







本文为学习TensorFlow时的一些笔记和注意事项。
1.TensorFlow的基本使用
使用图来表示计算任务
在被称之为会话(Session) 的上下文中执行图
使用张量(Tensor)来表示数据
通过变量(Variable)维护状态
使用feed和fetch可以为任意的操作赋值或者从其中获取数据
上面这些话是copy的极客学院的tf的中文文档。我对此的理解是,tf这个框架的运行方式,不同于以往我熟悉的C++,Python等语言。它是先构建出一个计算图,这个图的每个节点,就是一个操作,在操作中使用的参数称作变量,存储数据的结构叫做张量。
通俗点说,张量就是你读入进来进行运算的数据,而变量,就是你在程序中声明的一些参数,有固定的作用域。对于一个深度学习的网络来说,你首先需要构建出这个网络图,然后创建一个会话,在会话中执行这个图。
import tensorflow as tf
sess = tf.InteractiveSession() #创建会话
init = tf.global_variables_initializer() #创建初始化的节点
sess.run(init) #执行这个节点的操作一些基本的操作就不说了,tf使用的版本是1.0,一些老版本的方法已经不一样了,在这也做一点记录。下面说一下tf里非常重要的变量作用域以及共享变量的问题。
2. 变量作用域和共享变量
为什么需要使用变量作用域和共享变量呢?因为如果你不使用,每个变量都使用tf.Variable()创建,那么对于一个有3层的神经网络,你就需要写3个weights和3个biases,如果这个网络有100层,那你就需要写100*2个变量。
看了不少论文的源码,发现大家都使用了变量作用域的机制。tf中的这种机制主要由两部分组成:
tf.get_variable(<name>, <shape>, <initialzier>) #创建或者获取一个变量
tf.variable_scope(<scope_name>) #指定命名空间对于tf.get_variable()方法,如果一个变量不存在,你就会创建一个变量,如果存在的话,它就会检测是否共享,如果已经共享,那么就会获取以前创建的,否则就会报ValueError,比如:(此例摘自官方文档)
def my_image_filter(input_images):
with tf.variable_scope("conv1"):
# Variables created here will be named "conv1/weights", "conv1/biases".
relu1 = conv_relu(input_images, [5, 5, 32, 32], [32])
with tf.variable_scope("conv2"):
# Variables created here will be named "conv2/weights", "conv2/biases".
return conv_relu(relu1, [5, 5, 32, 32], [32])
result1 = my_image_filter(image1)
result2 = my_image_filter(image2)
# Raises ValueError(... conv1/weights already exists ...)这个错误我也是碰到了好多遍,花了好久理解和调试,才解决了。上述问题是因为没有指定共享变量,所以只要使用reuse_variables()方法来指定共享即可。
result1 = my_image_filter(image1)
tf.get_variable_scope().reuse_variables() #在作用域中共享变量
result2 = my_image_filter(image2)如果想要深入理解这两个方法是如何工作的,可以参考TensorFlow官方文档中文版
我在写代码中遇到的一些问题,如下:

这个问题造成的原因是,这个变量已经创建过了,并且我的代码里面没有做任何共享变量的操作,所以就炸裂了,但是我在每个variable_scope中都加了reuse = True之后,又提示出了变量不存在的错误。这是因为,第一次创建变量,其实是在上面全局变量初始化的地方做的,也就是:
sess = tf.InteractiveSession()
init = tf.global_variables_initializer()
sess.run(init)实际上第一次变量创建的地方是在sess.run(init),而我所有的reuse都设置为了True,表示一直都是去获取以前的变量。而我在init的时候并没有创建过变量呢,所以就出现了不存在的错误。并且要提及的一点是,在下面train的过程中,是一轮一轮的训练,和共享变量是没有关系的,所以不用担心在train的时候会造成变量已经存在的问题。
当然,github上很多代码,都没有设置reuse = True这个参数,为什么没有出现变量已存在的问题呢?
正如我上面所说,正常情况起初是变量都不存在的,在全局初始化的时候,变量被创建了,然后在下面的train中,也不会出现变量已存在的错误,所以是可以正常运行的。那我为啥出现了错误呢,我想应该是与我使用的IDE有关吧,我是用的是ipython notebook,所以说珍爱生命,在用TensorFlow的时候不要用ipython notebook。
为了避免上述的ValueError的问题,我在代码中进行了改进,如下是我在写CNN中的卷积层的代码:
def conv2d(value, output_dim, k_h = 5, k_w = 5, strides = [1,2,2,1], name = 'conv2d'):
with tf.variable_scope(name):
try:
weights =tf.get_variable( 'weights',
[k_h, k_w, value.get_shape()[-1], output_dim],
initializer = tf.truncated_normal_initializer(stddev = 0.02))
biases = tf.get_variable( 'biases',
[output_dim],initializer = tf.constant_initializer(0.0))
except ValueError:
tf.get_variable_scope().reuse_variables()
weights =tf.get_variable( 'weights',
[k_h, k_w, value.get_shape()[-1], output_dim],
initializer = tf.truncated_normal_initializer(stddev = 0.02))
biases = tf.get_variable( 'biases',
[output_dim],initializer = tf.constant_initializer(0.0))
conv = tf.nn.conv2d(value, weights, strides = strides, padding = 'SAME')
conv = conv + biases
return conv使用了try之后,如果碰到ValueError,就共享一下变量,这样就可以防止各种莫名原因导致的错误了。
3.模型的存储
可以使用tf.train.Saver()来创建一个Saver管理模型中的变量
sess = tf.InteractiveSession() #创建会话
init_op = tf.global_variables_initializer() #创建初始化的节点
saver = tf.train.Saver() #创建Saver
sess.run(init_op) #初始化所有变量
save_path = saver.save(sess, "/tmp/model.ckpt") #保存图中所有的变量存储之后,文件夹里会出现4个文件,所有的变量会存储在checkpoint文件中,并且是以name和值的形式存储(name是指创建时候的参数name)
恢复变量
saver = tf.train.Saver()
saver.restore(sess, "/tmp/model.ckpt") #需要存在同名的变量,不然需要在声明saver是用一个dictionary设定
下面是我自己的例子,前面已经保存过一个model.ckpt了,里面的v1为全0
import tensorflow as tf
import os
v1 = tf.Variable(tf.constant(1.0, shape = [5]), name="v1")
v2 = tf.Variable(tf.truncated_normal(shape = [3,2], stddev=0.02), name="v2")
init_op = tf.global_variables_initializer()
sess = tf.InteractiveSession()
saver = tf.train.Saver()
sess.run(init_op)
print(sess.run(v1)) #输出[1,1,1,1,1]
saver.restore(sess, "data/model.ckpt")
print(sess.run(v1)) #输出[0,0,0,0,0]
再测试一下修改了name之后读取变量的例子:
import tensorflow as tf
import os
v1 = tf.Variable(tf.constant(1.0, shape = [5]), name="v1")
v2 = tf.Variable(tf.truncated_normal(shape = [3,2], stddev=0.02), name="v2")
init_op = tf.global_variables_initializer()
sess = tf.InteractiveSession()
saver = tf.train.Saver({"vv1":v1}) #变量v1的name修改为vv1
sess.run(init_op)
saver.save(sess, "data/model.ckpt")
import tensorflow as tf
import os
v1 = tf.Variable(tf.constant(0.0, shape = [5]), name="v1")
v2 = tf.Variable(tf.truncated_normal(shape = [3,2], stddev=0.02), name="v2")
init_op = tf.global_variables_initializer()
sess = tf.InteractiveSession()
saver = tf.train.Saver({"vv1":v1})
sess.run(init_op)
print(sess.run(v1)) #输出[0,0,0,0,0]
saver.restore(sess, "data/model.ckpt")
print(sess.run(v1)) #输出[1,1,1,1,1]首先我在第一个代码中,存储name为vv1,值为1.0的一个向量,第二个代码中,添加的dictionary的意思是name为vv1的变量的值赋给v1变量,所以就产生了上述结果。
我们发现,其实 创建 saver对象时使用的键值对就是表达了一种对应关系:
- save时, 表示:variable的值应该保存到 checkpoint文件中的哪个 key下
- restore时,表示:checkpoint文件中key对应的值,应该restore到哪个variable
4.TensorBoard可视化
这部分内容,我也仅仅是尝试了一下一些源码,自己还没写过类似的。
d_loss_real_sum = tf.summary.scalar("d_loss_real", d_loss_real)
d_loss_fake_sum = tf.summary.scalar("d_loss_fake", d_loss_fake)
d_loss_sum = tf.summary.scalar("d_loss", d_loss)
g_loss_sum = tf.summary.scalar("g_loss", g_loss)tf.summary.scalar()用于生成标量数据的summary,如下图所示:
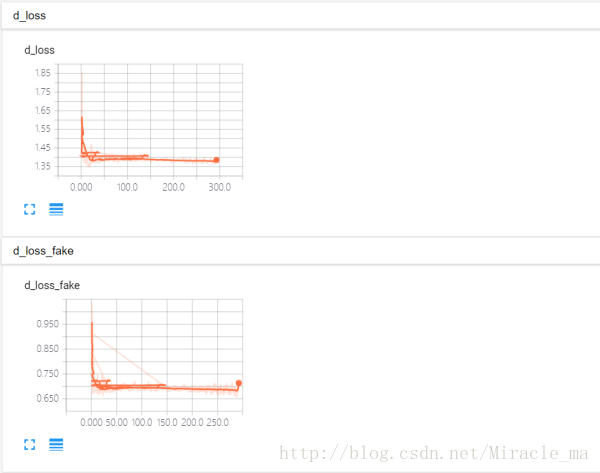
tf.summary.image(tag, tensor, max_images=3, collections=None, name=None):tensor,必须4维,形状[batch_size, height, width, channels],max_images(最多只能生成3张图片的summary),觉着这个用在卷积中的kernel可视化很好用.max_images确定了生成的图片是[-max_images: ,height, width, channels],还有一点就是,TensorBord中看到的image summary永远是最后一个global step的。
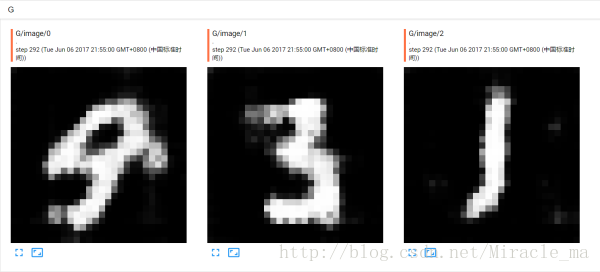
G_sum = tf.summary.image("G", G)在tensorboard中显示是这样的:
tensorboard还可以生成整个计算图,虽然我还不是很清楚怎么读这张图
在代码里,首先要用FileWriter创建一个file writer用来向硬盘写summary数据
writer = tf.summary.FileWriter(train_dir, sess.graph)然后每一次有参数被修改,都要用add_summary向FileWriter对象的缓存中存放event data。
如果使用writer.add_summary(summary,global_step)时没有传global_step参数,会使scarlar_summary变成一条直线。
在代码中写好了这些之后,就可以在命令行里启动tensorboard了,命令是
tensorboard --logdir="logs/" #放在当前文件夹的logs文件夹下
然后在浏览器中打开http://192.168.1.109:6006就好了














 944
944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









