







|
接上一篇博客
人工智能实战——人工神经网络(C库iOS交叉编译),这篇博客之前发布在qq空间一直没挪过来...
回顾下第一个例子中我用到NN(神经网络)的地方:
假设了一个目标函数 f = x==y ,设计了一个3层结构的神经网络,经过训练让神经网络自己学会如果判断两个数相等。 由于目标函数只有2个变量和一个结果,因此网络结构的输入元件只有2个,输出元件只有1个,并且输出元件的区间是[-1,1]. 然而这个例子太过于简单,仅作为刚接触人工智能的一个小小的入门试探而已。接下来是时候展现人工神经的魅力所在了。把NN运用到真正适合他的场景,比如文章归类、图像识别、语音识别、用户喜好筛选等实际场景。 这篇文章就要揭开图像识别的神秘面纱,从0开始教会人工大脑如何识别手写符号,然后是手写数字,终极挑战是识别出手写汉字。在开始这篇文章前,我们先分析文字识别的几种方式: 1.能够获取用户下笔的顺序,每一笔画的方向,轻重等信息,从而将用户的笔画提取成坐标+向量集合,然后作为输入源给NN,训练NN,输出正确的结果。 2.无法获取用户下笔的顺序,轻重等信息(往往是拍照、扫描得来的图片),将图片进行简单的处理,去除噪点,黑白化,然后将各个像素点的灰度值建立成矩阵或数组,作为输入源给NN,训练NN,输出正确的结果。 方式1一般用于客户端上的手势识别,比如浏览器的手势操作等,手写输入法等,缺点是一旦无法获取下笔顺序基本上没啥用处了,通用性低。 方式2一般用于纸质文档的数字化,也就是我们常说的OCR(光学字符识别),缺点是a.需要庞大的训练数据(如果你要识别所有中国人的手写体,你需要所有中国人的手写体训练数据,包括医生开的处方^^) b.对图片的去噪、裁边、黑白过程比较难处理或者耗时间。 这里我选择了方式2,因为方式2的普适性比较高,那么首先我们的程序就需要做一点点调整: 用于识别一张图片中包含单个手写符号(假设我们来识别0~9的数字,那么一共有10中不同的输出)的程序,图片尺寸是100x100,那么这个图片就包含10000个像素点,每个像素点都有自己的颜色,输入源应该是一个100x100的矩阵,输出源要能表示10种不同的结果。 10000个像素点作为10000个输入源太庞大了,因此我们要把原始图片的质量降低一点,比如我把所有的图片压缩到16*16个像素(追求识别的精度应该扩大尺寸,牺牲性能),用来识别简单的图像。 输出的值如果是0~9的10个数字,那么输出元件如果只能输出0或1的话,我们至少需要2^4=16个排列,因此我们需要4个输出元件。 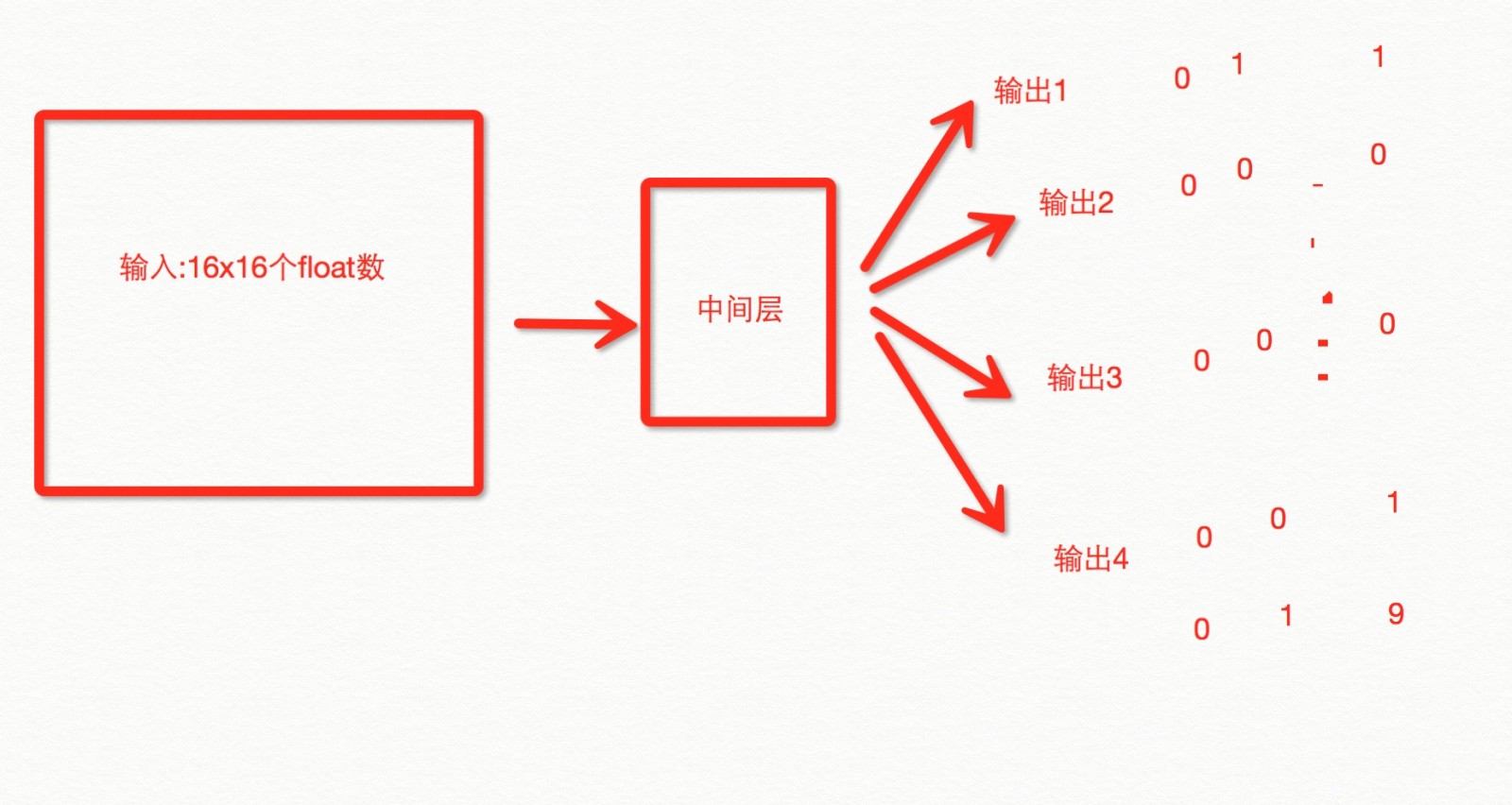 这个过程看其实无非是我们第一个程序的例子中2个输入变成了16x16个,1个输出变成了4个输出,仅此而已!!而他能做的事情却发生了天翻地覆的变化。。。。这就是NN解决问题的魅力所在 只不过这次我们不能让用户从16x16个文本框中一个个来输入,而是直接让用户画,所以首先我们创建画图控件~继承UIView,用贝塞尔曲线+touchEvents可以很快写出来: // // XYDrawingView.m // 小歪 // // Created by reese on 16/3/23. // Copyright © 2016年 com.ifenduo. All rights reserved. // #import "XYDrawingView.h" @interface XYDrawingView () //所有的贝塞尔曲线 @property (nonatomic) NSMutableArray *lines; //当前的贝塞尔曲线 @property (nonatomic) UIBezierPath *currentPath; @end @implementation XYDrawingView - (NSMutableArray *)lines { if (!_lines) { _lines = [NSMutableArray array]; } return _lines; } //重写drawRect方法 - (void)drawRect:(CGRect)rect {
//设置描边颜色为黑色 [[UIColor blackColor] setStroke]; for (UIBezierPath *bezierPath in self.lines) { //设置线条粗细为20 [bezierPath setLineWidth:20.0f]; //设置转角类型为圆滑 [bezierPath setLineJoinStyle:kCGLineJoinRound]; //描边 [bezierPath stroke]; } } //触摸开始 - (void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event { CGPoint p = [[touches anyObject] locationInView:self];
//构建新的贝塞尔曲线 _currentPath = [UIBezierPath bezierPath];
//移动到第一个点 [_currentPath moveToPoint:p];
//添加到线段数组 [self.lines addObject:_currentPath]; } //移动 - (void)touchesMoved:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event { CGPoint p = [[touches anyObject] locationInView:self];
//从当前点到上一个点连接出一条线段 [_currentPath addLineToPoint:p];
//重绘 [self setNeedsDisplay]; } .h文件是空的 就不列出来了。有了这个控件之后我们可以开始画符号了,在控制器中添加这个控件: 搞定后,我们就要讲写字区中的图像转化为数字信号,也就是刚刚说的16x16矩阵了(这里16别写死,方便我们提高精度) 转换函数: //将self.layer携带的图像信息转化成size x size容量的 float数组 - (fann_type *)getImageToBinaryForSize:(CGSize)size {
//1.渲染self.layer
//根据自身的frame大小开一个绘图上下文 UIGraphicsBeginImageContext(self.bounds.size); //获取到这个上下文 CGContextRef ctx = UIGraphicsGetCurrentContext(); //渲染layer [self.layer renderInContext:ctx]; //从上下文中导出image对象(压缩前的image,比如我们的绘图区大小是200x200,这个image的size至少是200*200,如果是retina屏幕更大) UIImage* oImage = UIGraphicsGetImageFromCurrentImageContext(); //关闭第一个上下文 UIGraphicsEndImageContext();
//2.压缩至size x size 大小
//创建一个size x size大小的上下文 UIGraphicsBeginImageContext(size); //获取到这个小号的上下文 ctx = UIGraphicsGetCurrentContext();
//把刚刚导出的image对象draw到这个小一号的上下文中,这个过程是有损压缩,压缩后还原会失真,也就是会有马赛克 [oImage drawInRect:CGRectMake(0, 0, size.width, size.height)];
//导出压缩成目标尺寸的图片,并转换成CGImageRef CGImageRef image = UIGraphicsGetImageFromCurrentImageContext().CGImage;
//关闭第二个上下文 UIGraphicsEndImageContext(); //由CGImageRef转换为16进制数据 CFDataRef data = CGDataProviderCopyData(CGImageGetDataProvider(image));
//获取数据长度(长度不一定等于size*size*4,当size为8的倍数的时候,长度等于size*size*4,其中每一个元素为2个16进制数,2个16进制数正好是一字节) NSInteger length = CFDataGetLength(data);
//获取颜色数组 UInt8 *colors = (UInt8 *)CFDataGetBytePtr(data);
//分配一个和长度相等的目标float数组空间 fann_type *binaryArr = malloc(sizeof(fann_type) * CFDataGetLength(data));
//遍历每个像素 for (long i = 0; i < length; i++) {
//第i个像素对应的r,g,b,a色值分别为colors[i*4],colors[i*4+1],colors[i*4+2],colors[i*4+3],因为这是个数组 long index = i*4;
// 对于彩色转灰度,有一个很著名的心理学公式:
//Gray = R*0.299 + G*0.587 + B*0.114
//这里我们简化下算法,不去计算灰度,直接用红色通道的色值来识别 fann_type r = (CGFloat)colors[index] /255.0; binaryArr[i] = r;
} return binaryArr; } 写完之后,打一个断电观察下data的结构: 其中0xf4efefff是我在storyboard中给这个view的背景颜色,其他颜色则是我绘制出来的线条颜色的rgba值。 由于UInt8正好是一个字节,一个字节等于2个16进制数,所以每一个colors元素对应一个颜色分量。 最后我们期望得到一个恰当的16x16维数组, 那么当我们画完图之后,点击执行,输出最终得到的float数组,并按16个为一行折行,修改我们第一个例子中的执行函数: - (IBAction)test:(id)sender { // fann_type input[2] = {_input1.text.floatValue,_input2.text.floatValue}; // NSArray *output = [[XYRobotManager sharedManager] runInputDatas:input]; // [_output setText:[output.firstObject stringValue]];
//压缩的size int size = 16;
//获取手写区图像的红色通道色值数组 fann_type* colors = [_drawingView getImageToBinaryForSize:CGSizeMake(size, size)];
//i为列,j为行 for (int i = 0; i < size; i++) { for (int j = 0; j < size; j++) { printf("%.0f ",colors[i*size+j]); } //每列换行 printf("\n"); } } 接下来我们拿到这个数组后,16x16的输入源有了,那么就可以构造一个新的NN,然后训练小Y让他学会认字~过程就简单了 具体过程下篇文章再写^^ 未完待续 |














01-29
01-16
 1010
1010
1010
07-06
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









