呢?
答案是肯定的,所以咱只需做如下修改
3.解决问题
好了,接下来需要做的事很简单了,将你修改过后的东西整个打成jar包然后上传的项目就可以解决中文乱码问题了,你再也不用encode()过去,decode()回来了.
a.首先在你的IDE中新建一个名为pager-taglib的项目,然后把官方的pager-src下面的com包下面的java类和META-IF导入
找到PagerTag.java类进行上面解决方案中的修改,然后用你用的IDE导出jar包,我用的是myeclipse
File --> Export -->java --> JAR file
4.总结
刚遇到这个问题的时候我也去网上找解决办法。关于最后进行修改编码的这部分,网上有相关的文章,但是几乎所有的都只是说pager-talib用的是你系统
默认的编码方式,需要改成你页面的编码方式。但是个人不喜欢这种知其然不知其所以然的方式,所以自己跟着源码进去找到了pager-taglib到底是怎么用
系统默认的编码方式的,最后想要取得页面编码方式的时候又看到了pageContext这个对象,又增强了自己对pageContext这个对象的认识。因为网上有很
多修改编码方式是直接写上去的就像这样
name = java.net.URLEncoder.encode(name, "utf-8");
value = java.net.URLEncoder.encode(value, "utf-8");
个人觉得这是很愚蠢的办法,因为导致中文乱码的原因并不是你没有使用utf-8的编码,而是因为页面和pager-taglib处理中文乱码的编码不一致导致的,
虽然现在基本上对中文编码的处理就utf-8和gbk但是我假如有很多对于中文编码的处理,当我页面用的另外一种其他的编码的时候你还是在这里写死utf-8
岂不是很2B?所以这里还是推荐
name = java.net.URLEncoder.encode(name, pageContext.getResponse().getCharacterEncoding());
value = java.net.URLEncoder.encode(values[i], pageContext.getResponse().getCharacterEncoding());
这种方式,因为我们需要做的只是取到页面的编码方式和pager-taglib保持一致而已.
当然,可能还有一些其它的更好的解决方案,或者其它的问题所导致的乱码问题,这里仅推荐个人觉得适合的对这个问题的解决方案.














 135
135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









