







今天带大家实现java中读写xml的操作,不说废话,直接进入主题吧
这里读取xml分为四种情况
- JAVA官方提供的
DOM: 一次性将整个xml文件加载到内存中,进行解析
SAX: 逐层向下解析 - 需要引入对应的jar包
DOM4J, JDOM
读取xml
我们分别做解析,先来看看需要我们解析的xml文件内容
<?xml version="1.0" encoding="UTF-8"?>
<Peoples>
<people id="1">
<name>张三</name>
<age>22</age>
<job>医生</job>
</people>
<people id="2">
<name>李四</name>
<age>33</age>
<job>老师</job>
</people>
</Peoples>使用Dom读取xml
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.StringWriter;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
private static void readXmlByDom() {
try {
// 1. 创建DocumentBuilderFactory对象
DocumentBuilderFactory dFactory = DocumentBuilderFactory.newInstance();
// 2. 创建DocumentBuilder对象
DocumentBuilder dBuilder = dFactory.newDocumentBuilder();
// 3. 通过DocumentBuilder的parse方法解析xml
org.w3c.dom.Document doc = dBuilder.parse("people.xml");
// 4. 根据根节点名称获取所有的people节点
org.w3c.dom.NodeList peopleList = doc.getElementsByTagName("people");
// 5. 遍历所有的people节点
for (int i = 0; i < peopleList.getLength(); i++) {
System.out.println(peopleList.item(i).getNodeName());
Node peopleNode = peopleList.item(i);
// A. 获取所有的属性名称 和 对应的属性值
org.w3c.dom.NamedNodeMap namedNodeMap = peopleNode.getAttributes();
// B. 遍历people的所有属性
for (int j = 0; j < namedNodeMap.getLength(); j++) {
System.out.println("属性 ="+namedNodeMap.item(j).getNodeName()+" :值 = "+namedNodeMap.item(j).getNodeValue());
}
NodeList nodeList = peopleNode.getChildNodes();
for (int k = 0; k < nodeList.getLength(); k++) {
Node node = nodeList.item(k);
if (node.getNodeType() == Node.ELEMENT_NODE) {
System.out.println("节点名:"+node.getNodeName()+ " 节点值:"+node.getFirstChild().getNodeValue());
// System.out.println("节点名:"+node.getNodeName()+ " 节点值:"+node.getTextContent());
}
}
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
此时效果如下:

使用Sax读取xml
import java.io.IOException;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SaxTest {
public static void main(String[] args) {
try {
// 1. 获取SAXParserFactory实例
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
// 2. 获取SAXParser实例
SAXParser saxParser = saxParserFactory.newSAXParser();
// 3. 加载xml实例
saxParser.parse("people.xml", new SelfHandler());
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
static class SelfHandler extends DefaultHandler {
/**
* 遍历xml文件的开始标签
*/
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes)
throws SAXException {
super.startElement(uri, localName, qName, attributes);
if ("people".equals(qName)) {
for (int i = 0; i < attributes.getLength(); i++) {
System.out.println("people 标签第"+(i+1)+" 个属性名是:"+attributes.getQName(i)+" 属性值是: "+attributes.getValue(attributes.getQName(i)));
}
} else if (!"peoples".equals(qName) && !"people".equals(qName)) {
System.out.print("节点名是: "+qName+"------");
}
}
/**
* 遍历xml文件的结束标签
*/
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
super.endElement(uri, localName, qName);
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
super.characters(ch, start, length);
String value = new String(ch, start,length);
if (!"".equals(value.trim())) {
System.out.println("节点值是: "+value);
}
}
/**
* 标识解析开始
*/
@Override
public void startDocument() throws SAXException {
super.startDocument();
System.out.println("开始sax解析.......");
}
/**
* 标识解析结束
*/
@Override
public void endDocument() throws SAXException {
super.endDocument();
System.out.println("结束sax解析.......");
}
}
}
此时效果如下:

使用Jdom读取xml
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
import org.jdom.Document;
import org.jdom.Attribute;
import org.jdom.Element;
import org.jdom.JDOMException;
import org.jdom.input.SAXBuilder;
import org.jdom.output.XMLOutputter;
private static void readXmlByJdom() {
try {
// 1. 创建org.jdom.input.SAXBuilder对象
SAXBuilder saxBuilder = new SAXBuilder();
// 2. 创建一个输入流, 用来加载xml文件
InputStream ins = new FileInputStream("people.xml");
org.jdom.Document document = saxBuilder.build(ins);
// 3. 获取根节点
Element rootElement = document.getRootElement();
// 4. 获取根节点下的子节点
List<Element> lists = rootElement.getChildren();
for (Element people : lists) {
// A.获取所有的属性
// System.out.println("====属性值:"+people.getAttributeValue("id"));
List<Attribute> attributeList = people.getAttributes();
for (Attribute element : attributeList) {
System.out.println("属性名:"+element.getName()+"====属性值:"+element.getValue());
}
// B. 遍历people节点下所有的节点名和节点值
List<Element> childList = people.getChildren();
for (Element object : childList) {
System.out.println("节点名:"+object.getName()+"========节点值:"+object.getValue());
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (JDOMException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
此时效果如下:

使用Dom4J读取xml
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.UnsupportedEncodingException;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
private static void readXmlByDom4J() {
try {
// 1. 创建org.dom4j.io.SAXReader对象
SAXReader saxReader = new SAXReader();
InputStream ins = new FileInputStream("people.xml");
Document document = saxReader.read(ins);
Element rootElement = document.getRootElement();
System.out.println("根节点的名称是:"+rootElement.getName());
Iterator iterator = rootElement.elementIterator();
while (iterator.hasNext()) {
Element element = (Element) iterator.next();
// 获取所有属性名和属性值
List<Attribute>attributesList = element.attributes();
for (Attribute attribute : attributesList) {
System.out.println("属性名:"+attribute.getName()+"======属性值"+attribute.getValue());
}
// 遍历子节点
Iterator childIterator = element.elementIterator();
while (childIterator.hasNext()) {
Element child = (Element) childIterator.next();
System.out.println("属性名:"+child.getName()+"======属性值"+child.getStringValue());
}
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}此时读取到的效果如下:

需要注意的是,jdom和dom4j需要引入对应的jar文件
写入xml
使用Dom写入xml
private static void writeXmlByDom() {
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.newDocument();
//创建属性名、赋值
Element root = document.createElement("peoples");
//创建第一个根节点、赋值
Element lan = document.createElement("people");
lan.setAttribute("id", "1");
Element name = document.createElement("name");
name.setTextContent("张三");
Element ide = document.createElement("age");
ide.setTextContent("45");
lan.appendChild(name);
lan.appendChild(ide);
//创建第二个根节点、赋值
Element lan2 = document.createElement("lan");
lan2.setAttribute("id", "2");
Element name2 = document.createElement("name");
name2.setTextContent("李四");
Element ide2 = document.createElement("age");
ide2.setTextContent("88");
lan2.appendChild(name2);
lan2.appendChild(ide2);
//添加到属性中、
root.appendChild(lan);
root.appendChild(lan2);
document.appendChild(root);
//定义了用于处理转换指令,以及执行从源到结果的转换的
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer transformer = transformerFactory.newTransformer();
transformer.setOutputProperty("encoding", "UTF-8");
StringWriter writer = new StringWriter();
transformer.transform(new DOMSource(document), new StreamResult(writer));
// System.out.println(writer.toString());
transformer.transform(new DOMSource(document), new StreamResult(new File("D:/newxml.xml")));
} catch (ParserConfigurationException | TransformerException e) {
e.printStackTrace();
}
}这里创建”D:/newxml.xml”这样的xml文件,效果如下:

使用JDom写入xml
private static void writeXmlByJdom() {
//定义一个root作为xml文档的根元素
Element root = new Element("peoples");
//生成一个文档
Document Doc = new Document(root);
for (int j = 1; j <= 3; j++) {
Element elements = new Element("people");
//设置属性名和属性值
elements.setAttribute("id", "" + j);
elements.addContent(new Element("name").setText("张三"));
elements.addContent(new Element("age").setText("22"));
elements.addContent(new Element("job").setText("老师"));
//将已经设置好值的elements赋给root
root.addContent(elements);
}
//定义一个用于输出xml文档的类
XMLOutputter XMLOut = new XMLOutputter();
try {
//将生成的xml文档Doc输出到文件
XMLOut.output(Doc, new FileOutputStream("d:/jdompeople.xml"));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}此时写入的文件内容如下:

使用Dom4j写入xml
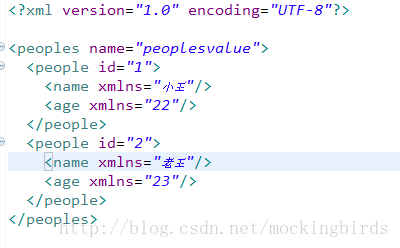
private static void writeXmlByDom4J() {
try {
// 创建文档并设置文档的根元素节点
Element root = DocumentHelper.createElement("peoples");
Document document = DocumentHelper.createDocument(root);
//根节点
root.addAttribute("name","peoplesvalue");
//子节点
Element element1 = root.addElement("people");
element1.addAttribute( "id", "1" );
element1.addElement("name", "小王");
element1.addElement("age","22");
Element element2 = root.addElement("people");
element2.addAttribute( "id", "2" );
element2.addElement("name", "老王");
element2.addElement("age","23");
//添加
XMLWriter xmlwriter2 = new XMLWriter();
xmlwriter2.write(document);
//创建文件
OutputFormat format = new OutputFormat();
format = OutputFormat.createPrettyPrint();
//设定编码
format.setEncoding("UTF-8");
XMLWriter xmlwriter = new XMLWriter(new FileOutputStream("d:/dom4jpeople.xml"), format);
xmlwriter.write(document);
xmlwriter.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
} 此时使用dom4j写入的xml内容如下:
好了,今天就到这里啦,好久没写代码了,以后要坚持,睡觉了
源码下载














 1294
1294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









