1. 聚类算法简介
聚类的目标是使同一类对象的相似度尽可能地大;不同类对象之间的相似度尽可能地小。目前聚类的方法很多,根据基本思想的不同,大致可以将聚类算法分为五大类:层次聚类算法、分割聚类算法、基于约束的聚类算法、机器学习中的聚类算法和用于高维度的聚类算法。
以下实现主要选取了基于划分的Kmeans算法和基于密度的DBSCAN算法来处理
1.1 基于划分的Kmeans算法
一种典型的划分聚类算法,它用一个聚类的中心来代表一个簇,即在迭代过程中选择的聚点不一定是聚类中的一个点。其目的是使各个簇(共k个)中的数据点与所在簇质心的误差平方和SSE(Sum of Squared Error)达到最小,这也是评价K-means算法最后聚类效果的评价标准。
算法的详细原理可自行Google或Wiki。
1.2 基于密度的DBSCAN算法
一种典型的基于密度的聚类算法,该算法采用空间索引技术来搜索对象的邻域,引入了“核心对象”和“密度可达”等概念,从核心对象出发,把所有密度可达的对象组成一个簇。简单的说就是根据一个根据对象的密度不断扩展的过程的算法。一个对象O的密度可以用靠近O的对象数来判断。
在DBSCAN算法中将数据点分为一下三类:
核心点:在半径Eps内含有超过MinPts数目的点
边界点:在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内
噪音点:既不是核心点也不是边界点的点
这里有两个量,一个是半径Eps,另一个是指定的数目MinPts。
2. 用户地理位置信息的的聚类实现
本实验用python实现,依赖numpy, pandas, sklearn, scipy等科学计算library。
数据来自收集得到的用户的地理位置信息,即经纬度数据的序列集。
xy = numpy.array([[116.455788, 39.920767], [116.456065, 39.920965], [116.452312, 39.92304], [116.421385, 39.989539],
[116.455685, 39.92069], [116.455876, 39.920845], [116.455973, 39.920902], [116.455645, 39.920657],
[116.456022, 39.920934], [116.455685, 39.920691], [116.456023, 39.920671], [116.45596, 39.920864],
[116.455522, 39.920856], [116.455276, 39.920407], [116.455799, 39.920867],
[116.455349, 39.920425], [116.45511, 39.920377], [116.455318, 39.920442], [116.455298, 39.920474],
[116.455839, 39.920636], [116.455979, 39.921168], [116.454281, 39.920006], [116.45598, 39.920612],
[116.45388, 39.919584], [116.455474, 39.920737], [116.456009, 39.920641], [116.455439, 39.920574],
[116.455759, 39.920841], [116.455838, 39.920644], [116.455983, 39.920847],
[116.459803, 39.922041], [116.456029, 39.92088], [116.455539, 39.920603], [116.455989, 39.920851],
[116.455719, 39.920789], [116.45601, 39.92082], [116.456229, 39.920564], [116.455906, 39.920771],
[116.456248, 39.920868], [116.455805, 39.920544], [116.455896, 39.920758], [116.43692, 39.926767],
[116.454672, 39.92024], [116.454813, 39.917848], [116.381415, 40.00875], [116.422925, 39.980757],
[116.422849, 39.9808], [116.38107, 40.009217], [116.456078, 39.920747], [116.455242, 39.919515],
[116.455615, 39.920533], [116.422092, 39.991104], [116.454847, 39.917724],
[116.456686, 39.924316], [116.45575, 39.920642], [116.456713, 39.924413], [116.455846, 39.920828],
[116.422108, 39.991098], [116.422075, 39.991139], [118.775572, 31.97337], [118.776968, 31.97392],
[118.778187, 31.973121], [118.775695, 31.973254], [118.775302, 31.973807],
[118.776303, 31.973692], [118.777541, 31.973439], [118.776196, 31.973489],
[116.448944, 39.926799], [116.45487, 39.917804], [116.455762, 39.920645], [116.456146, 39.920441],
[116.455857, 39.920043], [116.455458, 39.920826], [116.455533, 39.920791],
[116.455426, 39.920896], [116.45566, 39.920811], [116.455696, 39.920621], [116.453667, 39.9259],
[116.466606, 39.886322], [116.455917, 39.92062]])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
2.1 基于Kmeans的聚类实现
假设用户的地理位置信息通常是工作地点和家,因此选取k值为2,代码如下
res, idx = kmeans2(numpy.array(zip(xy[:, 0], xy[:, 1], z)), 2, iter=20, minit='points')
实现输出结果

但是实际上用户并未在河北出现过,用户经常出现的地方除了北京的工作地方和家,还曾经在南京出差一段时间。所以将K值设定为3,再次运行
res, idx = kmeans2(numpy.array(zip(xy[:, 0], xy[:, 1], z)), 3, iter=20, minit='points')
输出结果
这样就将南京的地理位置区分出来了。工作地方和出差地方已经非常贴合了,但是家的地方离实际距离还是差了不少距离。
其实已经可以看出来,由于用户的出现地点不可预知,因此很难确定K值。并且Kmeans聚合得到的结果取得是聚合簇的质心位置,并不是用户的实际地理位置,而且我选取的是相似度量是欧式距离,而不是经纬度计算的球面距离。因此得到的结果并不理想。
2.2 基于DBSCAN的聚类实现
DBSCAN算法的重点是选取的聚合半径参数和聚合所需指定的MinPts数目。
在此使用球面距离来衡量地理位置的距离,来作为聚合的半径参数。
如下实验,选取2公里作为密度聚合的半径参数,MinPts个数为5.
def haversine(lonlat1, lonlat2):
lat1, lon1 = lonlat1
lat2, lon2 = lonlat2
lon1, lat1, lon2, lat2 = map(radians, [lon1, lat1, lon2, lat2])
dlon = lon2 - lon1
dlat = lat2 - lat1
a = sin(dlat / 2) ** 2 + cos(lat1) * cos(lat2) * sin(dlon / 2) ** 2
c = 2 * asin(sqrt(a))
r = 6371
return c * r
def clustering_by_dbscan():
......
distance_matrix = squareform(pdist(X, (lambda u, v: haversine(u, v))))
db = DBSCAN(eps=2, min_samples=5, metric='precomputed')
y_db = db.fit_predict(distance_matrix)
X['cluster'] = y_db
......
plt.scatter(X['lat'], X['lng'], c=X['cluster'])
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
输出如下

结果显示该用户的地理位置信息聚合簇为4块,在结果中分别用0.0,1.0,2.0,-1.0来标记。可以看出DBSCAN算法可以根据用户的活动半径,也就是设定的最小半径参数2公里,将用户的活动地理位置数据集合分为了4簇,而且每一簇在空间上都是任意形状的,分类聚合的效果是不错的,但是得到的结果是一个个的簇,也就是一个个的地理点的集合,并不是一个“中心”。并且存在的噪声点无法区分。
3.基于DBSCAN和Kmeans的混合算法实现
从上面的实验结果,Kmeans算法的关键的是 K值的选取,而我无法确定用户地理信息聚类的簇的个数,如果实际上的地理位置的分布过于分散,按照固定K值聚合,得到的质心的位置可能和实际位置相差甚远。而DBSCAN的算法,聚类结果不错,因为是按照设定的人的活动半径的密度可达来聚合的,但其结果是将数据集合分类,并不求出中心点。
因此我设计了一种基于DBSCAN和Kmeans的混合算法:先利用DBSCAN算法的密度可达特性将用户的地理位置数据集按照活动半径聚合成若干个簇,并且将每一簇的数据集作为新的输入,再利用Kmeans算法的迭代聚合求出质心的位置,设定K值为1。
代码如下
def clustering_by_dbscan_and_kmeans2():
X = pd.DataFrame(
{"lat": [39.920767, 39.920965, 39.92304, 39.989539, 39.92069, 39.920845, 39.920902, 39.920657, 39.920934,
39.920691, 39.920671, 39.920864, 39.920856, 39.920407, 39.920867, 39.920425, 39.920377, 39.920442,
39.920474, 39.920636, 39.921168, 39.920006, 39.920612, 39.919584, 39.920737, 39.920641, 39.920574,
39.920841, 39.920644, 39.920847, 39.922041, 39.92088, 39.920603, 39.920851, 39.920789, 39.92082,
39.920564, 39.920771, 39.920868, 39.920544, 39.920758, 39.926767, 39.92024, 39.917848, 40.00875,
39.980757, 39.9808, 40.009217, 39.920747, 39.919515, 39.920533, 39.991104, 39.917724, 39.924316,
39.920642, 39.924413, 39.920828, 39.991098, 39.991139, 31.97337, 31.97392, 31.973121, 31.973254,
31.973807, 31.973692, 31.973439, 31.973489, 39.926799, 39.917804, 39.920645, 39.920441, 39.920043,
39.920826, 39.920791, 39.920896, 39.920811, 39.920621, 39.9259, 39.886322, 39.92062],
"lng": [116.455788, 116.456065, 116.452312, 116.421385, 116.455685, 116.455876, 116.455973, 116.455645,
116.456022, 116.455685, 116.456023, 116.45596, 116.455522, 116.455276, 116.455799, 116.455349,
116.45511, 116.455318, 116.455298, 116.455839, 116.455979, 116.454281, 116.45598, 116.45388,
116.455474, 116.456009, 116.455439, 116.455759, 116.455838, 116.455983, 116.459803, 116.456029,
116.455539, 116.455989, 116.455719, 116.45601, 116.456229, 116.455906, 116.456248, 116.455805,
116.455896, 116.43692, 116.454672, 116.454813, 116.381415, 116.422925, 116.422849, 116.38107,
116.456078, 116.455242, 116.455615, 116.422092, 116.454847, 116.456686, 116.45575, 116.456713,
116.455846, 116.422108, 116.422075, 118.775572, 118.776968, 118.778187, 118.775695, 118.775302,
118.776303, 118.777541, 118.776196, 116.448944, 116.45487, 116.455762, 116.456146, 116.455857,
116.455458, 116.455533, 116.455426, 116.45566, 116.455696, 116.453667, 116.466606, 116.455917]
})
distance_matrix = squareform(pdist(X, (lambda u, v: haversine(u, v))))
db = DBSCAN(eps=2, min_samples=5, metric='precomputed')
y_db = db.fit_predict(distance_matrix)
X['cluster'] = y_db
results = {}
for i in X.values:
if i[2] not in results.keys():
results[i[2]] = [[i[1], i[0]]]
else:
if results[i[2]]:
results[i[2]].append([i[1], i[0]])
else:
results[i[2]] = [[i[1], i[0]]]
print "DBSCAN output: ", len(results), results.keys()
print "KMeans calc center as below: "
for k in results.keys():
xy = numpy.array(results[k])
z = numpy.sin(xy[:, 1] - 0.2 * xy[:, 1])
z = whiten(z)
res, idx = kmeans2(numpy.array(zip(xy[:, 0], xy[:, 1], z)), 1, iter=20, minit='points')
address_text = my_get_address_text_by_location(res[0][1], res[0][0])
print res, address_text
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
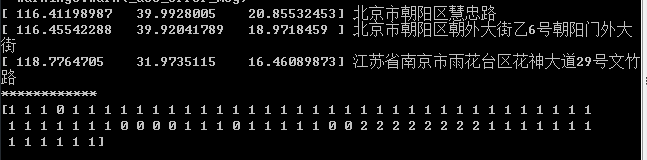
输出如下

其中”家“,”公司“,”出差“的位置信息已经非常贴合用户的实际信息了。
但是仍然存在的噪声点的信息。这个暂时还没找到解决方案,下一步的思路是带入用户地理位置信息收集时候得到的附属信息如时间来辅助分析,希望可以有更好的结果。





















 1110
1110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









