







其实本来是闲逛逛的,然后就顺手整理了一下python的http以及urllib。
实现步骤:
今天突然想闲逛逛CSDN博客,看到有个排行榜,就点进去了。
其实早就知道有这个地,以前都不怎么来看。
然后,仔细一看,疑问和兴趣就都来了:
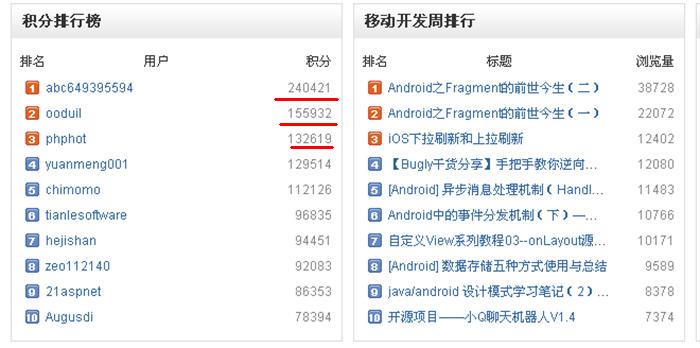
这积分太出人意料了,是吧。
它背后的原因是什么呢?
点进去:
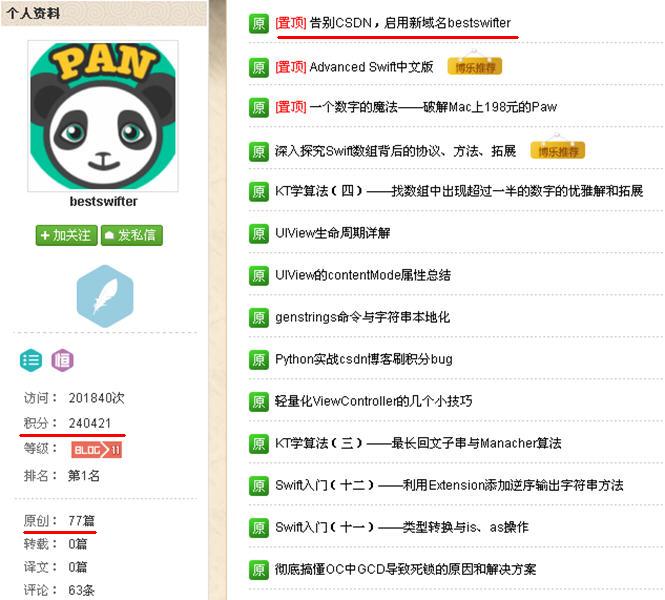
看左边的红线上,这就让人吃惊了,难道是CSDN的官方? 能自己随便给积分?
然后,看他置顶文章,标题太吸引人了,不得不看。

反正是人各有志吧,其实我觉得CSDN还是不错的,虽然现在竞争对手也多了,估计日子也不好过。
既然这人不是官方, 那他的积分哪来的,于是,很快找到了原因:
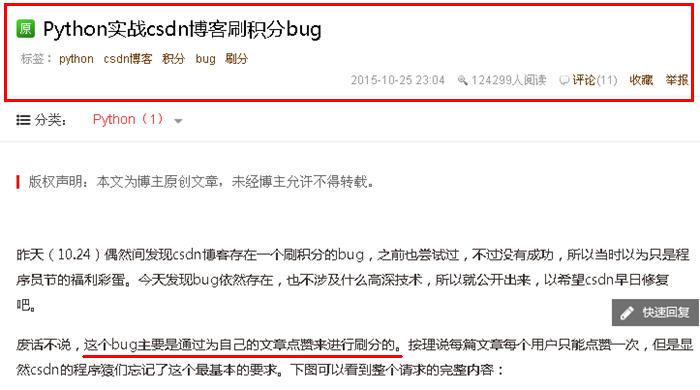
这人确实有才,于是好奇心越发大了。
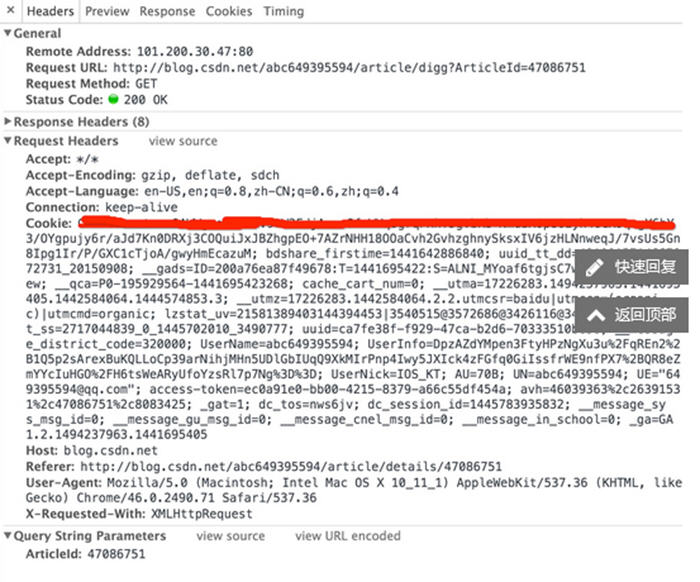
他怎么得的这段呢,这个工具是什么,我现在是不清楚的。
所以就整理了一下http模块。
不过,先看了一下cgi模块:
<span style="font-size:18px;">> cgi
BytesIO, FeedParser, FieldStorage, MiniFieldStorage, StringIO,
TextIOWrapper, closelog, dolog, escape, html,
initlog, locale, log, logfile, logfp,
maxlen, nolog, os, parse, parse_header,
parse_multipart, parse_qs, parse_qsl, print_arguments, print_directory,
print_environ, print_environ_usage, print_exception, print_form, sys,
tempfile, test, urllib, valid_boundary, warn,
import cgi;
def tmp():
print('写入开始 >>>');
array = ['cgi'];
fout = open('output.txt', 'w');
for i in range(len(array)):
s = array[i];
fout.write('> ' + s+'\n');
try:
a = dir(eval(s));
b = [];
for j in range(len(a)):
if (a[j][0] == '_'):
continue;
else:
b.append(a[j]);
for j in range(len(b)):
if (j == 0):
fout.write('\t');
fout.write(b[j]+', ');
if (j%5 == 4):
fout.write('\n\t');
fout.write('\r\n');
except:
pass;
fout.close();
print('写入完毕');</span>然后看看http模块:
<span style="font-size:18px;">> http.client
ACCEPTED, BAD_GATEWAY, BAD_REQUEST, BadStatusLine, CONFLICT,
CONTINUE, CREATED, CannotSendHeader, CannotSendRequest, EXPECTATION_FAILED,
FAILED_DEPENDENCY, FORBIDDEN, FOUND, GATEWAY_TIMEOUT, GONE,
HTTPConnection, HTTPException, HTTPMessage, HTTPResponse, HTTPSConnection,
HTTPS_PORT, HTTP_PORT, HTTP_VERSION_NOT_SUPPORTED, IM_USED, INSUFFICIENT_STORAGE,
INTERNAL_SERVER_ERROR, ImproperConnectionState, IncompleteRead, InvalidURL, LENGTH_REQUIRED,
LOCKED, LineTooLong, MAXAMOUNT, METHOD_NOT_ALLOWED, MOVED_PERMANENTLY,
MULTIPLE_CHOICES, MULTI_STATUS, NETWORK_AUTHENTICATION_REQUIRED, NON_AUTHORITATIVE_INFORMATION, NOT_ACCEPTABLE,
NOT_EXTENDED, NOT_FOUND, NOT_IMPLEMENTED, NOT_MODIFIED, NO_CONTENT,
NotConnected, OK, PARTIAL_CONTENT, PAYMENT_REQUIRED, PRECONDITION_FAILED,
PRECONDITION_REQUIRED, PROCESSING, PROXY_AUTHENTICATION_REQUIRED, REQUESTED_RANGE_NOT_SATISFIABLE, REQUEST_ENTITY_TOO_LARGE,
REQUEST_HEADER_FIELDS_TOO_LARGE, REQUEST_TIMEOUT, REQUEST_URI_TOO_LONG, RESET_CONTENT, ResponseNotReady,
SEE_OTHER, SERVICE_UNAVAILABLE, SWITCHING_PROTOCOLS, TEMPORARY_REDIRECT, TOO_MANY_REQUESTS,
UNAUTHORIZED, UNPROCESSABLE_ENTITY, UNSUPPORTED_MEDIA_TYPE, UPGRADE_REQUIRED, USE_PROXY,
UnimplementedFileMode, UnknownProtocol, UnknownTransferEncoding, collections, email,
error, io, os, parse_headers, responses,
socket, ssl, urlsplit, warnings,
> http.client.HTTPConnection
auto_open, close, connect, debuglevel, default_port,
endheaders, getresponse, putheader, putrequest, request,
response_class, send, set_debuglevel, set_tunnel,
> http.client.HTTPResponse
begin, close, closed, fileno, flush,
getcode, getheader, getheaders, geturl, info,
isatty, isclosed, read, readable, readall,
readinto, readline, readlines, seek, seekable,
tell, truncate, writable, writelines,
def tmp():
print('写入开始 >>>');
array = ['http.client', 'http.client.HTTPConnection',
'http.client.HTTPResponse'];
fout = open('output.txt', 'w');
for i in range(len(array)):
s = array[i];
fout.write('> ' + s+'\n');
try:
a = dir(eval(s));
b = [];
for j in range(len(a)):
if (a[j][0] == '_'):
continue;
else:
b.append(a[j]);
for j in range(len(b)):
if (j == 0):
fout.write('\t');
fout.write(b[j]+', ');
if (j%5 == 4):
fout.write('\n\t');
fout.write('\r\n');
except:
pass;
fout.close();
print('写入完毕');
</span>
抓http头的工具:
<span style="font-size:18px;">#使用http.client模块
def tmp2():
conn = [];
try:
conn = http.client.HTTPConnection('www.jianshu.com', 80)
conn.request('GET', '/users/3e55748920d2/latest_articles');
#response是HTTPResponse对象
response = conn.getresponse()
print(response.status);
print(response.reason);
print(response.read());
except:
traceback.print_exc();
finally:
if conn:
conn.close()
def tmp2():
conn = [];
try:
conn = http.client.HTTPConnection('www.jianshu.com', 80)
conn.request('GET', '/users/3e55748920d2/latest_articles');
'''
r.getheaders(); #获取所有的http头
#r.getheader("content-length"); #获取特定的头
print(r);
'''
#response是HTTPResponse对象
response = conn.getresponse()
print(response.status);
print(response.reason);
headers = response.getheaders();
for i in range(len(headers)):
print(headers[i]);
#print(response.getheaders());
print(response.getheader("content-length"));
except:
traceback.print_exc();
finally:
if conn:
conn.close()
</span>这是一些结果,这就是Http headers:
<span style="font-size:18px;">('status':200)
('reason':OK)
-- headers --
('Server', 'nginx')
('Date', 'Sun, 22 May 2016 02:29:11 GMT')
('Content-Type', 'text/html; charset=utf-8')
('Transfer-Encoding', 'chunked')
('Connection', 'keep-alive')
('Vary', 'Accept-Encoding')
('X-Frame-Options', 'DENY')
('X-XSS-Protection', '1; mode=block')
('X-Content-Type-Options', 'nosniff')
('ETag', 'W/"ec5f475caeb5522d7e5154fc53911171"')
('Cache-Control', 'max-age=0, private, must-revalidate')
('Set-Cookie', 'signin_redirect=http%3A%2F%2Fwww.jianshu.com%2Fusers%2F3e55748920d2%2Flatest_articles; path=/')
('Set-Cookie', 'read_mode=day; path=/')
('Set-Cookie', 'default_font=font2; path=/')
('Set-Cookie', '_session_id=SzlqMXpSak9RTnFCYldKVkp1ZXFZK1ZwSWRWeVZreFcwNGFZTTQxOHJZcVpGM3MyeHBuTFkxQ1FkNk5ld1ZwL0ZRU09lVmt4VUFaeXhacXNQbnd6bmZyM3pSUDJJR3FiL2NZUEZaT0xIcC9YVmlFMGdSQXlubE1ueEx1bGVFL1NLdFpOQStGdnVGbzJjRVU5QW4vbkxnWm1IS1M0ME1adWxVMFZzVm9JdGwxQnF1SDYvOVdLdzkyaXJNeTIyU2k0eTdEK3diek5FZ3BSMlp0TVcvTS9GU0FMV1hqazN4cG4wN1QxZHlwY0xqa29xc0FvRi9rUHE4Y0dqbFY2ZXc4UnNNMmNQcS9LY0d4Y0V5aWduK0hhM3FYMTExckE4UmhGL1JGYU4ycUhIdWlQa3UxUEM4Zk5XbmVtbFYxMFJKb3BSUjRrVjZod3dnR3pCYTZqdFl1ZFhuM0lXTnk1U3lZWmwrWkFBNlRLcmxpSWxUTGtzOWtTZTI1dWdmWXVnYUdzKzNxd09NeG5qdXlhZk85ZGxBY3dwQT09LS1IRVB1aU4yT20ybVNDN2xTVlRpWGJ3PT0%3D--0a4ff224eb686219e272dcc7fe1d5b7cda0229ca; path=/; HttpOnly')
('X-Request-Id', '5d63db3d-3797-418c-acd9-bbf3f47e096c')
('X-Runtime', '0.227105')
def tmp2():
conn = [];
try:
conn = http.client.HTTPConnection('blog.csdn.net', 80)
conn.request('GET', '/abc649395594/article/details/49408103');
#response是HTTPResponse对象
response = conn.getresponse()
print('(\'status\':'+str(response.status)+')');
print('(\'reason\':'+response.reason+')');
print('-- headers --');
headers = response.getheaders();
for i in range(len(headers)):
print(headers[i]);
except:
traceback.print_exc();
finally:
if conn:
conn.close()
('status':200)
('reason':OK)
-- headers --
('Server', 'openresty')
('Date', 'Sun, 22 May 2016 02:37:49 GMT')
('Content-Type', 'text/html; charset=utf-8')
('Content-Length', '47191')
('Connection', 'keep-alive')
('Keep-Alive', 'timeout=20')
('Vary', 'Accept-Encoding')
('Cache-Control', 'private, max-age=0, must-revalidate')
('ETag', '"eddd3c6a0ef1cc4937e7c3fac2afc037"')
('Set-Cookie', 'uuid=f0799af3-9c82-4e48-b6fc-f48080cd9134; expires=Mon, 23-May-2016 02:37:49 GMT; path=/')
('Set-Cookie', 'avh=49408103; expires=Sun, 22-May-2016 03:37:49 GMT; path=/')
('X-Powered-By', 'PHP 5.4.28')
</span>但我的这个cookie好像和他那个不一样,他怎么得到的呢?
于是我又整理了一下cookie,在python 3.*里,现在是在httlp下面的子文件了。
<span style="font-size:18px;">> http.cookies
BaseCookie, CookieError, Morsel, SimpleCookie, re,
string,
> http.server
BaseHTTPRequestHandler, CGIHTTPRequestHandler, DEFAULT_ERROR_CONTENT_TYPE, DEFAULT_ERROR_MESSAGE, HTTPServer,
SimpleHTTPRequestHandler, argparse, copy, email, executable,
html, http, io, mimetypes, nobody,
nobody_uid, os, posixpath, select, shutil,
socket, socketserver, sys, test, time,
urllib,
import http.client;
import http.cookiejar;
import http.cookies;
import http.server;
def tmp():
print('写入开始 >>>');
array = ['http.client', 'http.client.HTTPConnection',
'http.client.HTTPResponse', 'http.cookiejar',
'http.cookies', 'http.server'];
fout = open('output.txt', 'w');
for i in range(len(array)):
s = array[i];
fout.write('> ' + s+'\n');
try:
a = dir(eval(s));
b = [];
for j in range(len(a)):
if (a[j][0] == '_'):
continue;
else:
b.append(a[j]);
for j in range(len(b)):
if (j == 0):
fout.write('\t');
fout.write(b[j]+', ');
if (j%5 == 4):
fout.write('\n\t');
fout.write('\r\n');
except(Except, e):
print(e);
fout.close();
print('写入完毕');</span>整理这个的目的是想看一下上面那个http头里抓到的cookie是不是正解,
于是又用urllib库重新抓了一遍:
<span style="font-size:18px;"> #blog.csdn.net/abc649395594/article/details/49408103
> urllib
error, parse, request, response,
> urllib.request
AbstractBasicAuthHandler, AbstractDigestAuthHandler, AbstractHTTPHandler, BaseHandler, CacheFTPHandler,
ContentTooShortError, FTPHandler, FancyURLopener, FileHandler, HTTPBasicAuthHandler,
HTTPCookieProcessor, HTTPDefaultErrorHandler, HTTPDigestAuthHandler, HTTPError, HTTPErrorProcessor,
HTTPHandler, HTTPPasswordMgr, HTTPPasswordMgrWithDefaultRealm, HTTPRedirectHandler, HTTPSHandler,
MAXFTPCACHE, OpenerDirector, ProxyBasicAuthHandler, ProxyDigestAuthHandler, ProxyHandler,
Request, URLError, URLopener, UnknownHandler, addclosehook,
addinfourl, base64, bisect, build_opener, collections,
contextlib, email, ftpcache, ftperrors, ftpwrapper,
getproxies, getproxies_environment, getproxies_registry, hashlib, http,
install_opener, io, localhost, noheaders, os,
parse_http_list, parse_keqv_list, pathname2url, posixpath, proxy_bypass,
proxy_bypass_environment, proxy_bypass_registry, quote, re, request_host,
socket, splitattr, splithost, splitpasswd, splitport,
splitquery, splittag, splittype, splituser, splitvalue,
ssl, sys, tempfile, thishost, time,
to_bytes, unquote, unwrap, url2pathname, urlcleanup,
urljoin, urlopen, urlparse, urlretrieve, urlsplit,
urlunparse, warnings,
Name = BAIDUID
Value = E4C7B99EE958E09CD9787A3892D35B74:FG=1
Name = BIDUPSID
Value = E4C7B99EE958E09CD9787A3892D35B74
Name = H_PS_PSSID
Value = 1445_18195_19559_15013_11819
Name = PSTM
Value = 1463887503
Name = BDSVRTM
Value = 0
Name = BD_HOME
Value = 0
#这个抓取的键是一样的
>>>
('status':200)
('reason':OK)
-- headers --
('Date', 'Sun, 22 May 2016 03:26:04 GMT')
('Content-Type', 'text/html')
('Content-Length', '14613')
('Last-Modified', 'Wed, 03 Sep 2014 02:48:32 GMT')
('Connection', 'Keep-Alive')
('Vary', 'Accept-Encoding')
('Set-Cookie', 'BAIDUID=51E0E42E0EA11929F7AB640FD7302915:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com')
('Set-Cookie', 'BIDUPSID=51E0E42E0EA11929F7AB640FD7302915; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com')
('Set-Cookie', 'PSTM=1463887564; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com')
('P3P', 'CP=" OTI DSP COR IVA OUR IND COM "')
('Server', 'BWS/1.1')
('X-UA-Compatible', 'IE=Edge,chrome=1')
('Pragma', 'no-cache')
('Cache-control', 'no-cache')
('Accept-Ranges', 'bytes')
#每次都不一样的coockie值
>>>
('status':200)
('reason':OK)
-- headers --
('Date', 'Sun, 22 May 2016 03:27:34 GMT')
('Content-Type', 'text/html')
('Content-Length', '14613')
('Last-Modified', 'Wed, 03 Sep 2014 02:48:32 GMT')
('Connection', 'Keep-Alive')
('Vary', 'Accept-Encoding')
('Set-Cookie', 'BAIDUID=63CBD1549FD962A18D3B8A39E92B30DB:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com')
('Set-Cookie', 'BIDUPSID=63CBD1549FD962A18D3B8A39E92B30DB; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com')
('Set-Cookie', 'PSTM=1463887654; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com')
('P3P', 'CP=" OTI DSP COR IVA OUR IND COM "')
('Server', 'BWS/1.1')
('X-UA-Compatible', 'IE=Edge,chrome=1')
('Pragma', 'no-cache')
('Cache-control', 'no-cache')
('Accept-Ranges', 'bytes')
def tmp2():
conn = [];
try:
conn = http.client.HTTPConnection('www.baidu.com', 80)
conn.request('GET', '/');
#response是HTTPResponse对象
response = conn.getresponse()
print('(\'status\':'+str(response.status)+')');
print('(\'reason\':'+response.reason+')');
print('-- headers --');
headers = response.getheaders();
for i in range(len(headers)):
print(headers[i]);
except(Except, e):
print(e);
finally:
if conn:
conn.close()
def tmp3():
#声明一个CookieJar对象实例来保存cookie
cookie = http.cookiejar.CookieJar()
#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器
handler=urllib.request.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = urllib.request.build_opener(handler)
#此处的open方法同urllib2的urlopen方法,也可以传入request
response = opener.open('http://www.baidu.com')
for item in cookie:
print('Name = '+item.name)
print('Value = '+item.value)
</span>结果证明,这两种方式能取得的结果是一样的,那以后就只抓http头好了,信息还多些。
这人是这样刷分的,当然现在肯定是不行了,行也不要刷,这积分其实并没有什么利益在内
让它真实点更好。

这人太有才了,这个第一拿的大家心服口服,于是就又去他现在的博客逛了一圈,
看能不能扫到点什么好东西。
结果呢,是也有点,但不多。
比如一些计算机网络方面的东西:
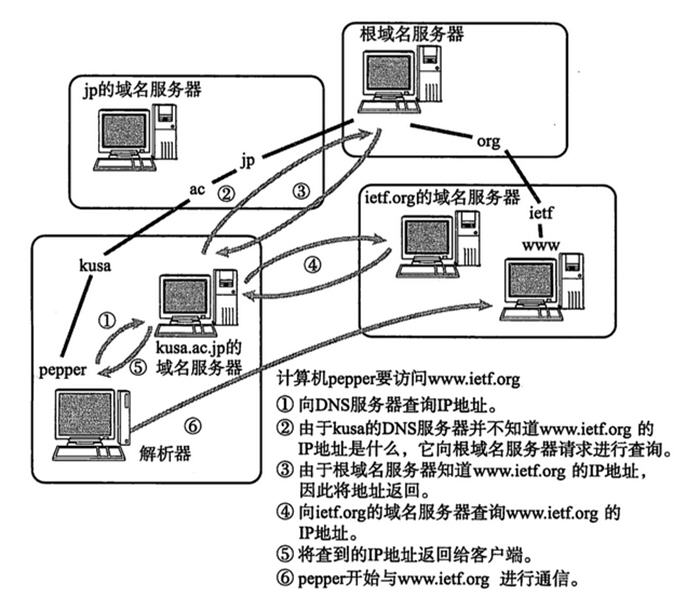
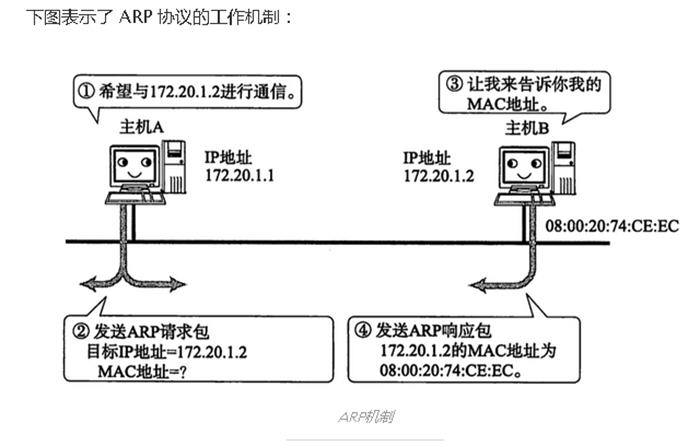
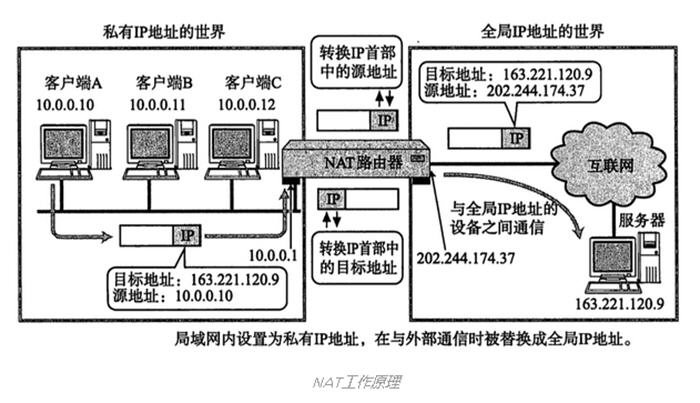

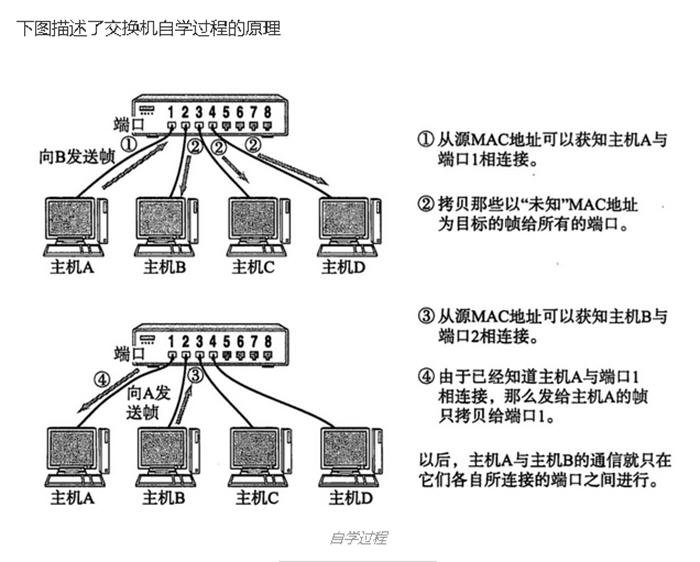
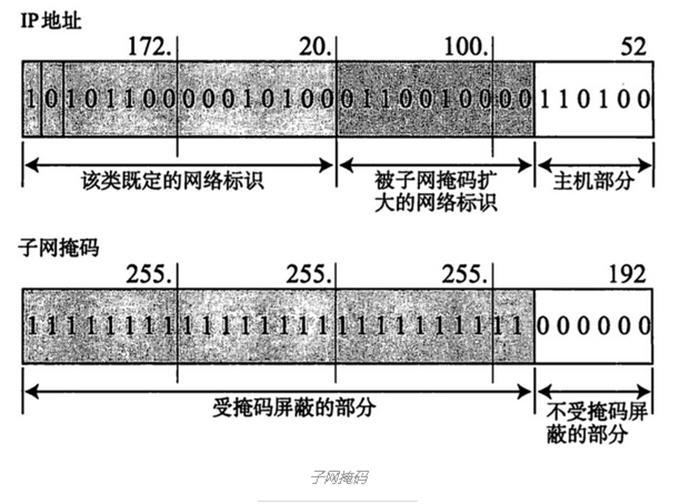
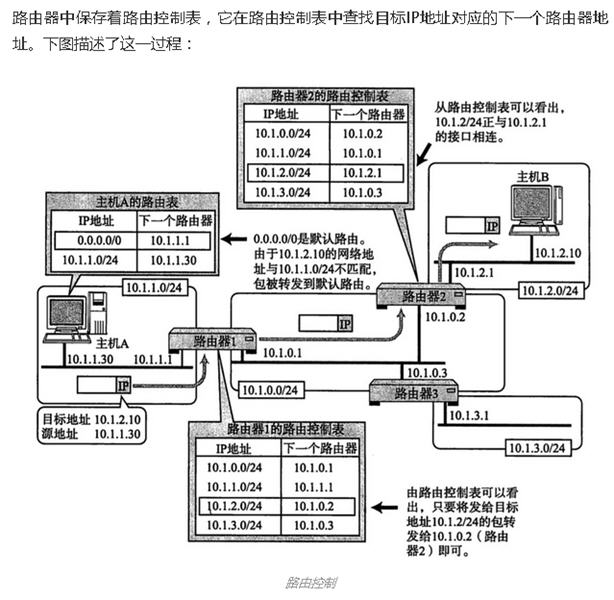
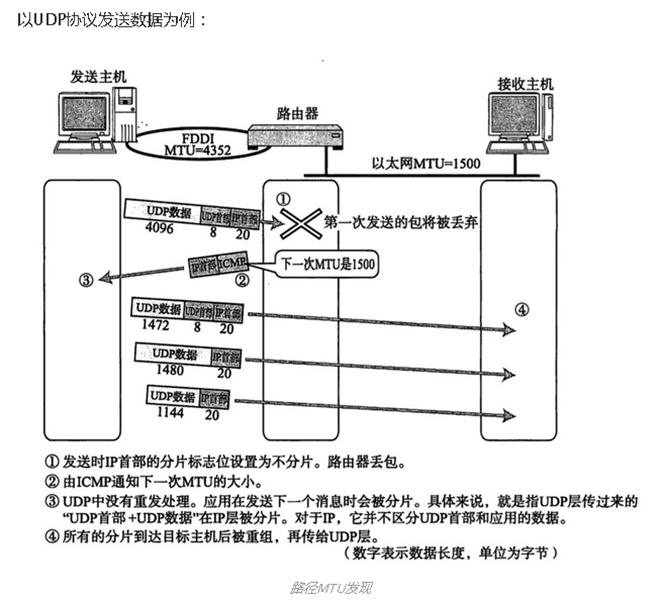
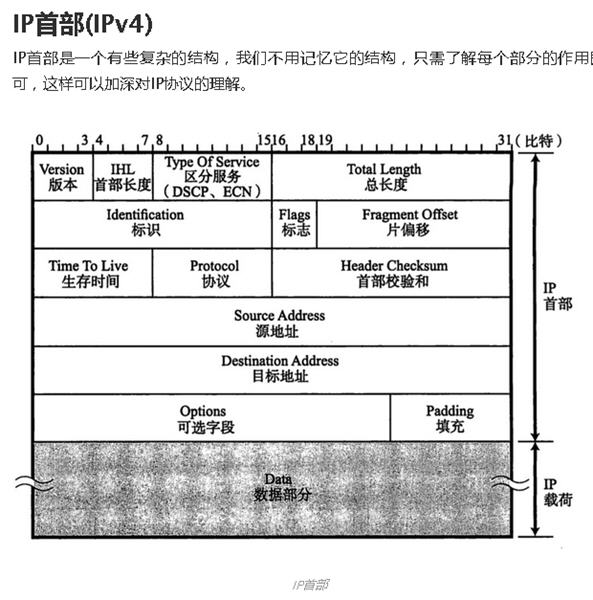
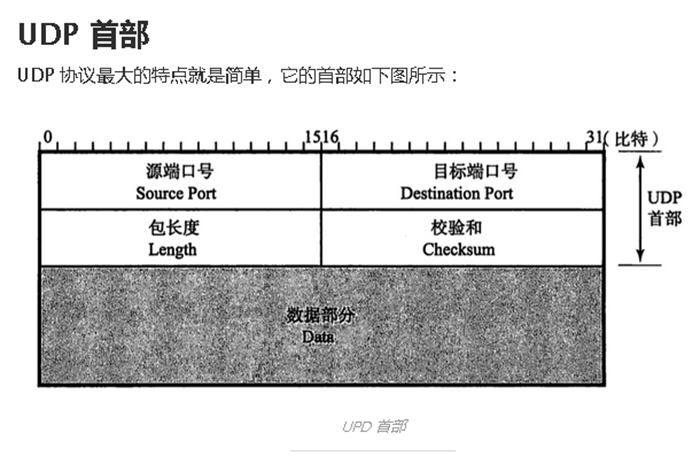
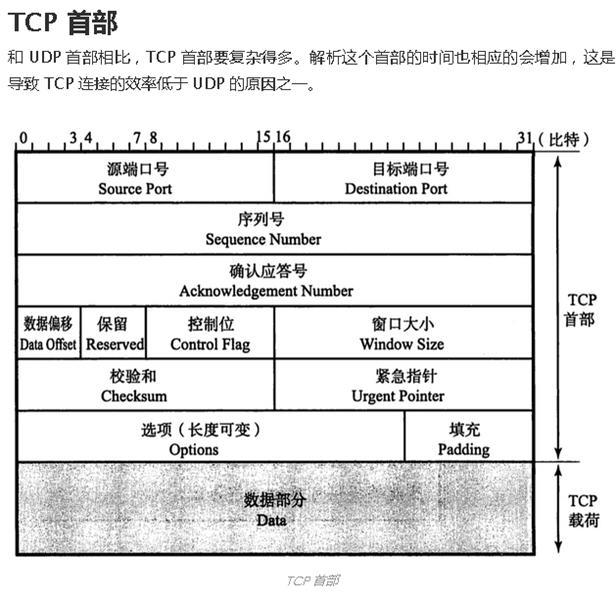

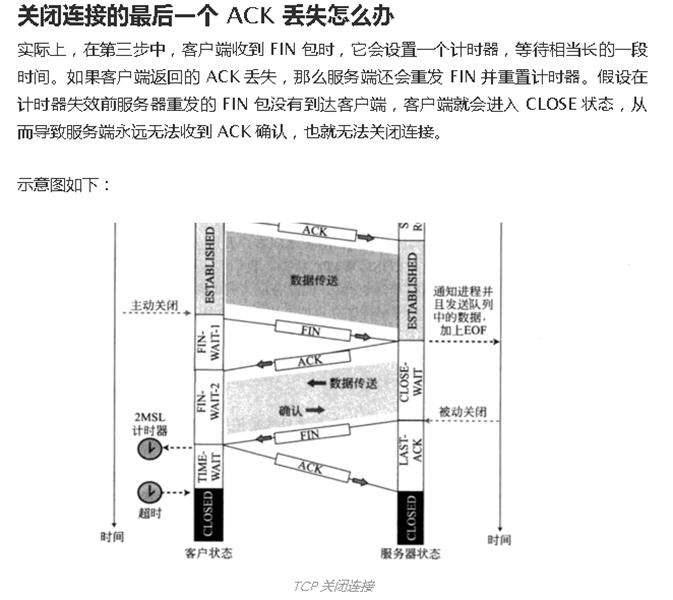
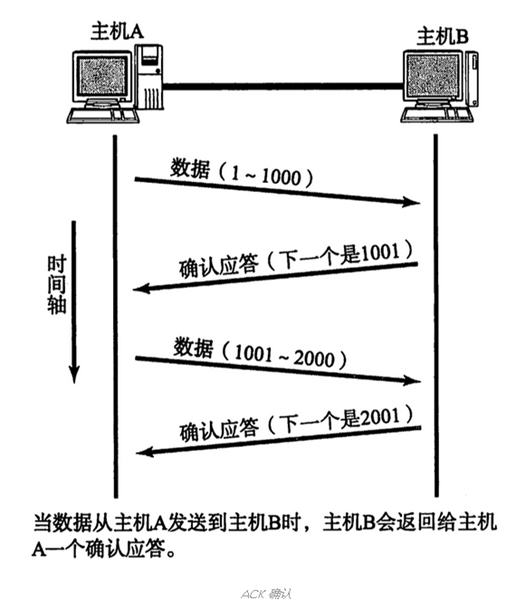
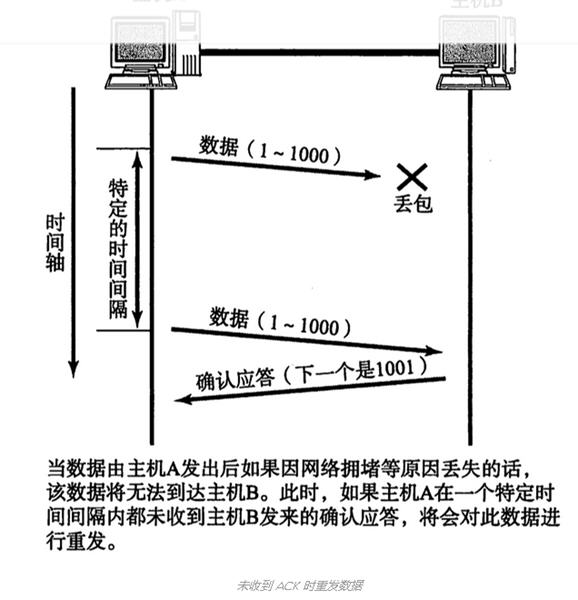

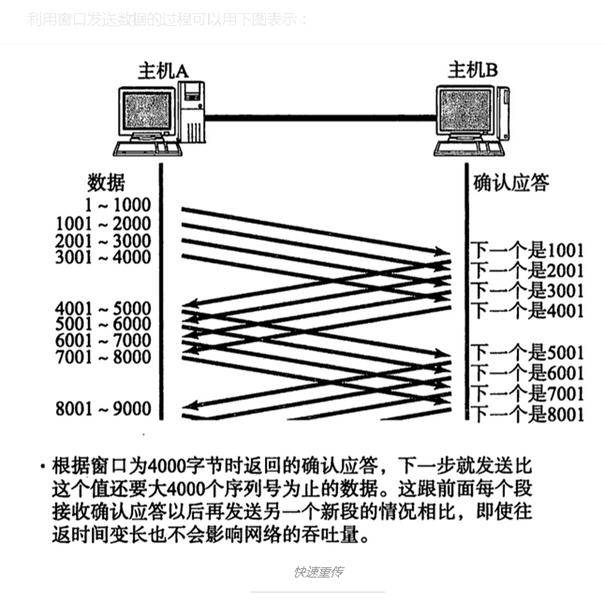
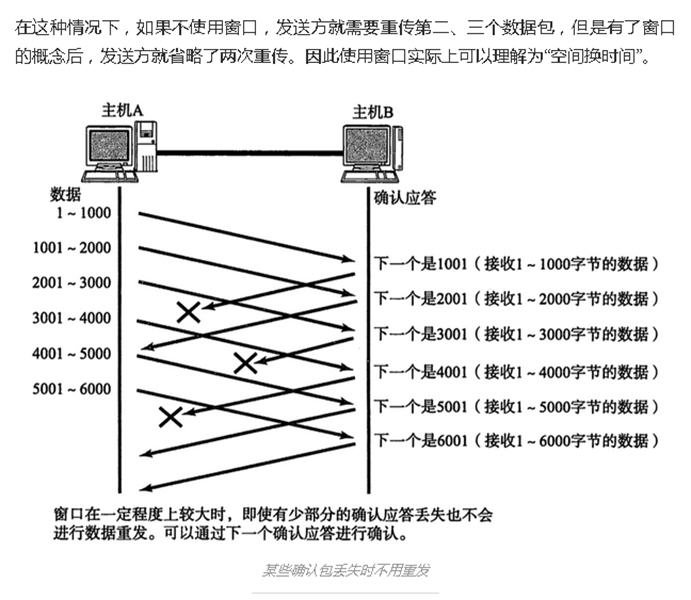
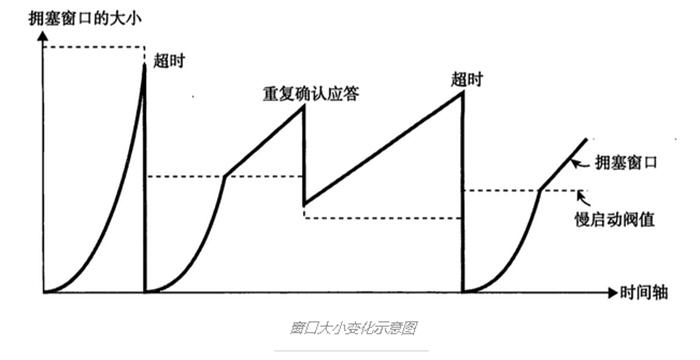

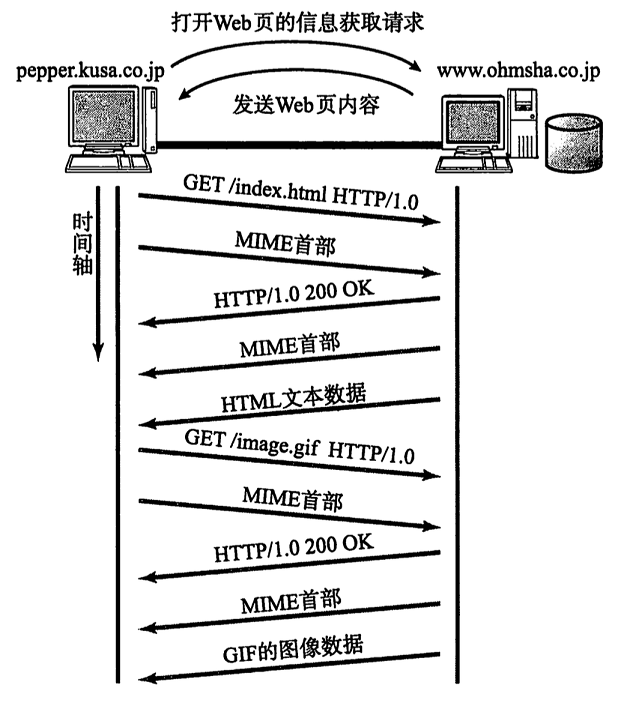
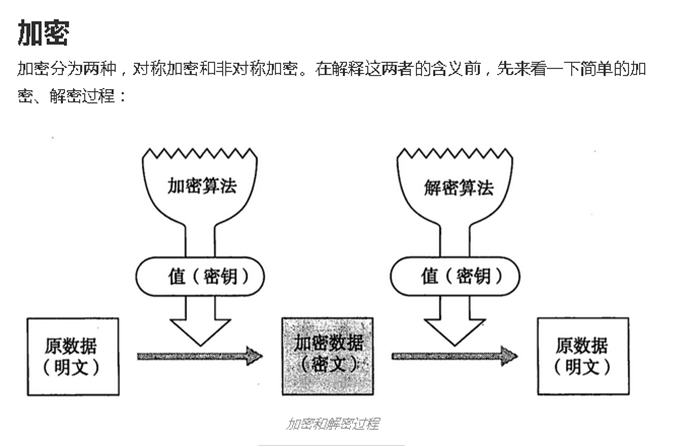
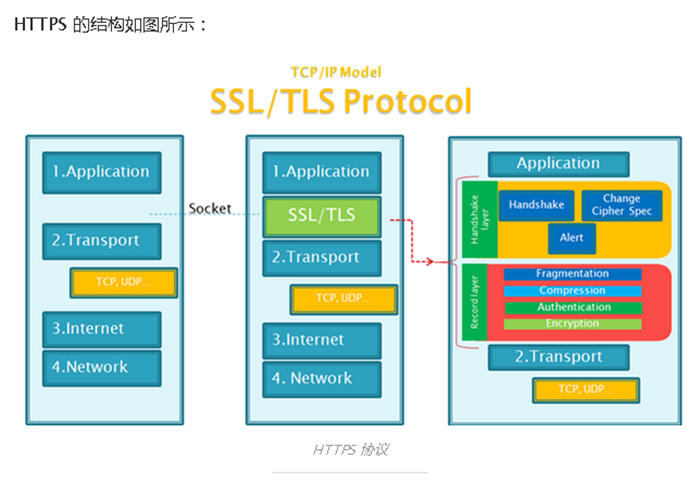
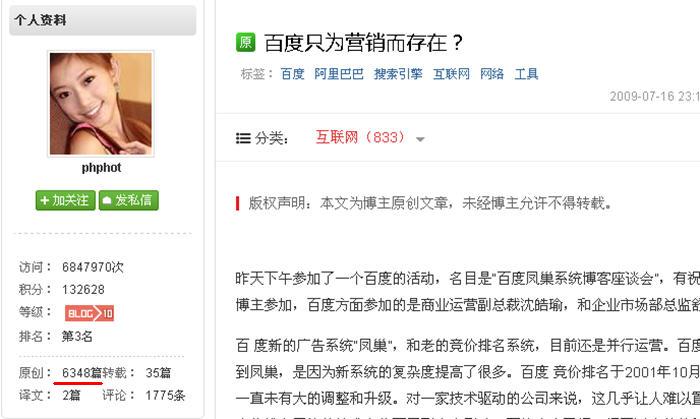
这位同学的东西搜刮了一遍后,我就又回到了这个排行榜第二名,
打开一看,这位比上一位就没法比了,这纯粹是一小号用了那个bug。
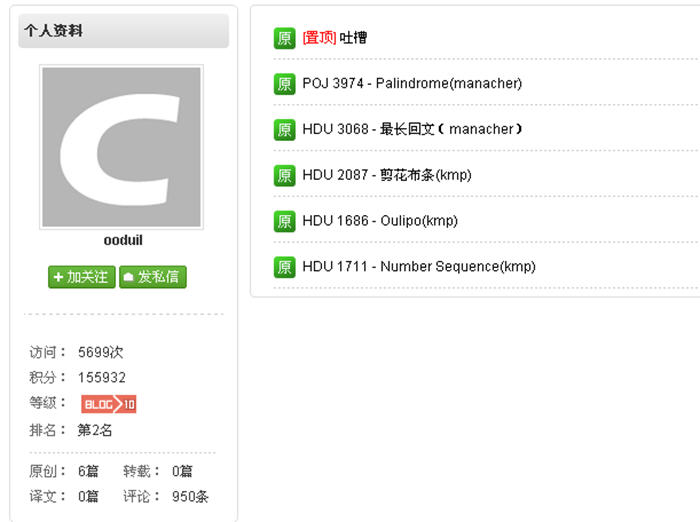
那就来看第三位吧:
看左边的红线,这要以怎样的速度写博客,才能有这样惊人的数字呢。
再仔细一看,这人也很有才,只不过不是代码,而是思维:

再仔细一看,这位的博文早就不更了,早已是人去楼空。

不得不说,CSDN光凭能让这前两位,一个有才的刷分者,一个纯粹的刷分者,
以及一个只说理论,不谈技术的业界理论大师牢牢坐稳这前三名的位置,
就这份气度和度量就让阿伟觉得,CSDN确实可靠,毕竟,这就是赤祼祼的打脸啊。
本节到此结束。














 3308
3308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









