







总觉得很多人会用个SQL Index就很装逼<( ̄3 ̄)>
主要学习了《Database System Concepts 6th》chapter 11
Problem Domain
“Find all instructors in the Physics department”
It is inefficient for the system to read every tuple in the instructor relation to check if the dept_name value is “Physics“.
要找个什么特定的东西,就全部扫一遍很亏
数据库索引=书的目录
Particular Topic (a word or a phrase), Sorted, Smaller
“Retrieve a student record given a ID”
Sorted List,一对一映射(最原始)
当有成千上万的学生时,索引本身也会变得很大,即使排序了,找起来也耗时
五个评价指标:Access types, Access time, Insertion time, Deletion time, Space overhead
「Search Key」「Records」
Search key, an attribute or set of attributes used to look up records.
e.g.search for a book by author, by subject, or by title.
1)Ordered Indices
大分类,based on a sorted ordering of the values
「有规则的Ordered」vs.「哈希Hash」
a)查询条件和记录的顺序一致性
If the file containing the records is sequentially ordered, a clustering index is an index whose search key also defines the sequential order of the file
「Cluster Index」=「Primary Index」
e.g.主键、英文排序的字段
「Index-Sequential File」,”自带索引的序列文件”
相对常见的一种,如教员表,{instructor_id, name, department, ……},其教员号自成索引且文件空间排序
Indices whose search key specifies an order different from the sequential order of the file are called.
「Non-clustering Index」=「Secondary Index」
b)索引稠密程度
「索引块Index Entry」or「Index Record」
带pointer的中间索引块,本身保存有查询条件,指针指向记录
本身也是个记录
索引稠密程度
「Dense Index」索引块和特征记录完全映射
可以剔除重复,比如部门类型{Biology, History, Finance……},索引块的长度等于类型数量
但对于唯一主键id,毫无卵用
Secondary Index必须为浓稠,因其顺序不一致
「Sparse Index」部分映射
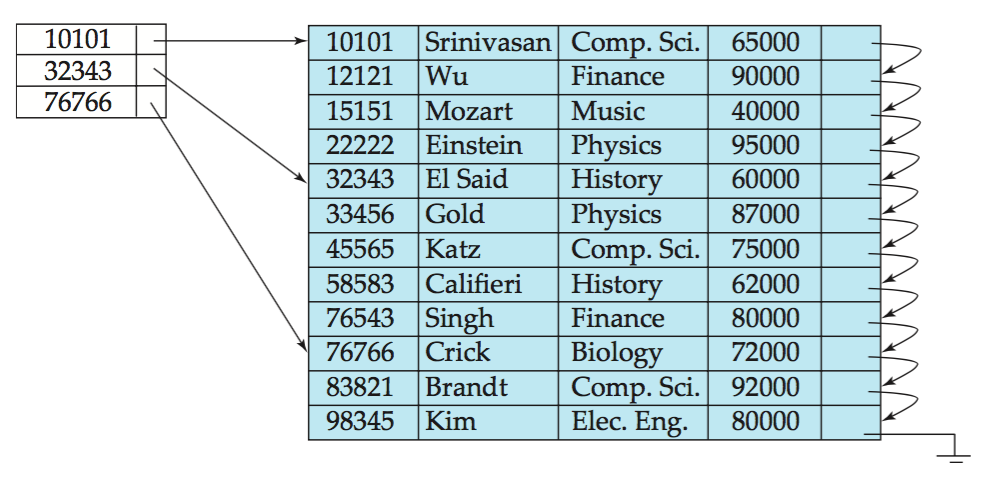
找45565,先比较找到比它小的”最大值”32343对应记录,之后依次遍历记录
「*」
c)多层映射
「Multilevel Index」「分层治」
Outer Index - N*Inner Index
Inner Index - M*Records
1 – N – N * M
2)B+ tree indices
不用说的,学习了July大神的http://blog.csdn.net/v_JULY_v/article/details/6530142
动态查找树主要有
「二叉查找树Binary Search Tree」「平衡二叉查找树Balanced Binary Search Tree」「红黑树Red-Black Tree」
二叉查找树结构,其查找的时间复杂度O(logN),与树深度直接相关
但因为二叉,树节点存储的元素数量有限,导致深度过深磁盘I/O读写过于频繁
「平衡树Balanced Tree」「B+ Tree」「B* Tree」
平衡多路查找树
B+树,最广泛,MySQL Index的默认配置
e.g. FileSystem, RDBS
A B+ tree can be viewed as a B-tree in which each node contains only keys (not key-value pairs), and to which an additional level is added at the bottom with linked leaves.
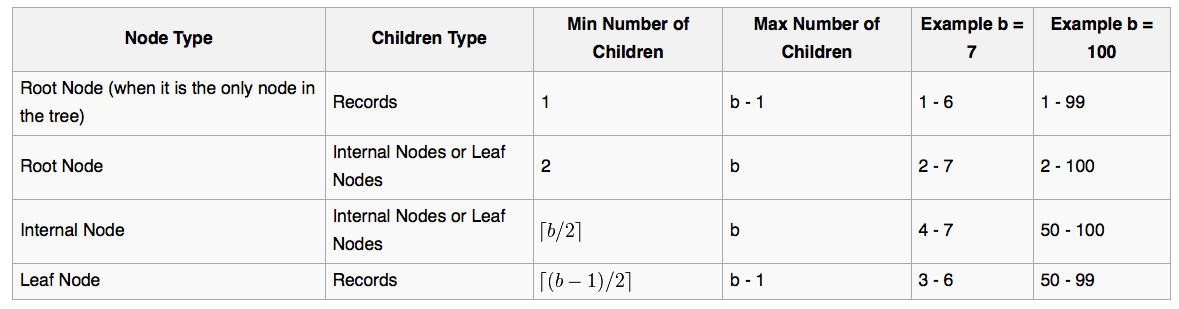
b,order or Balance Factor,measures the capacity of nodes (i.e., the number of children nodes) for internal nodes in the tree
关键字数量(=孩子数量=指针数量),e.g.Einstein,区别于其它树
如图,注意字母是排序的,索引也是有序分支的
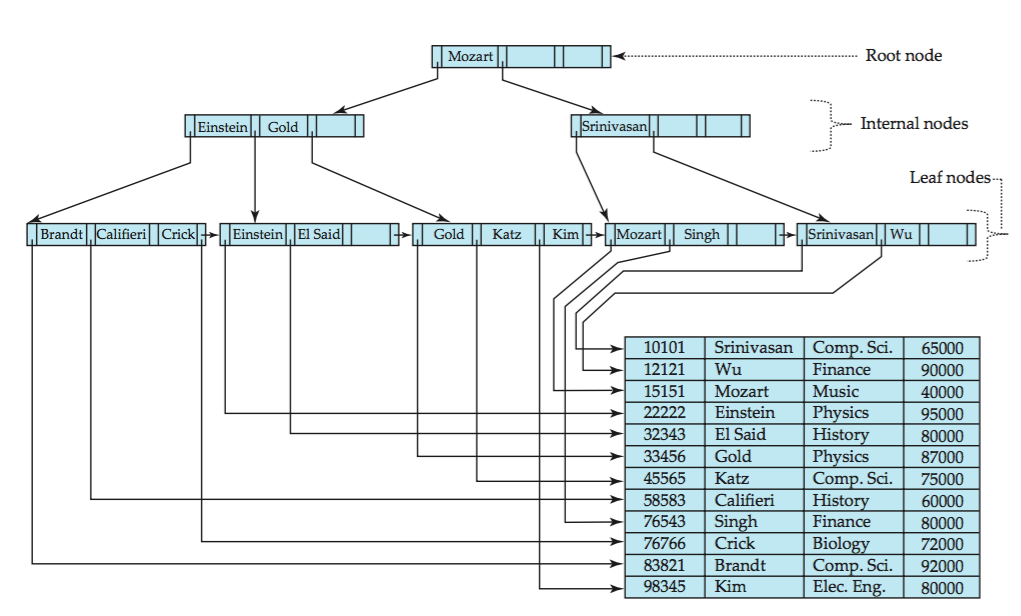
几点关于结构的特别注意
a)内部节点不存储关键字具体信息的指针,都在叶子节点
故而更多的内部节点(中间索引)可以被加载进内存,扫描盘块次数减少
而且可以平衡每次从根到页的查询,路径长度相等
b)叶子节点指针相连
只要遍历叶子节点就可以实现整棵树记录的遍历,B树则折腾要中序遍历,而这操作又是频繁的
「增删改查」
*「Indexing Strings」「Bulk Loading」等各种额外东西
「B tree indices」
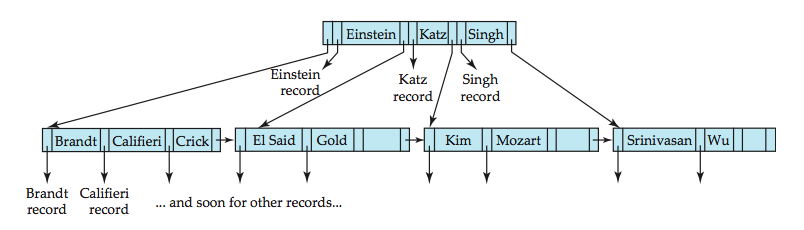
self-balancing tree data structure that keeps data sorted and allows searches, sequential access, insertions, and deletions in logarithmic time.
O(logn)
每个结点存放至少b/2-1(取上整)和至多b-1个关键字;(至少2个关键字)
(b, Balance Factor)
关键字数量=(孩子数量-1)=(指针数量-1)
「B* Tree」在B+树的基础上,B*树中非根和非叶子结点再增加指向兄弟的指针;B*树定义了非叶子结点关键字个数至少为(2/3)*b,即块的最低使用率为2/3(代替B+树的1/2)
(b, Balance Factor)
关键字数量=(孩子数量)=(指针数量-1)
各树性质区别总结的很清晰的博客
http://www.cnblogs.com/oldhorse/archive/2009/11/16/1604009.html
转自大神
B树的好处,就是成功查询特别有利,因为树的高度总体要比B+树矮。不成功的情况下,B树也比B+树稍稍占一点点便宜。有很多基于频率的搜索是选用B树,越频繁query的结点越往根上走,前提是需要对query做统计,而且要对key做一些变化。
B树:有序数组+平衡多叉树;
B+树:有序数组链表+平衡多叉树;
B*树:一棵丰满的B+树。
*3)Hash indices
*4)Bitmap














 196
196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









