










我之前推荐过大家使用
seimiagent+seimicrawler,但是经过我多次试验,在爬取任务过多,比如线程数超过几十的时候,seimiagent会经常崩溃,当然这也和启动seimiagent的服务器有关。
鉴于seimiagent的性能不适合普通装备的爬虫爱好者,我重新写了一款quick-spring+selenium的最简爬虫案例,供大家参考。
项目地址
https://github.com/a252937166/quick-selenium.git
项目介绍
框架
quick-spring
便于在main()方法中使用spring和mybatis的相关语法,具体介绍详见:https://github.com/a252937166/quick-springselenium
这就不用多介绍了吧,百度一搜就知道了,用来解析网页的框架。
结构
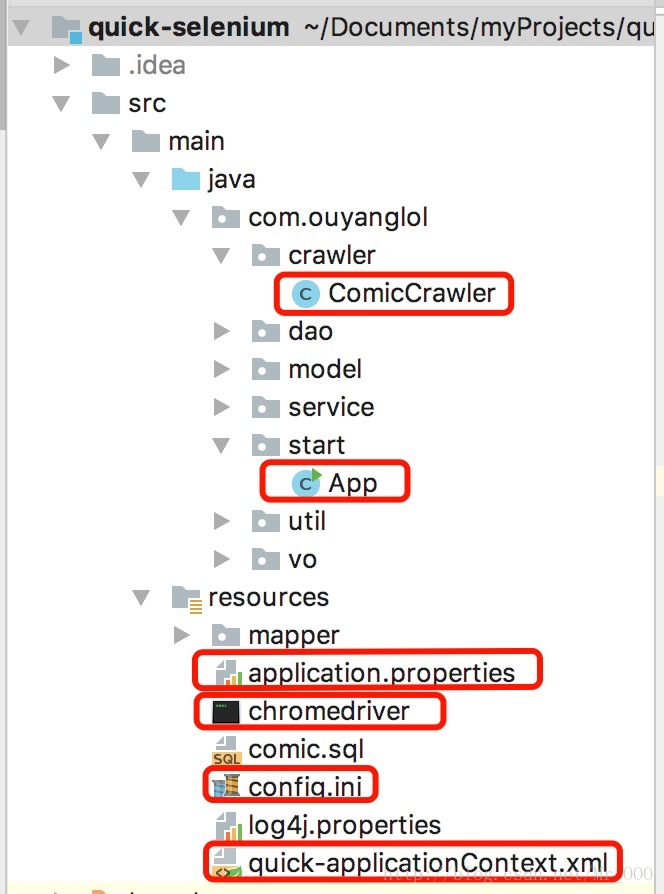
比较重要的文件我都勾画出来了。
ComicCrawler.java
控制每个网页的具体爬虫逻辑。App.java
爬虫启动类。application.properties
一些关键的配置信息,根据你自己的配置修改就行了。chromedriver
我这里上传的是linux环境的驱动器,如果是你是windows系统,请到http://npm.taobao.org/mirrors/chromedriver/自己下载。config.ini
网页驱动器的配置文件,比如你要选择哪一种驱动器,我这里选中的是chromedriver,因为目前根据我的测试,它要比phantomjs稳定一点。quick-applicationContext.xml
可以自己修改一些连接池的配置。
快速启动
修改配置文件
根据自己的配置,修改好application.properties、config.ini、quick-applicationContext.xml的内容。
qiniu_cdn这些不用管,这是我把爬到的内容上传到七牛云的时候用到的。
WebDriverPool.java
找到
private static final String DEFAULT_CONFIG_FILE = "/Users/Ouyang/Documents/myProjects/quick-selenium/src/main/resources/config.ini";
修改为自己的config.ini的路径。
App.java
package com.ouyanglol.start;
import com.ouyanglol.core.QuickBase;
import com.ouyanglol.crawler.ComicCrawler;
/**
* Package: com.ouyanglol.start
*
* @Author: Ouyang
* @Date: 2018/2/2
*/
public class App {
public static void main(String[] args) throws Exception {
System.getProperties().setProperty("webdriver.chrome.driver", "/Users/Ouyang/Documents/myProjects/chromedriver");
QuickBase quickBase = QuickBase.getInstance("crawler");
ComicCrawler crawler = (ComicCrawler) quickBase.getQuick("ComicCrawler");
crawler.start("https://manhua.dmzj.com/yiquanchaoren/");//一拳超人爬虫开始网址
}
}修改
System.getProperties().setProperty("webdriver.chrome.driver", "/Users/Ouyang/Documents/myProjects/chromedriver");为自己的chromedriver的路径,如果使用phantomjs就不用了,phantomjs的配置在config.ini里面声明。
填写自己的爬虫开始路径。
crawler.start("https://manhua.dmzj.com/yiquanchaoren/");ComicDriver.java
一定要注意使用webDriver.quit();,根据我多次的实验,长时间启动多个webDriver,不退出的话,也容易导致驱动器崩溃。
如果你们电脑配置过低,浏览器多次崩溃,不妨取消
// if (i%50==0) {
// webDriver.quit();
// webDriver = webDriverPool.get();
// }这一段的注释,每解析50个网页就启动一个新的驱动器。
ComicContentService.java
qiniuUtil.uploadImg(fileName,imageUrl,chapterUrl);//把图片保存到七牛云,图片的处理方式可以自己决定
没有七牛云的同学,可以把这段代码注释,以免报错。
comic.sql
运行其中sql,初始化数据库,最后启动App.java中的main()方法就可以了。
同系列文章
java爬虫系列(一)——爬虫入门
java爬虫系列(二)——爬取动态网页
java爬虫系列(三)——漫画网站爬取实战
java爬虫系列(五)——今日头条文章爬虫实战














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









