









X = np.array([ [0,0,1],[0,1,1],[1,0,1],[1,1,1] ])
y = np.array([[0,1,1,0]]).T
syn0 = 2*np.random.random((3,4)) - 1 #随机初始化权重
syn1 = 2*np.random.random((4,1)) - 1 #随机初始化权重
for j in xrange(60000): #迭代次数
l1 = 1/(1+np.exp(-(np.dot(X,syn0)))) #正向传播
l2 = 1/(1+np.exp(-(np.dot(l1,syn1)))) #正向传播
l2_delta = (y - l2)*(l2*(1-l2)) #反向传播
l1_delta = l2_delta.dot(syn1.T) * (l1 * (1-l1)) #反向传播
syn1 += l1.T.dot(l2_delta) #更新权重
syn0 += X.T.dot(l1_delta) #更新权重

import numpy as np
# sigmoid 函数,也可以求导用
def nonlin(x,deriv=False):
if(deriv==True):
return nonlin(x)*(1-nonlin(x))
return 1/(1+np.exp(-x))
# input dataset
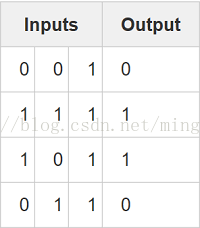
X = np.array([ [0,0,1],
[0,1,1],
[1,0,1],
[1,1,1] ])
# output dataset
y = np.array([[0,0,1,1]]).T
# seed random numbers to make calculation
# deterministic (just a good practice)
np.random.seed(1)
# 随机初始化均值为0的权重,目的是打破对称性,否则更新权重值可能相同
syn0 = 2*np.random.random((3,1)) - 1
for iter in xrange(10000):
# forward propagation
l0 = X
l1 = nonlin(np.dot(l0,syn0))
# how much did we miss?
l1_error = y - l1
# multiply how much we missed by the
# slope of the sigmoid at the values in l1 反向传播公式
l1_delta = l1_error * nonlin(l1,True)
# update weights
syn0 += np.dot(l0.T,l1_delta)
print "Output After Training:"
print l1Output After Training:
[[ 0.00966449]
[ 0.00786506]
[ 0.99358898]
[ 0.99211957]]
l1_delta = l1_error * nonlin(l1,True)syn0 += np.dot(l0.T, l1_delta)代码逐行解析:
(1)第一行载入numpy函数库
(2)第四行定义sigmoid函数,取值[0,1],用它来表示概率
(3)第五行定义sigmoid导数,如果deriv == True,那么返回out*(1-out) ,out = sigmoid(z)
(4)第十行使用numpy中的矩阵初始化数据,每一行代表一个数据,每一列对应着神经网输入节点,本例中有4个数据,3个输入节点
(5)第十六行初始化输出数据,T代表转置,y具有4行1列,与输入数据相对应。因此对于每个样本,有3个输入,1个输出。
(6)第二十行随机初始化权重,每次训练后仍会随机分布,更利于观察神经网络的变化(打破对称性)。
(7)第二十三行syn0为连接权重,因为只有输入层和输出层,因此只需要一个权重矩阵。其尺寸为3*1是因为我们有3个输入,一个输出。syn0代表了这个神经网络的全部参数,神经网络的性能与输入数据和输出数据无关。
(8)第二十五行开始训练网络,设定训练次数
(9)第二十八行初始层l0就是我们的输入数据,我们有4个数据,更新神经网络将会全部使用(而不是使用某几个),这称为"full batch"。
(10)第二十九行正向传播过程,也就是预测过程。首先是根据连接权重计算输出(l0*sy0),(4*3)dot (3*1)= (4*1)。再对四个样本计算出的结果使用sigmoid函数预测其为1的概率。
(11)第三十二行计算每个结果的预测结果和实际结果相差多少,就是误差
(12)第三十六行就是反向传播公式了,用来更新权重系数(最重要的),分a,b部分进行讲解
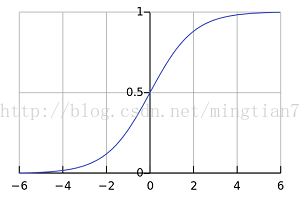
a.首先看看nonlin(l1,True),它代表sigmoid函数的梯度:

可以看到当x->0时,数值较大,越偏离0,这个数值越小
b.再来看这行代码
l1_delta = l1_error * nonlin(l1, True)l1_error是4*1,nonlin(l1,True)是4*1,*为对应元素相乘,l1_delta仍为4*1。它这种做法的含义在于减小高可信样本的预测误差。什么意思呢?当某一样本预测结果l1接近1或者0时都代表着神经网络高度肯定这是个正例或者反例,即再下次更新时该样本的误差权重应该低一些(对更新weight系数作用较小),其表现在nonlin(l1,True)返回的值较低,若l1接近0.5,即判断正例的概率为0.5,完全不确定嘛,应该加大下次更新时其误差权重(对更新weight系数作用较大),表现在nonlin(l1,True)返回值较大。
(13)第三十九行更新神经网络,首先看单一样本

更新公式:
weight_update = input_value * l1_delta
因此,简单点说,反向神经网络更新过程就是根据样本预测的正确性,不断调整样本误差的权重,即更新weights时不同样本的作用权重不同,直至网络尽量拟合所有样本。
import numpy as np
def nonlin(x,deriv=False):
if(deriv==True):
return x*(1-x)
return 1/(1+np.exp(-x))
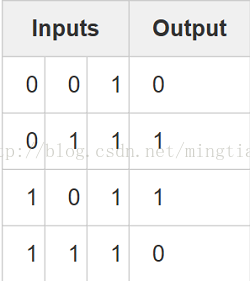
X = np.array([[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]])
y = np.array([[0],
[1],
[1],
[0]])
np.random.seed(1)
# randomly initialize our weights with mean 0
syn0 = 2*np.random.random((3,4)) - 1
syn1 = 2*np.random.random((4,1)) - 1
for j in xrange(60000):
# Feed forward through layers 0, 1, and 2
l0 = X
l1 = nonlin(np.dot(l0,syn0))
l2 = nonlin(np.dot(l1,syn1))
# how much did we miss the target value?
l2_error = y - l2
if (j% 10000) == 0:
print "Error:" + str(np.mean(np.abs(l2_error)))
# in what direction is the target value?
# were we really sure? if so, don't change too much.
l2_delta = l2_error*nonlin(l2,deriv=True)
# how much did each l1 value contribute to the l2 error (according to the weights)?
l1_error = l2_delta.dot(syn1.T)
# in what direction is the target l1?
# were we really sure? if so, don't change too much.
l1_delta = l1_error * nonlin(l1,deriv=True)
syn1 += l1.T.dot(l2_delta)
syn0 += l0.T.dot(l1_delta)
Error:0.496410031903
Error:0.00858452565325
Error:0.00578945986251
Error:0.00462917677677
Error:0.00395876528027
Error:0.00351012256786翻译中包含了一些自己的理解~














 509
509











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









