







训练样本大小选取的问题
模型学习的准确度与数据样本大小有关,那么如何展示更多的样本与更好的准确度之间的关系呢?
我们可以通过不断增加训练数据,直到模型准确度趋于稳定。这个过程能够很好让你了解,你的系统对样本大小及相应调整有多敏感。
所以,训练样本首先不能太少,太少的数据不能代表数据的整体分布情况,而且容易过拟合。数据当然也不是越多越好,数据多到一定程度效果就不明显了。不过,这里假设数据是均匀分布增加的。
然而这里有另一种声音:
算法使用的数据越多,它的精度会更加准确,所以如果可能要尽量避免抽样。机器学习理论在预测误差上有着非常直观的描述。简而言之,在机器学习模型和最优预测(在理论上达到最佳可能的误差)之间的预测误差的差距可以被分解为三个部分:
由于没有找到正确函数形式的模型的误差 由于没有找到最佳参数的模型的误差 由于没用使用足够数据的模型的误差如果训练集有限,它可能无法支撑解决这个问题所需的模型复杂性。统计学的基本规律告诉我们,如果我们可以的话,应该利用所有的数据而不是抽样。
其实当然数据越多越好,但是更多的数据意味着获取的难度以及处理的复杂度等。并且当数据多到一定程度后区别就不那么明显了。所以我们还是要根据自己情况科学地使用一定数量的数据。
参考资料:
机器学习项目中常见的误区
开发者成功使用机器学习的十大诀窍
选择什么模型算法?
很多像我一样的机器学习新手在遇到问题的时候,都会对用什么样的模型解决问题感到困惑。除了基本的有监督无监督,分类还是回归,二分类多分类等等基本的选择标准,貌似其他的都差不多,通常的做法就是每个模型都试一试,看看哪个效果好就用哪个。。显然这么做的不够的。
其实,选择什么算法最好,关键不在于算法,而在于具体要解决的问题,以及问题所具有的数据和特征。下面结合自己的经验和收集的资料,给出几点选择算法的tips。
1 特征角度
特征层次级别
就像古代把人分为三六九等,特征也有层次之分。我们暂且粗略地分为高级别特征和低级别特征,有的时候高级别的特征又叫组合特征。总体上,低级别特征比较有针对性,单个特征覆盖面小(含有这个特征的数据不多),特征数量(维度)很大。高级别特征比较泛化,单个特征覆盖面大(含有这个特征的数据很多),特征数量(维度)不大。下图展示了什么是高级低级特征:
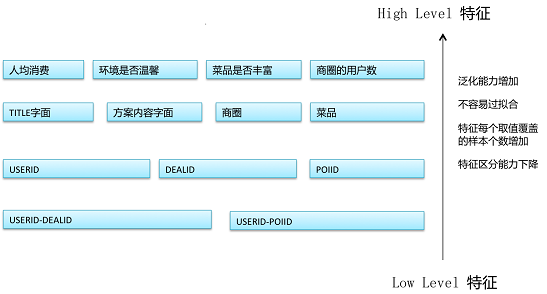
特征级别与线性模型和非线性模型
特征的低级和高级带来模型选择上的线性模型和非线性模型的考量:
非线性模型的特征
1)可以主要使用High Level特征,因为计算复杂度大,所以特征维度不宜太高;
2)通过High Level非线性映射可以比较好地拟合目标。线性模型的特征
1)特征体系要尽可能全面,High Level和Low Level都要有;
2)可以将High Level转换Low Level,以提升模型的拟合能力。
- 线性模型有:逻辑斯蒂回归,线性SVM等;
- 非线性模型有:决策树,随机森林,GBDT等。
例子: 逻辑斯蒂回归和决策树用哪个好?
只用高级或者低级特征
那平常我们所纠结的逻辑斯蒂回归和决策树用哪个好为例,决策树是一种非线性模型,因此如果是高级别特征的话我们就选择决策树;逻辑斯蒂回归是一种线性模型,因此如果是低级别特征的话我们就选择逻辑斯蒂回归。
然而,在我们是具体应用中,高级特征通常难以获得,或者获得的时间和成本很高,然而低级特征却很容易拿到。所以,在解决问题的初始阶段,我们最好先广泛收集可以用的低级别特征,来一个逻辑斯蒂回归,作为框架的基线系统。
线性模型对非线性关系缺乏准确刻画,高级特征刚好可以加入模型的非线性表达,增强模型的表达能力。另外,使用低级特征可以认为是对全局进行建模,而高级特征更加精细,是个性化建模,这就是为什么
- 决策树深入数据细部,但同时失去了对全局的把握,因为决策树一般使用高级特征;
- 逻辑回归始终着眼整个数据的拟合,所以对全局把握较好。但无法兼顾局部数据,或者说缺乏探查局部结构的内在机制,因为逻辑回归一般使用低级特征;
- 长尾样本的预测值主要受High Level特征影响,因为长尾样本是个性化样本;
- 高频样本的预测值主要受Low Level特征影响,因为高频样本是大众化的样本。
高级特征和低级特征都有
当我们有一些高级特征的时候,就把高级特征和低级特征共同加入到逻辑回归中进行训练,这样训练出来的模型兼顾了全局化与个性化,会使模型预测的准确率有所提高。具体到逻辑回归和决策树的使用上,我们可以充分利用两者之间的优缺点进行互补。主要思路是利用决策树对局部数据结构优越的把握能力增加逻辑回归的效力。在具体做法上有几种,一种是从决策树分析中找出数据局部结构,作为在逻辑回归中构建依变量(interaction)的依据。另一种是在需要对预测因子进行离散化处理时,利用决策树分析决定最佳切分点。还有一种是把决策树分类的最终结果作为预测变量,和其他协变量一起代入回归模型,又称为“嫁接式模型”。从理论上讲,嫁接模型综合了决策树和逻辑回归的优点。最终节点包含了数据中重要的局部结构,而协变量可以拾补被决策树遗漏的数据整体结构。
本部分参考文献:
在广告LR模型中,为什么要做特征组合?
逻辑回归与决策树在分类上的一些区别
2 要解决的问题本身
有时候我们要解决的问题可以用单个复杂的模型解决,也可以用多个简单的模型分别解决各个子问题,再基于各个单模型进行融合解决总问题。融合的方式可以是简单的线性融合,也可以是更加复杂的融合。
不同模型有不同 优缺点,具体如下:
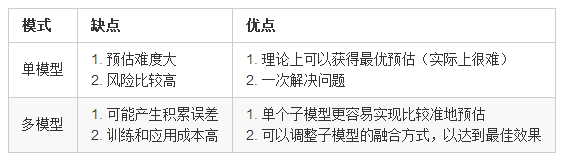
选择哪种模式?
1)问题可预估的难度,难度大,则考虑用多模型;
2)问题本身的重要性,问题很重要,则考虑用多模型;
3)多个模型的关系是否明确,关系明确,则可以用多模型。
这一部分主要抄袭美团技术报告:
实例详解机器学习如何解决问题
3 模型组合
最近模型组合的算法越来越流行,当单个分类器的性能不足以解决实际问题的时候,可以考虑使用模型组合的方法,也就是bagging和boosting的方法。
关于这部分,只知道GBDT在工业界很火,当有了一定了解和实战经验后,再来补充。














 690
690











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









