







选自The M tank
机器之心编译
参与:蒋思源、刘晓坤
The M Tank 编辑了一份报告《A Year in Computer Vision》,记录了 2016 至 2017 年计算机视觉领域的研究成果,对开发者和研究人员来说是不可多得的一份详细材料。该材料共包括四大部分,在本文中机器之心对第一部分做了编译介绍,后续会放出其他部分内容。
内容目录
简介
第一部分
分类/定位
目标检测
目标追踪
第二部分
分割
超分辨率、风格迁移、着色
动作识别
第三部分
3D 目标
人体姿势估计
3D 重建
其他未分类 3D
总结
第四部分
卷积架构
数据集
不可分类的其他材料与有趣趋势
结论
完整 PDF 地址:http://www.themtank.org/pdfs/AYearofComputerVisionPDF.pdf
简介
计算机视觉是关于研究机器视觉能力的学科,或者说是使机器能对环境和其中的刺激进行可视化分析的学科。机器视觉通常涉及对图像或视频的评估,英国机器视觉协会(BMVA)将机器视觉定义为「对单张图像或一系列图像的有用信息进行自动提取、分析和理解」。
对我们环境的真正理解不是仅通过视觉表征就可以达成的。更准确地说,是视觉线索通过视觉神经传输到主视觉皮层,然后由大脑以高度特征化的形式进行分析的过程。从这种感觉信息中提取解释几乎包含了我们所有的自然演化和主体经验,即进化如何令我们生存下来,以及我们如何在一生中对世界进行学习和理解。
从这方面来说,视觉过程仅仅是传输图像并进行解释的过程,然而从计算的角度看,图像其实更接近思想或认知,涉及大脑的大量功能。因此,由于跨领域特性很显著,很多人认为计算机视觉是对视觉环境和其中语境的真实理解,并将引领我们实现强人工智能。
不过,我们目前仍然处于这个领域发展的胚胎期。这篇文章的目的在于阐明 2016 至 2017 年计算机视觉最主要的进步,以及这些进步对实际应用的促进。
为简单起见,这篇文章将仅限于基本的定义,并会省略很多内容,特别是关于各种卷积神经网络的设计架构等方面。
这里推荐一些学习资料,其中前两个适用与初学者快速打好基础,后两个可以作为进阶学习:
Andrej Karpathy:「What a Deep Neural Network thinks about your #selfie」,这是理解 CNN 的应用和设计功能的最好文章 [4]。
Quora:「what is a convolutional neural network?」,解释清晰明了,尤其适合初学者 [5]。
CS231n: Convolutional Neural Networks for Visual Recognition,斯坦福大学课程,是进阶学习的绝佳资源 [6]。
Deep Learning(Goodfellow,Bengio&Courville,2016),这本书在第 9 章提供了对 CNN 的特征和架构设计等详尽解释,网上有免费资源 [7]。
对于还想进一步了解神经网络和深度学习的,我们推荐:
Neural Networks and Deep Learning(Nielsen,2017),这是一本免费在线书籍,可为读者提供对神经网络和深度学习的复杂性的直观理解。即使只阅读了第 1 章也可以帮助初学者透彻地理解这篇文章。
下面我们先简介本文的第一部分,这一部分主要叙述了目标分类与定位、目标检测与目标追踪等十分基础与流行的计算机视觉任务。而后机器之心将陆续分享 Benjamin F. Duffy 和 Daniel R. Flynn 后面 3 部分对计算机视觉论述,包括第二部分的语义分割、超分辨率、风格迁移和动作识别,第三部分三维目标识别与重建、和第四部分卷积网络的架构与数据集等内容。
基础的计算机视觉任务
分类/定位
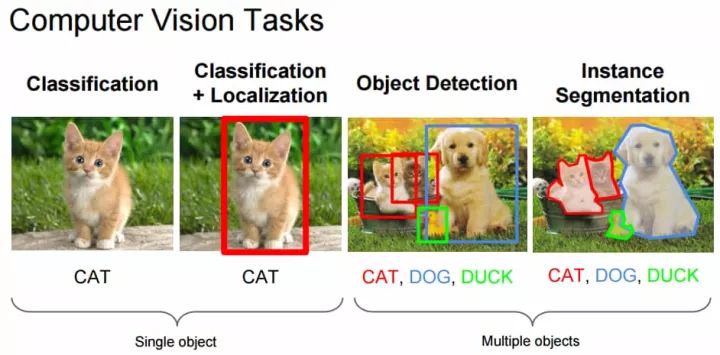
图像分类任务通常是指为整张图像分配特定的标签,如下左图整张图像的标签为 CAT。而定位是指找到识别目标在图像中出现的位置,通常这种位置信息将由对象周围的一些边界框表示出来。目前 ImageNet [9] 上的分类/定位的准确度已经超过了一组训练有素的人类 [10]。因此相对于前一部分的基础,我们会着重介绍后面如语义分割、3D 重建等内容。
图 1:计算机视觉任务,来源 cs231n 课程资料。
然而随着目标类别 [11] 的增加,引入大型数据集将为近期的研究进展提供新的度量标准。在这一方面,Keras [12] 创始人 Francois Chollet 将包括 Xception 等架构和新技术应用到谷歌内部的大型数据集中,该数据集包含 1.7 万个目标类别,共计 350M(Million)的多类别图像。
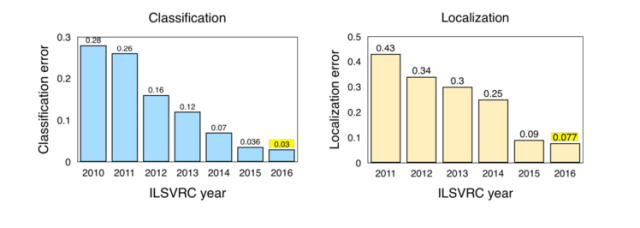
图 2:ILSVRC 竞赛中,分类/定位的逐年错误率,来源 Jia Deng (2016),ILSVRC2016。
ImageNet LSVRC(2016)亮点:
场景分类是指用「温室」、「体育场」和「大教堂」等特定场景对图像进行分类。ImageNet 去年举办了基于 Places2[15] 子数据的场景分类挑战赛,该数据集有 365 个场景共计 8 百万 训练图像。海康威视 [16] 选择了深度类 Inception 的网络和并不太深的 ResNet,并利用它们的集成实现 9% 的 Top-5 误差率以赢得竞赛。
Trimps-Soushen 以 2.99% 的 Top-5 分类误差率和 7.71% 的定位误差率赢得了 ImageNet 分类任务的胜利。该团队使用了分类模型的集成(即 Inception、Inception-ResNet、ResNet 和宽度残差网络模块 [17] 的平均结果)和基于标注的定位模型 Faster R-CNN [18] 来完成任务。训练数据集有 1000 个类别共计 120 万的图像数据,分割的测试集还包括训练未见过的 10 万张测试图像。
Facebook 的 ResNeXt 通过使用从原始 ResNet [19] 扩展出来的新架构而实现了 3.03% 的 Top-5 分类误差率。
目标检测
目标检测(Object Detection)即如字面所说的检测图像中包含的物体或目标。ILSVRC 2016 [20] 对目标检测的定义为输出单个物体或对象的边界框与标签。这与分类/定位任务不同,目标检测将分类和定位技术应用到一张图像的多个目标而不是一个主要的目标。
图 3:仅有人脸一个类别的目标检测。图为人脸检测的一个示例,作者表示目标识别的一个问题是小物体检测,检测图中较小的人脸有助于挖掘模型的尺度不变性、图像分辨率和情景推理的能力,来源 Hu and Ramanan (2016, p. 1)[21]。
目标识别领域在 2016 年主要的趋势之一是转向更快、更高效的检测系统。这一特性在 YOLO、SSD 和 R-FCN 方法上非常显著,它们都倾向于在整张图像上共享计算。因此可以将它们与 Fast/Faster R-CNN 等成本较高的子网络技术区分开开来,这些更快和高效的检测系统通常可以指代「端到端的训练或学习」。
这种共享计算的基本原理通常是避免将独立的算法聚焦在各自的子问题上,因为这样可以避免训练时长的增加和网络准确度的降低。也就是说这种端到端的适应性网络通常发生在子网络解决方案的初始之后,因此是一种可回溯的优化(retrospective optimisation)。然而,Fast/Faster R-CNN 技术仍然非常有效,仍然广泛用于目标检测任务。
SSD:Single Shot MultiBox Detector[22] 利用封装了所有必要计算并消除了高成本通信的单一神经网络,以实现了 75.1% mAP 和超过 Faster R-CNN 模型的性能(Liu et al. 2016)。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









