







学习了python的requests爬虫库,首先安装pip包管理工具,下载get-pip.py. 我的机器上安装的既有python2也有python3。
安装pip到python2:
python get-pip.py安装到python3:
python3 get-pip.pypip安装完成以后,安装requests库开启python爬虫学习。
安装requests
pip3 install requests我使用的python3,python2可以直接用pip install requests.
入门例子
import requests
html=requests.get("http://gupowang.baijia.baidu.com/article/283878")
html.encoding='utf-8'
print(html.text)第一行引入requests库,第二行使用requests的get方法获取网页源代码,第三行设置编码格式,第四行文本输出。
把获取到的网页源代码保存到文本文件中:
import requests
import os
html=requests.get("http://gupowang.baijia.baidu.com/article/283878")
html_file=open("news.txt","w")
html.encoding='utf-8'
print(html.text,file=html_file)设置headers
把上面的链接换成CSDN的一篇博客,发现得到网页的源文件并没有内容,而是403 Forbidden。
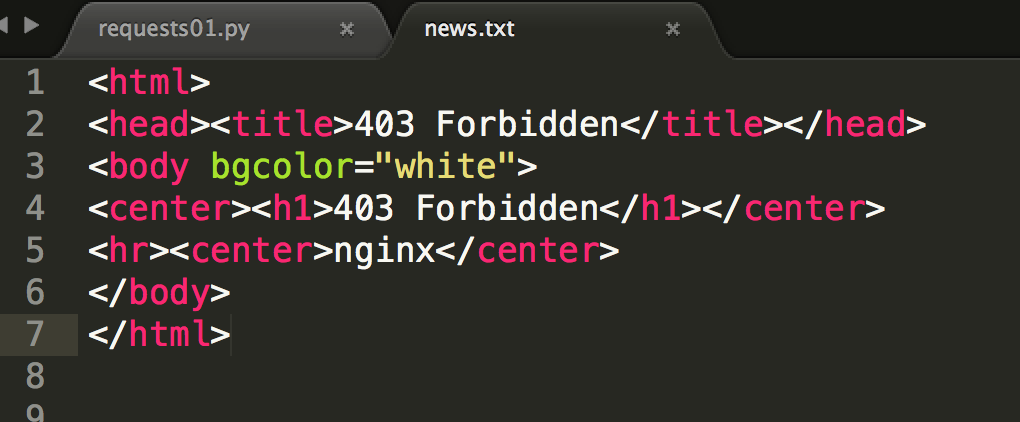
这是因为服务器设置导致拒绝访问,爬虫访问网页和浏览器访问网页有区别,区别就在于发生请求的时候还发送到有request header信息。随便打开一个网页,使用chrome开发者工具,点击network然后刷新一下重新访问。
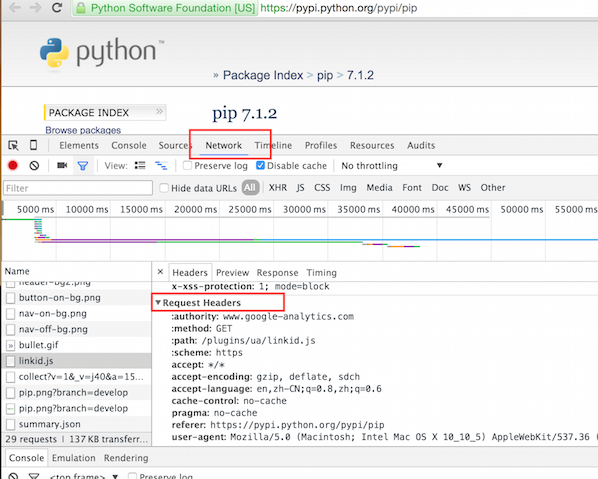
要想不被服务器禁止,就模拟浏览器加上headers
head={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/600.1.3 (KHTML, like Gecko) Version/8.0 Mobile/12A4345d Safari/600.1.4'}get方法加入一个参数,变成:
html=requests.get("http://blog.csdn.net/napoay/article/details/50442354",headers=head)再次运行就不会出现被服务器禁止的情况。
















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











