







概述:之前的博客中提到的一种负载均衡方式是lvs,lvs的配置简单,减少了认为出错的概率,而且软件处在tcp/ip协议栈的第四层,可以对各种web应用服务,但是因为本身不支持正则表达式处理,不能做动静分离。那么今天的haproxy的优势就体现出来了,能够支持虚拟机主机,并且实现了动静分离,url重定向等等大型网站需要的功能。
系统环境:Red Hat Enterprise Linux Server release 6.5 (Santiago)
内核版本:2.6.32-431.el6.x86_64
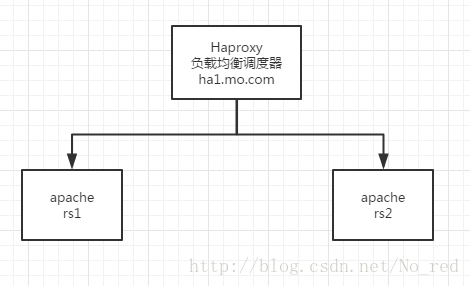
一.haproxy对http服务的负载均衡
拓扑图:
1 直接通过yum安装haproxy
[root@ha1 ~]# yum install haproxy -y
2 配置文件修改/etc/haproxy/haproxy.cfg
listen mo *:80 #定义haproxy的端口
balance roundrobin #调度算法
server static 172.25.3.102 check #定义real server1
server static 172.25.3.103 check #定义real server23 启动haproxy,和realserver的服务
[root@ha1 ~]# /etc/init.d/haproxy start
Starting haproxy: [ OK ]4 观察现象
为了使现象明显,最好将两个real server上/var/www/html下的index.html文件修改成不同的,这样才能看出在两台机器上调度。
[root@foundation3 ~]# curl 172.25.3.100
rserver1
[root@foundation3 ~]# curl 172.25.3.100
rserver2
[root@foundation3 ~]# curl 172.25.3.100
rserver1
[root@foundation3 ~]# curl 172.25.3.100
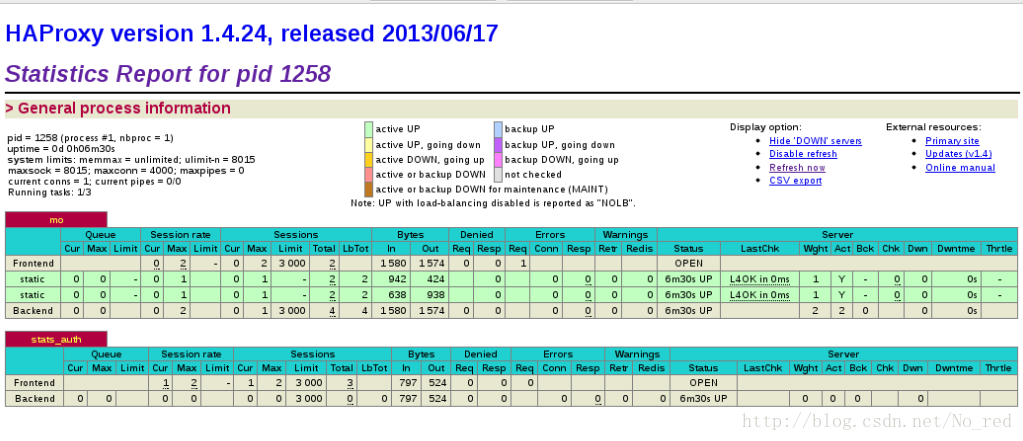
rserver2二 添加haproxy的监控界面
配置文件修改如下:
listen stats_auth *:8000
stats enable
stats uri /status
stats auth admin:momo #定义登陆的账号和密码
stats refresh 5s #定义监控数据每次刷新的时间效果:
三 定义haproxy日志
首先看一下刚才省略的全局配置:
global
log 127.0.0.1 local2 #日志发送的ip和日志的级别
chroot /var/lib/haproxy #haproxy运行时的根目录
pidfile /var/run/haproxy.pid
maxconn 4000 #最大连接数
user haproxy
group haproxy
daemon #后台运行
这里定义的日志local2
根据这一点我们去修改rsyslg服务的配置文件,将这个级别的日志定义到一个日志文件中。
/etc/rsyslog.conf添加如下一行
local2.* /var/log/haproxy.log由于日志发送使用的udp所以还要将下面两个选项打开
$ModLoad imudp
$UDPServerRun 514重启日志服务,然后重启haproxy,观察/var/log/haproxy是否有内容,如果有内容就代表日志定向成功了。
[root@ha1 ~]# cat /var/log/haproxy.log
Mar 18 22:08:15 localhost haproxy[1394]: Proxy mo started.
Mar 18 22:08:15 localhost haproxy[1394]: Proxy stats_auth started.四 访问限制
访问限制就是对某一个ip的访问定向到一个错误界面,让该ip不能访问正常服务。
frontend mo *:80
acl invalid_src src 172.25.3.250/24
block if invalid_src
default_backend app
backend app
balance roundrobin
server static 172.25.3.102:80 check
#listen mo *:80
# balance roundrobin
# server static 172.25.3.102 check
# server static 172.25.3.103 check以上配置最重要的就是acl,通过acl我们定义了一个非法的源ip,这个源可以是一个主机地址,也可是网络地址,当这个ip访问的时候我们就block。
我们日常情况下当拒绝客户访问时候肯定会给一个别的界面好看一点的界面,这一点就是通过错误重定向功能做到的,增加如下配置
errorloc 403 http://172.25.3.100:8000/error/reject.html五.根据资源不同将请求分配到不同服务器
我们现在有两台http服务器,准备一台用来静态页面,另一台放置图片,改如何呢?
我们知道图片数据,和静态页面是两种资源,所以请求他们的url也不相同,根据这一特点我们进行请求的分离。
配置文件如下:
frontend mo *:80
acl url_image path_beg -i /images
acl url_image path_end -i .jpg .png .css
acl invalid_src src 172.25.3.250
block if invalid_src
default_backend static
use_backend image if url_image
backend static
balance roundrobin
server static 172.25.3.103:80 check
backend image
balance roundrobin
server static 172.25.3.102:80 check172.25.3.102 上的资源目录
[root@localhost html]# tree /var/www/html/
/var/www/html/
├── image
│ └── timg.jpg
└── index.html
1 directory, 2 files172.25.3.103上的资源目录
[root@localhost html]# tree /var/www/html/
/var/www/html/
└── index.html
测试:
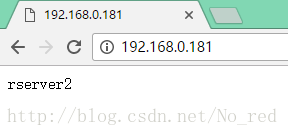
(192.168.0.181真机的一块网卡,我将目的地址为192.168.0.181的包全改成了给172.25.3.100,所以不用在意这个地址)
发现静态界面到了reserver2,也就是172.25.3.103

由于3上根本没有图片文件,所以这次定位到了172.25.3.102上。
六.根据状态码定向页面
五.pacemaker+haproxy
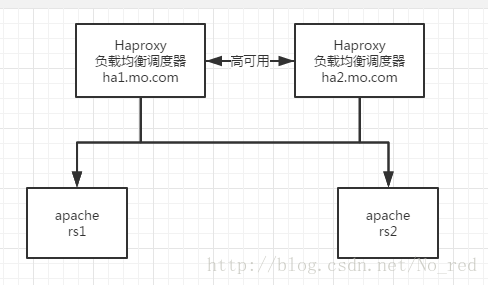
1 配置集群服务我们首先要停掉haproxy,而且一定要停干净。
2.安装pacemaker集群需要的配件运维笔记31 (pacemaker高可用集群搭建的总结)这里有pacemaker的详细配置。
3.测试
[root@ha1 ~]# yum install pacemaker corosync -y安装corosycn心跳组件,pacemaker集群资源管理器
```
[root@ha1 ~]# rpm -ivh crmsh-1.2.6-0.rc2.2.1.x86_64.rpm pssh-2.3.1-2.1.x86_64.rpm 安装crm shell管理,可以方便我们对集群的配置和配置的分发。
bindnetaddr: 172.25.3.0 #第10行
service { #第34行
name:pacemaker
ver:0
}corosync的配置文件有一个example,我们将example去掉后重命名,只要修改如上三个部分即可。
[root@ha1 ~]# scp /etc/corosync/corosync.conf ha2.mo.com:/etc/corosync/
[root@ha1 ~]# /etc/init.d/corosync start
Starting Corosync Cluster Engine (corosync): [ OK ] #ha2也要打开
[root@ha1 ~]# crm
crm(live)# 将该文件拷贝给另一个节点。开启corsync服务。
进入crm配置集群。
crm(live)configure# show
node ha1.mo.com
node ha2.mo.com
node localhost.localdomain
property $id="cib-bootstrap-options" \
dc-version="1.1.10-14.el6-368c726" \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes="2" \
stonith-enabled="false"集群的配置初始情况如上。
crm(live)resource# primitive vip ocf:heartbeat:IPaddr2 params ip=172.25.3.200 cidr_netmask=24 op monitor interval=30s
crm(live)resource# primitive proxy lsb:haproxy op monitor interval=30s
crm(live)configure# group LB vip proxy 首先添加vip资源,之后是proxy资源,最后是将两个资源合成一个组,开启服务组,观察服务状态。
Online: [ ha1.mo.com ha2.mo.com ]
OFFLINE: [ localhost.localdomain ]
Resource Group: LB
vip (ocf::heartbeat:IPaddr2): Started ha1.mo.com
proxy (lsb:haproxy): Started ha1.mo.com服务正常。
六 keepalived+haproxy
现在停掉corosync,并将与其相关的进程都杀干净。使用keepalived为haproxy做高可用集群。由于keepalived不像heartbeat,corosync具有丰富的服务脚本,所以先要考虑keepalived如何将服务启动,关闭。keepalived是一个类似于layer3, 4 & 5交换机制的软件,也就是我们平时说的第3层、第4层和第5层交换。Keepalived的作用是检测web服务器的状态,如果有一台web服务器死机,或工作出现故障,Keepalived将检测到,并将有故障的web服务器从系统中剔除,当web服务器工作正常后Keepalived自动将web服务器加入到服务器群中,这些工作全部自动完成,不需要人工干涉,需要人工做的只是修复故障的web服务器。
综上我们需要解决的就是弄一个可以检测健康并且关闭服务的脚本。
脚本如下:
#!/bin/bash
/etc/init.d/haproxy status &> /dev/null || /etc/init.d/haproxy restart &> /dev/null
if [ $? -ne 0 ];then
/etc/init.d/keepalived stop &> /dev/null
fi













 600
600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









