







索引:
二、查询
三、表表达式
四、集合运算
六、数据修改
七、事务和并发
八、可编程对象
一、SQL Server体系结构
1.1 数据库的物理布局
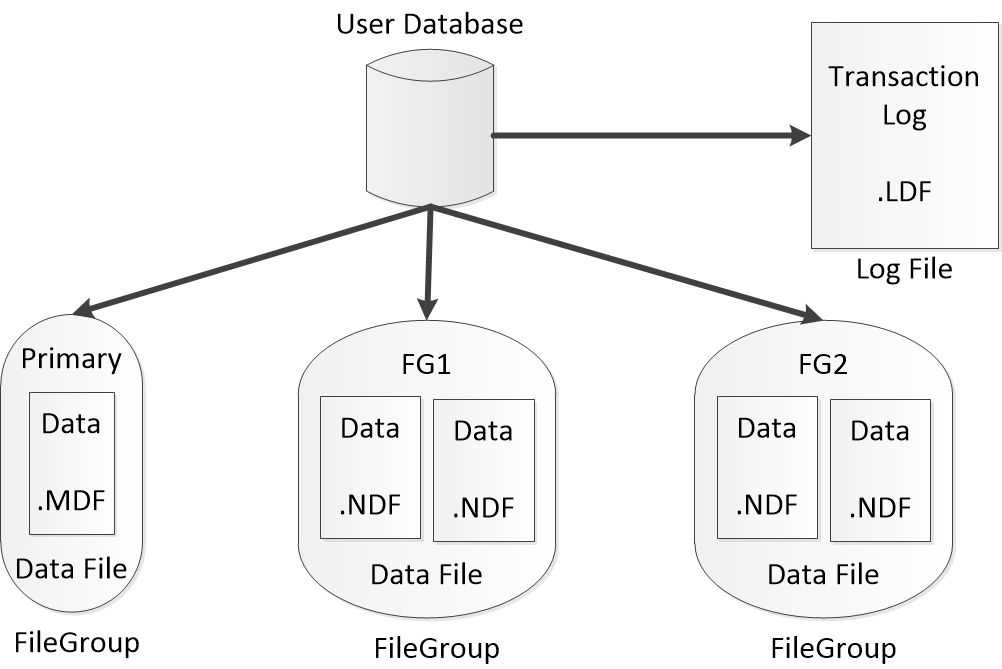
数据库在物理上由数据文件和事务日志文件组成,每个数据库必须至少有一个数据文件和一个日志文件。
(1)数据文件用于保存数据库对象数据。数据库必须至少有一个主文件组(Primary),而用户定义的文件组则是可选的。Primary文件组包括 主数据文件(.mdf),以及数据库的系统目录(catalog)。可以选择性地为Primary增加多个辅助数据文件(.ndf)。用户定义的文件组只能包含辅助数据文件。
(2)日志文件则用于保存SQL Server为了维护事务而需要的信息。虽然SQL Server可以同时写多个数据文件,但同一时刻只能以顺序方式写一个日志文件。
.mdf、.ldf和.ndf
.mdf代表Master Data File,.ldf代表Log Data File,而.ndf代表Not Master Data File(非主数据文件)
1.2 架构(Schema)和对象
一个数据库包含多个架构,而每个架构又包括多个对象。可以将架构看作是各种对象的容器,这些对象可以是表(table)、视图(view)、存储过程(stored procedure)等等。
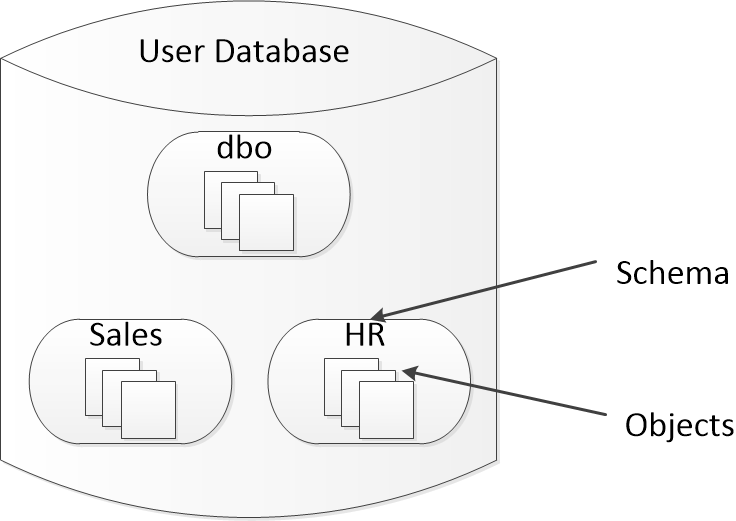
此外,架构也是一个命名空间,用作对象名称的前缀。例如,架设在架构Sales中有一个Orders表,架构限定的对象名称是Sales.Orders。如果在引用对象时省略架构名称,SQL Server将采用一定的办法来分析出架构名称是什么。如果不显示指定架构,那么在解析对象名称时,就会要付出一些没有意义的额外代价。因此,建议都加上架构名称。
二、查询
2.1 单表查询
(1)关于SELECT子句:使用*号是糟糕的习惯
SELECT * FROM Sales.Shippers;在绝大多数情况下,使用星号是一种糟糕的编程习惯,在此还是建议大家即使需要查询表的所有列,也应该显式地指定它们。
(2)关于FROM子句:显示指定架构名称
通过显示指定架构名称,可以保证得到的对象的确是你原来想要的,而且还不必付出任何额外的代价。
(3)关于TOP子句:T-SQL独有关键字
① 可以使用PERCENT关键字按百分比计算满足条件的行数
SELECT TOP (1) PERCENT orderid, orderdate, custid, empid
FROM Sales.Orders
ORDER BY orderdate DESC;上面这条SQL就会请求最近更新过的前1%个订单。
② 可以使用WITH TIES选项请求返回所有具有相同结果的行
SELECT TOP (5) WITH TIES orderid, orderdate, custid, empid
FROM Sales.Orders
ORDER BY orderdate DESC;上面这条SQL请求返回与TOP n行中最后一行的排序值相同的其他所有行。
(4)关于OVER子句:为行定义一个窗口以便进行特定的运算
OVER子句的优点在于能够在返回基本列的同时,在同一行对它们进行聚合;也可以在表达式中混合使用基本列和聚合值列。
例如,下面的查询为OrderValues的每一行计算当前价格占总价格的百分比,以及当前价格占客户总价格的百分比 。
SELECT orderid, custid, val,
100.0 * val / SUM(val) OVER() AS pctall,
100.0 * val / SUM(val) OVER(PARTITION BY custid) AS pctcust
FROM Sales.OrderValues;(5)子句的逻辑处理顺序
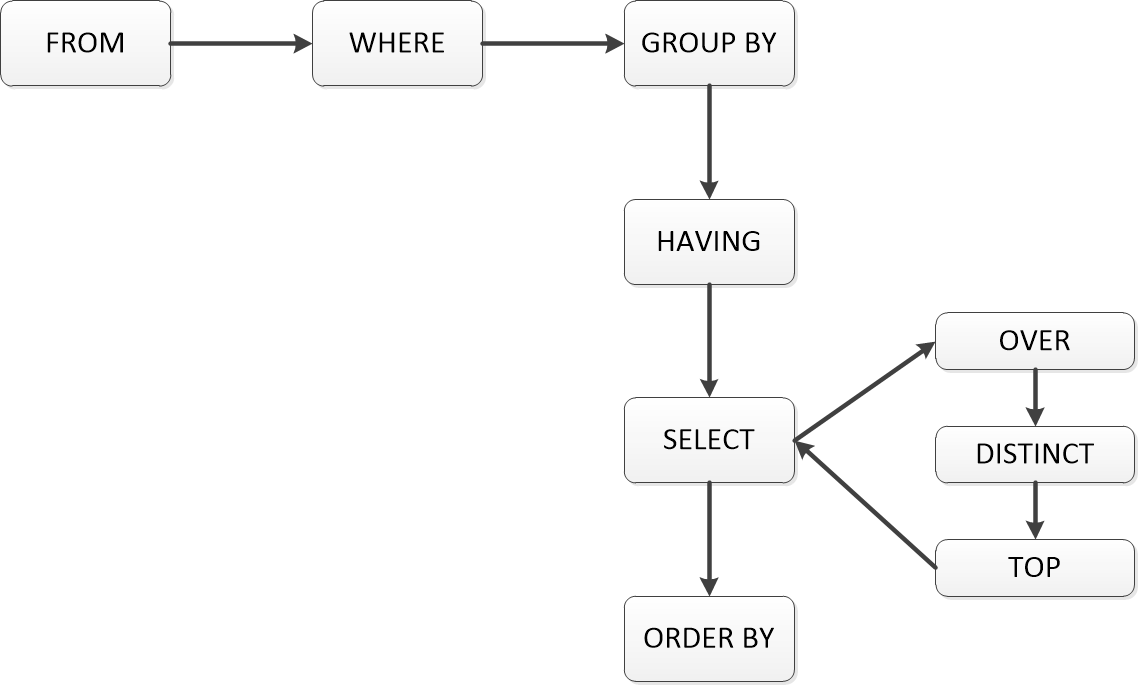
(6)运算符的优先级

(7)CASE表达式
① 简单表达式:将一个值与一组可能的取值进行比较,并返回满足第一个匹配的结果;
SELECT productid,productname,categoryid,categoryname=(
CASE categoryid
WHEN 1 THEN 'Beverages'
WHEN 2 THEN 'Condiments'
WHEN 3 THEN 'Confections'
WHEN 4 THEN 'Dairy Products'
ELSE 'Unkonw Category'
END)
FROM Production.Products;② 搜索表达式:将返回结果为TRUE的第一个WHEN逻辑表达式所关联的THEN子句中指定的值。如果没有任何WHEN表达式结果为TRUE,CASE表达式则返回ELSE子句中出现的值。(如果没有指定ELSE,则默认返回NULL);
SELECT orderid, custid, val, valuecategory=(
CASE
WHEN val < 1000.00 THEN 'Less than 1000'
WHEN val BETWEEN 1000.00 AND 3000.00 THEN 'Between 1000 and 3000'
WHEN val > 3000.00 THEN 'More than 3000'
ELSE 'Unknown'
END
)
FROM Sales.OrderValues(8)三值谓词逻辑:TRUE、FALSE与UNKNOWN
SQL支持使用NULL表示缺少的值,它使用的是三值谓词逻辑,代表计算结果可以使TRUE、FALSE与UNKNOWN。在SQL中,对于UNKNOWN和NULL的处理不一致,这就需要我们在编写每一条查询语句时应该明确地注意到正在使用的是三值谓词逻辑。
例如,我们要请求返回region列不等于WA的所有行,则需要在查询过滤条件中显式地增加一个队NULL值得测试:
SELECT custid, country, region, city
FROM Sales.Customers
WHERE region <> N'WA'
OR region IS NULL;另外,T-SQL对于NULL值得处理是先输出NULL值再输出非NULL值得顺序,如果想要先输出非NULL值,则需要改变一下排序条件,例如下面的请求:
select custid, region
from sales.Customers
order by (case
when region is null then 1 else 0
end), region;当region列为NULL时返回1,否则返回0。非NULL值得表达式返回值为0,因此,它们会排在NULL值(表达式返回1)的前面。如上所示的将CASE表达式作为第一个拍序列,并把region列指定为第二个拍序列。这样,非NULL值也可以正确地参与排序,是一个完整解决方案的查询。
(9)LIKE谓词的花式用法
① %(百分号)通配符
SELECT empid, lastname
FROM HR.Employees
WHERE lastname LIKE N'D%';② _(下划线)通配符:下划线代表任意单个字符
下面请求返回lastname第二个字符为e的所有员工
SELECT empid, lastname
FROM HR.Employees
WHERE lastname LIKE N'_e%';③ [<字符列>]通配符:必须匹配指定字符中的一个字符
下面请求返回lastname以字符A、B、C开头的所有员工
SELECT empid, lastname
FROM HR.Employees
WHERE lastname LIKE N'[ABC]%';④ [<字符-字符>]通配符:必须匹配指定范围内中的一个字符
下面请求返回lastname以字符A到E开头的所有员工:
SELECT empid, lastname
FROM HR.Employees
WHERE lastname LIKE N'[A-E]%';⑤ [^<字符-字符>]通配符:不属于特定字符序列或范围内的任意单个字符
下面请求返回lastname不以A到E开头的所有员工:
SELECT empid, lastname
FROM HR.Employees
WHERE lastname LIKE N'[^A-E]%';⑥ ESCAPE转义字符
如果搜索包含特殊通配符的字符串(例如'%','_','['、']'等),则必须使用转移字符。下面检查lastname列是否包含下划线:
SELECT empid, lastname
FROM HR.Employees
WHERE lastname LIKE N'%!_%' ESCAPE '!';(10)两种转换值的函数:CAST和CONVERT
CAST和CONVERT都用于转换值的数据类型。
SELECT CAST(SYSDATETIME() AS DATE);
SELECT CONVERT(CHAR(8),CURRENT_TIMESTAMP,112);需要注意的是,CAST是ANSI标准的SQL,而CONVERT不是。所以,除非需要使用样式值,否则推荐优先使用CAST函数,以保证代码尽可能与标准兼容。
2.2 联接查询
(1)交叉联接:返回笛卡尔积,即m*n行的结果集
-- CROSS JOIN
select c.custid, e.empid
from sales.Customers as c
cross join HR.Employees as e;
-- INNER CROSS JOIN
select e1.empid,e1.firstname,e1.lastname,
e2.empid,e2.firstname,e2.lastname
from hr.Employees as e1
cross join hr.Employees as e2;(2)内联接:先笛卡尔积,然后根据指定的谓词对结果进行过滤
select e.empid,e.firstname,e.lastname,o.orderid
from hr.Employees as e
join sales.Orders as o
on e.empid=o.empid;虽然不使用JOIN这种ANSI SQL-92标准语法也可以实现联接,但强烈推荐使用ANSI SQL-92标准,因为它用起来更加安全。比如,假如你要写一条内联接查询,如果不小心忘记了指定联接条件,如果这时候用的是ANSI SQL-92语法,那么语法分析器将会报错。

(3)外联结:笛卡尔积→对结果过滤→添加外部行
通过例子来理解外联结:根据客户的客户ID和订单的客户ID来对Customers表和Orders表进行联接,并返回客户和他们的订单信息。该查询语句使用的联接类型是左外连接,所以查询结果也包括那些没有发出任何订单的客户;
--LEFT OUTER JOIN
select c.custid,c.companyname,o.orderid
from sales.Customers as c
left outer join sales.Orders as o
on c.custid=o.custid;另外,需要注意的是在对外联结中非保留值得列值进行过滤时,不要再WHERE子句中指定错误的查询条件。
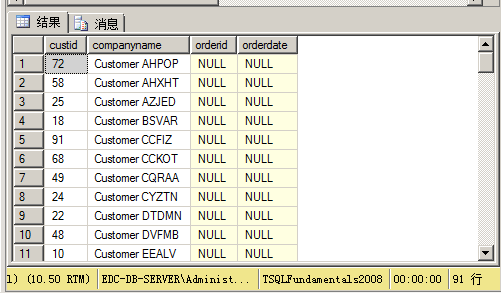
例如,下面请求返回在2007年2月12日下过订单的客户,以及他们的订单。同时也返回在2007年2月12日没有下过订单的客户。这是一个典型的左外连接的案例,但是我们经常会犯这样的错误:
select c.custid,c.companyname,o.orderid,o.orderdate
from sales.Customers as c
left outer join sales.Orders as o
on c.custid=o.custid
where o.orderdate='20070212';执行结果如下:
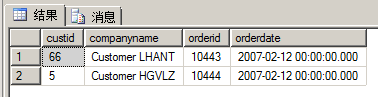
这是因为对于所有的外部行,因为它们在o.orderdate列上的取值都为NULL,所以WHERE子句中条件o.orderdate='20070212'的计算结果为UNKNOWN,因此WHERE子句会过滤掉所有的外部行。
我们应该将这个条件搬到on后边:
select c.custid,c.companyname,o.orderid,o.orderdate
from sales.Customers as c
left outer join sales.Orders as o
on c.custid=o.custid
and o.orderdate='20070212';这下的执行结果如下:
2.3 子查询
(1)独立子查询:不依赖于它所属的外部查询
例如下面要查询Orders表中订单ID最大的订单信息,这种叫做独立标量子查询,即返回值不能超过一个。
select orderid, orderdate, empid, custid
from sales.Orders
where empid=(select MAX(o.orderid) from sales.Orders as o);西面请求查询返回姓氏以字符D开头的员工处理过的订单的ID,这种叫做独立多值子查询,即返回值可能有多个。
select orderid
from sales.Orders
where empid in (select e.empid
from hr.Employees as e
where e.lastname like N'D%');(2)相关子查询:必须依赖于它所属的外部查询,不能独立地调用它
例如下面的查询会返回每个客户的订单记录中订单ID最大的记录:
select custid, orderid, orderdate, empid
from sales.Orders as o1
where orderid=(select MAX(o2.orderid)
from sales.Orders as o2
where o2.custid=o1.custid);简单地说,对于o1表中的每一行,子查询负责返回当前客户的最大订单ID。如果o1表中某行的订单ID和子查询返回的订单ID匹配,那么o1中的这个订单ID就是当前客户的最大订单ID,在这种情况下,查询便会返回o1表中的这个行。
(3)EXISTS谓词:它的输入是一个查询,如果子查询能够返回任何行,则返回True,否则返回False
例如下面的查询会返回下过订单的西班牙客户:
select custid, companyname
from sales.customers as c
where c.country=N'Spain' and exists (
select * from sales.Orders as o
where o.custid=c.custid);同样,要查询没有下过订单的西班牙客户只需要加上NOT即可:
select custid, companyname
from sales.customers as c
where c.country=N'Spain' and not exists (
select * from sales.Orders as o
where o.custid=c.custid);对于EXISTS,它采用的是二值逻辑(TRUE和FALSE),它只关心是否存在匹配行,而不考虑SELECT列表中指定的列,并且无须处理所有满足条件的行。可以将这种处理方式看做是一种“短路”,它能够提高处理效率。
另外,由于EXISTS采用的是二值逻辑,因此相较于IN要更加安全,可以避免对NULL值得处理。
(4)高级子查询
① 如何表示前一个或后一个记录?逻辑等式:上一个->小于当前值的最大值;下一个->大于当前值的最小值;
-- 上一个订单ID
select orderid, orderdate, empid, custid,
(
select MAX(o2.orderid)
from sales.Orders as o2
where o2.orderid<o1.orderid
) as prevorderid
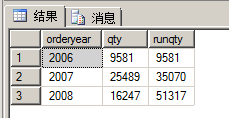
from sales.Orders as o1;② 如何实现连续聚合函数?在子查询中连续计算
-- 连续聚合
select orderyear, qty,
(select SUM(o2.qty)
from sales.OrderTotalsByYear as o2
where o2.orderyear<=o1.orderyear) as runqty
from sales.OrderTotalsByYear as o1
order by orderyear;执行结果如下图所示:
③ 使用NOT EXISTS谓词取代NOT IN隐式排除NULL值:当对至少返回一个NULL值的子查询使用NOT IN谓词时,外部查询总会返回一个空集。(前面提到,EXISTS谓词采用的是二词逻辑而不是三词逻辑)
-- 隐式排除NULL值
select custid,companyname from sales.Customers as c
where not exists
(select *
from sales.Orders as o
where o.custid=c.custid);又如以下查询请求返回每个客户在2007年下过订单而在2008年没有下过订单的客户:
select custid, companyname
from sales.Customers as c
where exists
(select * from sales.Orders as o1
where c.custid=o1.custid
and o1.orderdate>='20070101' and o1.orderdate<'20080101')
and not exists
(select * from sales.Orders as o2
where c.custid=o2.custid
and o2.orderdate>='20080101' and o2.orderdate<'20090101');三、表表达式
表表达式是一种命名的查询表达式,代表一个有效地关系表。可以像其他表一样,在数据处理中使用表表达式。MSSQL中支持4种类型的表表达式:
3.1 派生表
派生表(也称为表子查询)是在外部查询的FROM子句中定义的,只要外部查询一结束,派生表也就不存在了。
例如下面代码定义了一个名为USACusts的派生表,它是一个返回所有美国客户的查询。外部查询则选择了派生表的所有行。
select *
from (select custid, companyname
from sales.Customers
where country='USA') as USACusts;3.2 公用表表达式
公用表达式(简称CTE,Common Table Expression)是和派生表很相似的另一种形式的表表达式,是ANSI SQL(1999及以后版本)标准的一部分。
举个栗子,下面的代码定义了一个名为USACusts的CTE,它的内部查询返回所有来自美国的客户,外部查询则选择了CTE中的所有行:
WITH USACusts AS
(
select custid, companyname
from sales.Customers
where country=N'USA'
)
select * from USACusts;和派生表一样,一旦外部查询完成,CTE的生命周期也就结束了。
3.3 视图
派生表和CTE都是不可重用的,而视图和内联表值函数却是可重用,它们的定义存储在一个数据库对象中,一旦创建,这些对象就是数据库的永久部分。只有用删除语句显式地删除,它们才会从数据库中移除。
下面仍然继续上面的例子,创建一个视图:
IF OBJECT_ID('Sales.USACusts') IS NOT NULL
DROP VIEW Sales.USACusts;
GO
CREATE VIEW Sales.USACusts
AS
SELECT
custid, companyname, contactname, contacttitle, address,
city, region, postalcode, country, phone, fax
FROM Sales.Customers
WHERE country=N'USA';
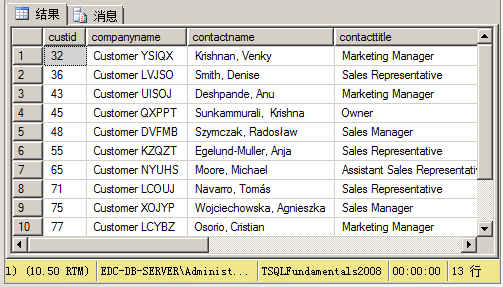
GO使用该视图:
SELECT * FROM Sales.USACusts;执行结果如下:
3.4 内联表值函数
内联表值函数能够支持输入参数,其他方面就与视图类似了。
下面演示如何创建函数:
IF OBJECT_ID('dbo.fn_GetCustOrders') IS NOT NULL
DROP FUNCTION dbo.fn_GetCustOrders;
GO
CREATE FUNCTION dbo.fn_GetCustOrders
(@cid AS INT) RETURNS TABLE
AS
RETURN
SELECT
orderid, custid, empid, orderdate, requireddate,
shippeddate, shipperid, freight, shipname, shipaddress, shipcity,
shipregion, shippostalcode, shipcountry
FROM Sales.Orders
WHERE custid=@cid;
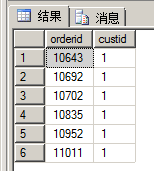
GO如何使用函数:
SELECT orderid, custid
FROM dbo.fn_GetCustOrders(1) AS CO;执行结果如下:
总结:
借助表表达式可以简化代码,提高代码地可维护性,还可以封装查询逻辑。
当需要使用表表达式,而且不计划重用它们的定义时,可以使用派生表或CTE,与派生表相比,CTE更加模块化,更容易维护。
当需要定义可重用的表表达式时,可以使用视图或内联表值函数。如果不需要支持输入,则使用视图;反之,则使用内联表值函数。
四、集合运算
4.1 UNION 并集运算
在T-SQL中。UNION集合运算可以将两个输入查询的结果组合成一个结果集。需要注意的是:如果一个行在任何一个输入集合众出现,它也会在UNION运算的结果中出现。T-SQL支持以下两种选项:
(1)UNION ALL:不会删除重复行
-- union all
select country, region, city from hr.Employees
union all
select country, region, city from sales.Customers; 结果得到100行:

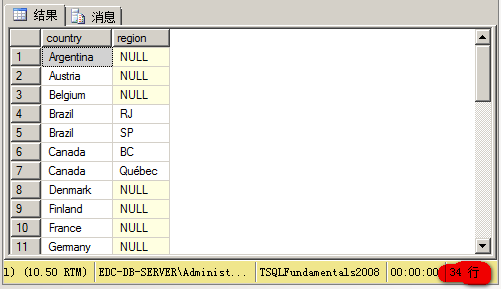
(2)UNION:会删除重复行
-- union
select country, region from hr.Employees
union
select country, region from sales.Customers; 结果得到34行:
4.2 INTERSECT 交集运算
在T-SQL中,INTERSECT集合运算对两个输入查询的结果取其交集,只返回在两个查询结果集中都出现的行。
INTERSECT集合运算在逻辑上会首先删除两个输入集中的重复行,然后返回只在两个集合中中都出现的行。换句话说:如果一个行在两个输入集中都至少出现一次,那么交集返回的结果中将包含这一行。
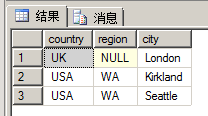
例如,下面返回既是官员地址,又是客户地址的不同地址:
-- intersect
select country, region, city from hr.Employees
intersect
select country, region, city from sales.Customers;执行结果如下图所示:
这里需要说的是,集合运算对行进行比较时,认为两个NULL值相等,所以就返回该行记录。
4.3 EXCEPT 差集运算
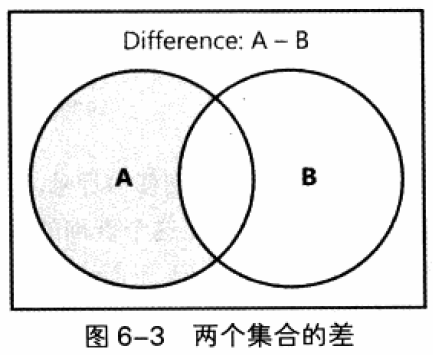
在T-SQL中,集合之差使用EXCEPT集合运算实现的。它对两个输入查询的结果集进行操作,反会出现在第一个结果集中,但不出现在第二个结果集中的所有行。
EXCEPT结合运算在逻辑上首先删除两个输入集中的重复行,然后返回只在第一个集合中出现,在第二个结果集中不出现的所有行。换句话说:一个行能够被返回,仅当这个行在第一个输入的集合中至少出现过一次,而且在第二个集合中一次也没出现过。
此外,相比UNION和INTERSECT,两个输入集合的顺序是会影响到最后返回结果的。
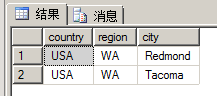
例如,借助EXCEPT运算,我们可以方便地实现属于A但不属于B的场景,下面返回属于员工抵制,但不属于客户地址的地址记录:
-- except
select country, region, city from hr.Employees
except
select country, region, city from sales.Customers;执行结果如下图所示:
4.4 集合运算优先级
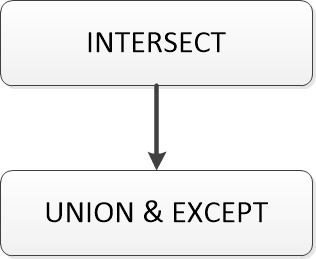
SQL定义了集合运算之间的优先级:INTERSECT最高,UNION和EXCEPT相等。
换句话说:首先会计算INTERSECT,然后按照从左至右的出现顺序依次处理优先级相同的运算。
-- 集合运算的优先级
select country, region, city from Production.Suppliers
except
select country, region, city from hr.Employees
intersect
select country, region, city from sales.Customers;上面这段SQL代码,因为INTERSECT优先级比EXCEPT高,所以首先进行INTERSECT交集运算。因此,这个查询的含义是:返回没有出现在员工地址和客户地址交集中的供应商地址。
4.5 使用表表达式避开不支持的逻辑查询处理
集合运算查询本身并不持之除ORDER BY意外的其他逻辑查询处理阶段,但可以通过表表达式来避开这一限制。
解决方案就是:首先根据包含集合运算的查询定义一个表表达式,然后在外部查询中对表表达式应用任何需要的逻辑查询处理。
(1)例如,下面的查询返回每个国家中不同的员工地址或客户地址的数量:
select country, COUNT(*) as numlocations
from (select country, region, city from hr.Employees
union
select country, region, city from sales.Customers) as U
group by country;(2)例如,下面的查询返回由员工地址为3或5的员工最近处理过的两个订单:
select empid,orderid,orderdate
from (select top (2) empid,orderid,orderdate
from sales.Orders
where empid=3
order by orderdate desc,orderid desc) as D1
union all
select empid,orderid,orderdate
from (select top (2) empid,orderid,orderdate
from sales.Orders
where empid=5
order by orderdate desc,orderid desc) as D2;参考资料

[美] Itzik Ben-Gan 著,成保栋 译,《Microsoft SQL Server 2008技术内幕:T-SQL语言基础》
考虑到很多人买了这本书,却下载不了这本书的配套源代码和示例数据库,特意上传到了百度云盘中,点此下载
强烈建议大家阅读完每一章节后,练习一下课后习题,相信或多或少都会有一些收获。
作者:周旭龙
出处:EdisonZhou -《MSSQL2008技术内幕:T-SQL语言基础》读书笔记(上) - EdisonZhou - 博客园EdisonZhou -
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接














 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









