| Problem A very common feature of any social site (and other types of application) is to find the latest activity of one’s friends. Another related example is to fetch the latest data for people or topics that one follows. You may think that databases would make it easy to implement such a feature, but unfortunately it is far from being easy. Many new NoSQL stores do not really support secondary indexes, which are necessary for this feature. In the case of MongoDB it is possible to do it efficiently but it presents many pitfalls. | 译者信息 问题 任何社交网站(和其他类型的应用)的一个非常常见的特征是找到朋友的最新动态。另一个相关的例子是获取一个人关注的人或者话题的最新数据。你也许认为数据库可以很简单的实现这样的特征,但不幸的是离简单还很远。 许多新的NoSQL存储不支持辅助索引,而这个特征需要辅助索引。对于MongoDB,高效的处理这个问题是可以的,但存在很多缺陷。 |
| Fetching the friends’ ids The first step is to fetch the list of the user’s friends ids. The friendship relationship is typically either embedded into the user document (as a list of user ids) or in a mapping table (SQL style). In both cases it is assumed the application can quickly put together the list of friends’ ids. The ideal query The intuitive query should look like this:
db.posts.find({ userId: { $in: [12, 24, 56, …] } }).sort({ date: -1 }).limit(100)
Notes:
- it is much better to use “$in“ rather than “$or“. Latter does not use indexes properly when combined with a sort.
- the sort is for descending time, to obtain the most recent
- the limit tells that we are only interested in the last 100 documents.
| 译者信息 获取朋友的id 第一步是获取用户朋友id列表。朋友关系一般不是嵌入用户文档(以用户id列表的形式)就是在一个映射表中(SQL风格)。在两种情况下,都假设应用可以快速的把朋友id列表放在一起。 理想的查询 直觉上的查询应该像这样:
db.posts.find({ userId: { $in: [12, 24, 56, …] } }).sort({ date: -1 }).limit(100)
注意:
- 使用“$in"比"$or"更好。后者在和排序结合时,无法合理使用索引。
- 排序sort是为了以时间降序的方式来获得最新的信息
- limit说明我们仅对最新的100个文档感兴趣
|
| For such a query the best index is a compound “{ userId: 1, date: 1}“. Note that it is not important whether it is ascending or descending on the date. What is expected? Ideally MongoDB will take the following steps:
- go to each friend’s branch of the index.
- pick the 100 most recent documents within each, which is fast thanks to the compound on “date“.
- apply an in-memory sort on those documents (e.g. merge 1000 documents for 10 friends, which is fast) and then return the most recent 100.
The following diagram shows what should ideally happen. 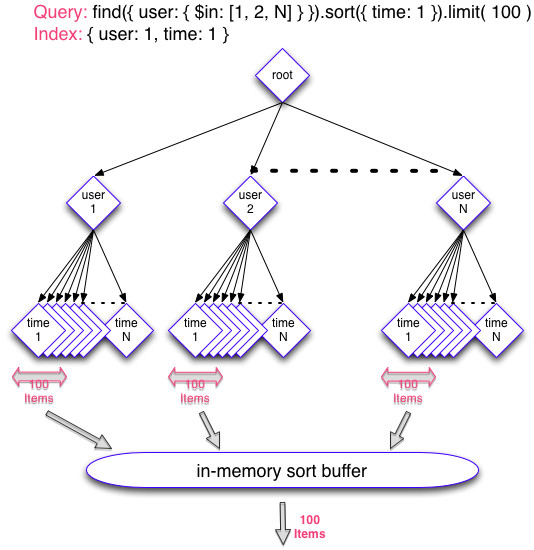 | 译者信息 对于这样的一个查询,最好的索引是"{ userId: 1, date: 1}"组合。注意是否在时间上升序或降序并不重要。 什么是期望的呢?理想情况下,MongoDB将有以下步骤:
- 进入各个朋友的索引分支
- 在各个分支内挑出100个最新的文档,由于组合中的“date“,处理速度非常快。
- 对这些文档在内存里排序(例如,对于10个朋友,可以很快合并得到1000个文档),然后返回最新的100个。
下面的流程图展示了理想情况下应该发生的过程。
|
| The “limit“ problem One debatable design decision was to not pass the “limit“ value into the query protocol. Instead only the “batchSize“ is communicated, which tells the server how many results to return in the next batch but omits to say that no more results are needed. If you set a limit of 100 then the “batchSize“ gets set to 100 but the server assumes you may ask for more than 100 records, and keeps the cursor open on the server. In turn it makes it impossible for the server to reduce the amount of records sorted: it must sort in-memory *all* your friends’ documents *since the beginning of times*. The fix is to use a negative limit: if set to -100 then it will be passed to the server as a negative “batchSize“ value. It tells the server: send me only 1 batch with a maximum of 100 documents and do not keep the cursor open. One caveat to this solution is that a batch cannot exceed 16MB, so the 100 documents must fit within 16MB (which is likely). | 译者信息 “limit”问题 一个还在争论的设计决定是在查询协议中不通过“limit”值。仅使用“batchSize”的交流来替代,它告诉服务器在下一批中返回多个结果,但忽略去说不需要更多的结果。 如果你设置限制是100,那么“batchSize”就被设置为100,但服务器假定你可能会请求多于100的记录,并保持服务器端的指针开放。反过来,这使得服务器无法减少排序的记录数量:它必须在*开始时*在内存中把*所有的*朋友文档排序。 解决方法是使用一个负的限制:如果设为-100,那么它将作为一个负的“batchSize”值传给服务器。它告诉服务器:1批仅仅给我发送最多100份文档,不要保持指针开发。这个方法的一个警告是一个批量不能超过16MB,所以这100份文档必须在16MB以内(这是有可能的)。 |
| The problem with MongoDB 2.0 With MongoDB 2.0 (which hopefully you’re not using anymore at this time) the behavior still won’t be the one expected. It will just continue to disregard the limit and always resort to sort all documents since day 1. As a consequence the queries will get slower and slower over time, which is a big no-no. The following diagram shows the bad behavior. 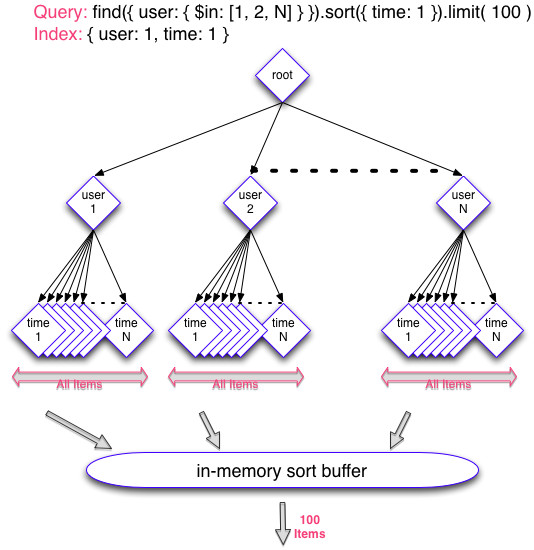 | 译者信息 MongoDB 2.0的问题 使用MongoDB 2.0(希望你这次不再使用),性能依旧无法达到期望。它就是继续忽视限制,总是从第一天开始就重复排序所有文档。结果就是查询会变得越来越慢,而这是个巨大的禁忌。 下面的流程图展示这个不好的性能。 |
| The limited fix with MongoDB 2.2 and 2.4 A limited fix was implemented in 2.2. The following query will work as expected and return within milliseconds:
db.posts.find({ userId: { $in: [12, 24, 56, …] } }).sort({ date: -1 }).limit(-100)
So you may think that it is all good… unfortunately a big limitation is that any extra predicate may turn off the optimization. Any extra predicate must be an equality (or a “$in“) on a field that is part of the index to the left side of the field sorted on (“date“ in this case). If you want to only see posts that have specific properties (e.g. “private: False“) you must be very careful how you build the index:
db.posts.find({ userId: { $in: [12, 24, 56, …], private: False } }).sort({ date: -1 }).limit(-100)
It must use an index on “{ userId: 1, private: 1, date: 1 }“. A different type of predicate, or against a field not covered by the correct portion of the index will put you back in the bad slow case. This issue will be fixed as part of the 2.6 index internal API refactoring, which you should look forward to! | 译者信息 对 MongoDB 2.2 和 2.4 的有限修复
2.2版本实现了一种有限的修复。下面的查询语句将如您所愿的工作,并在数毫秒内返回结果:
db.posts.find({ userId: { $in: [12, 24, 56, …] } }).sort({ date: -1 }).limit(-100)
那么你可能要想了这已经完美无缺……不幸的是有一个很大的局限,就是任何额外的谓词断言都会关闭优化机制。任何额外的谓词断言必须是某个字段上的等式(或者 “$in“),这个字段是索引的一部分,位于索引字段(本例中是“date“ )的左边。如果你想看到特定属性(例如“private: False“)的posts,那就必须很小心的构建索引:
db.posts.find({ userId: { $in: [12, 24, 56, …], private: False } }).sort({ date: -1 }).limit(-100)
它必须打开“{ userId: 1, private: 1, date: 1 }“之上的索引。某种不同类型的谓词断言,或者相反的这个字段没有被索引的正确部分所覆盖,那么这将使你回到那种很糟很慢的情形。 这个问题将会被2.6版本的索引内部API重构所解决,这应该正是你期待的! |
| A solution: add a predicate on sorted field One solution is to also specify a date range, which will properly limit how much data gets sorted. For example:
db.posts.find({ userId: { $in: [12, 24, 56, …] }, date: { $gt: x, $lt: y } }).sort({ date: -1 }).limit(-100)
The obvious problem is that you don’t know what date range will yield enough / too much results… You can first query for the past day, then go back in time with increasing ranges if not enough data is returned. | 译者信息 一个解决方案:在索引字段上增加谓词断言 一个解决方案是,指定一个日期范围,这将可能会限制需要排序的数据量。 例如:
db.posts.find({ userId: { $in: [12, 24, 56, …] }, date: { $gt: x, $lt: y } }).sort({ date: -1 }).limit(-100)
明显的问题在于,你并不知道什么样的时间范围可以获得足够/太多的结果……你可以先查询前一天的,然后如果返回数据不够的话,再回溯时间将时间范围扩大。
|
| A solution: multiple queries To properly make full use of the index, a solution is to split the query into many queries, one per friend id. In that case MongoDB can properly iterate through the sorted index without doing extra work. The queries would be:
db.posts.find({ userId: 12, … } }).sort({ date: -1 }).limit(-100)
db.posts.find({ userId: 24, … } }).sort({ date: -1 }).limit(-100)
…
The client code will then do the sort of the separate results, which is fast to do. Any predicate can be added to filter the data further, and should be part of the right side of the “date“ in the index. Unfortunately this solution only works well if the number of friends is fairly low. Each query should return within a millisecond, but with 100 friends you can be looking at several milliseconds already. The good news is that the speed will remain the same over time, but there is some extra overhead for sure. Overall it is a good solution if the number of friends under 100 on average. | 译者信息 一个解决方案: 多个查询 为了充分利用索引,一个解决方案是,将查询分割为许多个查询,每个朋友id一个。这样的话MongoDB 就能在已排序的索引上正确的迭代,而不需要额外的工作。 查询应该是:
db.posts.find({ userId: 12, … } }).sort({ date: -1 }).limit(-100)
db.posts.find({ userId: 24, … } }).sort({ date: -1 }).limit(-100)
…
客户端代码将在这之后对各个结果进行索引,这个很快。可以增加任何谓词断言进一步过滤数据,而且在索引中应该在“date“的右边位置部分。 不幸的是,这个解决方案只有在朋友数极少的时候才能工作得很好。每个查询会在一毫秒内返回,但是100个朋友的话,就可能已经有数毫秒了。好消息是速度将会一直保持在同样的水平,不过当然也有一些额外的代价。总体而言,一般如果朋友数小于100的话,这是一个不错的解决方案。 |
| A solution: fan out An alternative strategy is to duplicate the data into each of the friend’s own data. When a user posts an update, it is duplicated into 1 document for each of the friends. Consequently the problematic query becomes easy:
db.posts.find({ userId: 7 }).sort({ date: -1 }).limit(-100)
The obvious downside is the large duplication of content. If a user has 10k followers, the data will generate 10k documents written to the database. | 译者信息 一个解决方案: 扇出(fan out) 一个替代的策略是将数据复制到每个朋友的自己数据之中。当一个用户发帖有更新,它将会被复制到每个朋友的1个文档之中。因此有问题的查询变得容易了:
db.posts.find({ userId: 7 }).sort({ date: -1 }).limit(-100)
明显的负面因素是,内容的大量复制。如果一个用户有10k个关注者,这个数据将会产生10k个文档写到数据库中。 |
| Conclusion In conclusion, either:
- use the 2.2 optimization but be very careful about its implementation
- use one of the alternative solutions above… each has pros / cons.
Expect MongoDB 2.6 to give you full intuitive support for this! One ticket to watch is SERVER-3310. | 译者信息 结论 结论是, 二者选一:
- 使用 2.2 的优化机制,但是对它的实现要非常小心
- 用上面的某个替代解决方案……每个都有优点/缺点
希望 MongoDB 2.6 能给你对这个问题的完全的直接支持! 看看这个网址 SERVER-3310。 |























 2399
2399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









