






from: http://m.blog.csdn.net/article/details?id=51340277
tensorflow-0.8 的一大特性为可以部署在分布式的集群上,本文的内容由Tensorflow的分布式部署手册翻译而来,该手册链接为TensorFlow分布式部署手册
分布式TensorFlow
本文介绍了如何搭建一个TensorFlow服务器的集群,并将一个计算图部署在该分布式集群上。以下操作建立在你对 TensorFlow的基础操作已经熟练掌握的基础之上。
Hello world的分布式实例的编写
以下是一个简单的TensorFlow分布式程序的编写实例
tf.train.Server.create_local_server() 会在本地创建一个单进程集群,该集群中的服务默认为启动状态。
创建集群(cluster)
TensorFlow中的集群(cluster)指的是一系列能够对TensorFlow中的图(graph)进行分布式计算的任务(task)。每个任务是同服务(server)相关联的。TensorFlow中的服务会包含一个用于创建session的主节点和一个用于图运算的工作节点。另外, TensorFlow中的集群可以拆分成一个或多个作业(job), 每个作业可以包含一个或多个任务。下图为作者对集群内关系的理解。
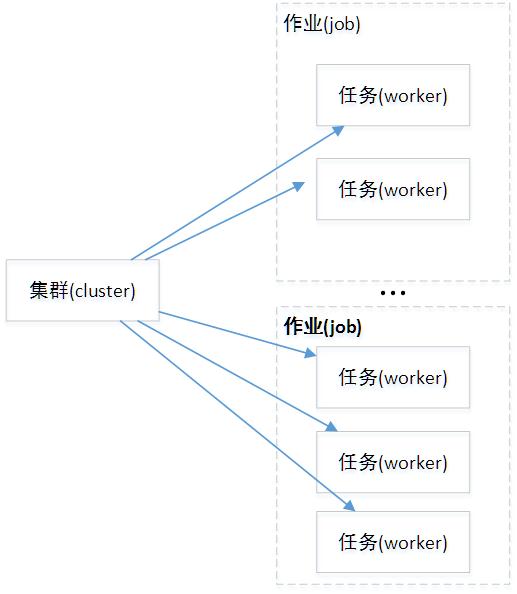
创建集群的必要条件是为每个任务启动一个服务。这些任务可以运行在不同的机器上,但你也可以在同一台机器上启动多个任务(比如说在本地多个不同的GPU上运行)。每个任务会做如下的两步工作:
- 创建一个
tf.train.ClusterSpec用于对集群中的所有任务进行描述,该描述内容对于所有任务应该是相同的。 - 创建一个
tf.train.Server并将tf.train.ClusterSpec中的参数传入构造函数,并将作业的名称和当前任务的编号写入本地任务中。
创建tf.train.ClusterSpec 的具体方法
tf.train.ClusterSpec 的传入参数是作业和任务之间的关系映射,该映射关系中的任务是通过ip地址和端口号表示的。具体映射关系如下表所示:
tf.train.ClusterSpec construction | Available tasks |
|---|---|
/job:local/task:0 local | |
/job:worker/task:0/job:worker/task:1/job:worker/task:2/job:ps/task:0/job:ps/task:1 |
为每一个任务创建tf.train.Server 的实例
每一个tf.train.Server 对象都包含一个本地设备的集合, 一个向其他任务的连接集合,以及一个可以利用以上资源进行分布式计算的“会话目标”(“session target“)。每一个服务程序都是一个指定作业的一员,其在作业中拥有自己独立的任务号。每一个服务程序都可以和集群中的其他任何服务程序进行通信。
以下两个代码片段讲述了如何在本地的2222和2223两个端口上配置不同的任务。
注 :当前手动配置任务节点还是一个比较初级的做法,尤其是在遇到较大的集群管理的情况下。tensorflow团队正在开发一个自动程序化配置任务的节点的工具。例如:集群管理工具Kubernetes。如果你希望tensorflow支持某个特定的管理工具,可以将该请求发到GitHub issue 里。
为模型指定分布式的设备
为了将某些操作运行在特定的进程上,可以使用tf.device() 函数来指定代码运行在CPU或GPU上。例如:
在上面的例子中,参数的声明是通过ps作业中的两个任务完成的,而模型计算相关的部分则是在work作业里进行的。TensorFlow将在内部实现作业间的数据传输。(ps到work间的向前传递;work到ps的计算梯度)
计算流程
在上面的这个称为“数据并行化”的公用训练配置项里,一般会包含多个用于对不同数据大小进行计算的任务(构成了work作业) 和 一个或多个分布在不同机器上用于不停更新共享参数的任务(构成了ps作业)。 所有的这些任务都可以运行在不同的机器上。实现这养的逻辑有很多的方法,目前TensorFlow团队采用的是构建链接库(lib)的方式来简化模型的工作,其实现了如下几种方法:
- 图内的拷贝(In-graph replication). 在这种方法下,客户端程序会建立一个独立的
tf.Graph,该图中的一系列节点 (tf.Variable)会通过ps作业(/job:ps)声明,而计算相关的多份拷贝会通过work作业(/job:worker)来进行。 - 图间的拷贝(Between-graph replication). 在这种方法下,每一个任务(
/job:worker) 都是通过独立客户端单独声明的。其相互之间结构类似,每一个客户端都会建立一个相似的图结构, 该结构中包含的参数均通过ps作业(/job:ps)进行声明并使用tf.train.replica_device_setter() 方法将参数映射到不同的任务中。模型中每一个独立的计算单元都会映射到/job:worker的本地的任务中。 - 异步训练(Asynchronous training). 在这种方法下,每一个图的备份都会使用独立的训练逻辑进行独立训练,该方法需要配合上面的两种方法一同使用。
- 同步训练(Synchronous training). 在这种方法下,所有的计算任务会读取当前参数中相同的值并用于并行化的计算梯度,然后将计算结果合并。这种方法需要和图内的拷贝(In-graph replication)方法(例如,在CIFAR-10 multi-GPU trainer 中我们使用该方法对梯度求平均值) 和图间的拷贝(Between-graph replication)(例如,
tf.train.SyncReplicasOptimizer)一同使用。
分布式训练程序的举例说明
接下来的代码是一个分布式训练程序的大致代码框架,其中实现了图间的拷贝和异步训练两种方法。该示例中包含了参数服务(parameter server)和工作任务(work task)的代码。
使用以下命令可以启动两个参数服务和两个工作任务。(假设上面的python脚本名字为 train.py)
名词解释
客户端(Client)
- 客户端是一个用于建立TensorFlow计算图并创立与集群进行交互的会话层
tensorflow::Session的程序。一般客户端是通过python或C++实现的。一个独立的客户端进程可以同时与多个TensorFlow的服务端相连 (上面的计算流程一节),同时一个独立的服务端也可以与多个客户端相连。
集群(Cluster)
- 一个TensorFlow的集群里包含了一个或多个作业(job), 每一个作业又可以拆分成一个或多个任务(task)。集群的概念主要用与一个特定的高层次对象中,比如说训练神经网络,并行化操作多台机器等等。集群对象可以通过tf.train.ClusterSpec 来定义。
作业(Job)
- 一个作业可以拆封成多个具有相同目的的任务(task),比如说,一个称之为ps(parameter server,参数服务器)的作业中的任务主要是保存和更新变量,而一个名为work(工作)的作业一般是管理无状态且主要从事计算的任务。一个作业中的任务可以运行于不同的机器上,作业的角色也是灵活可变的,比如说称之为”work”的作业可以保存一些状态。
主节点的服务逻辑(Master service)
- 一个RPC 服务程序可以用来远程连接一系列的分布式设备,并扮演一个会话终端的角色,主服务程序实现了一个tensorflow::Session 的借口并负责通过工作节点的服务进程(worker service)与工作的任务进行通信。所有的主服务程序都有了主节点的服务逻辑。
任务(Task)
- 任务相当于是一个特定的TesnsorFlow服务端,其相当于一个独立的进程,该进程属于特定的作业并在作业中拥有对应的序号。
TensorFlow服务端(TensorFlow server)
- 一个运行了tf.train.Server 实例的进程,其为集群中的一员,并有主节点和工作节点之分。
工作节点的服务逻辑(Worker service)
- 其为一个可以使用本地设备对部分图进行计算的RPC 逻辑,一个工作节点的服务逻辑实现了worker_service.proto 接口, 所有的TensorFlow服务端均包含工作节点的服务逻辑。














 5864
5864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









