






此篇文章只是一份普通的实验报告,同时会对Jcseg中文分词使用进行分享。
实现目的
学习编写Spark程序,对中文文档分词词频的统计分析。
实现原理
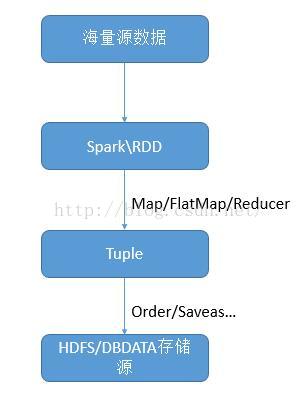
实现步骤
(1)Jcseg分词
官方首页:https://code.google.com/p/jcseg/
下载地址:https://code.google.com/p/jcseg/downloads/list
github开源社区:http://git.oschina.net/lionsoul/jcseg
Jcseg是基于mmseg算法的一个轻量级开源中文分词器,同时集成了关键字提取,关键短语提取,关键句子提取和文章自动摘要等功能,并且提供了最新版本的lucene, solr, elasticsearch的分词接口。
随着时代的发展,新词汇的脱颖而出,特别是网络词汇的出现。有些时候就需要更新扩展。但是字典基本词汇都已经有了。当然我们可以自己扩展自己的词汇,只需要仿照下面的文件以lex-*.lex的文件命名就可以,数据格式按照里面的内容。
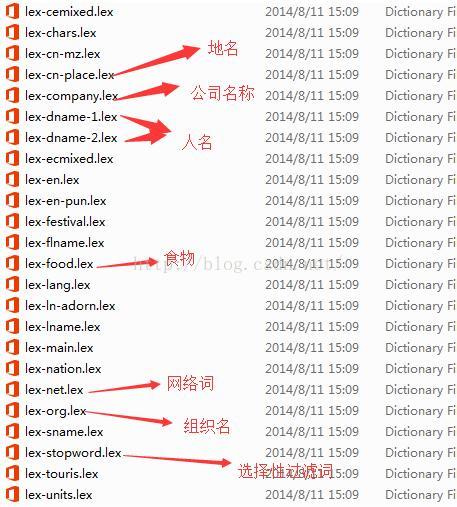
具体使用方法参考官方文档。
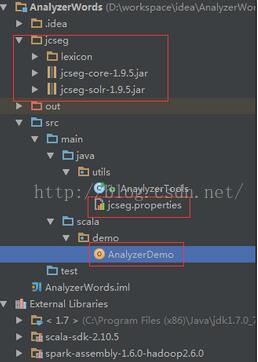
工程项目中导入Jcseg的相关jar包,同时确保lexicon(分词库)文件夹与jar包保持统一目录
分词规则的配置文件,放到指定目录下。确保程序能读取到内容。如图所示:
(2)配置jcseg.properties,具体可以参考官方文档来配置
#是否自动过滤停止词(0关闭, 1开启) jcseg.clearstopword=0
(3)分词代码实现过程
AnaylyzerTools中的anaylyzerWords(String str)方法实现文本分词。
import org.lionsoul.jcseg.ASegment;
import java.io.IOException;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.List;
import org.lionsoul.jcseg.core.ADictionary;
import org.lionsoul.jcseg.core.DictionaryFactory;
import org.lionsoul.jcseg.core.IWord;
import org.lionsoul.jcseg.core.JcsegException;
import org.lionsoul.jcseg.core.JcsegTaskConfig;
import org.lionsoul.jcseg.core.SegmentFactory;
/**
* Created by Administrator on 2016/4/6.
*/
public class AnaylyzerTools {
public static ArrayList<String> anaylyzerWords(String str){
JcsegTaskConfig config =new JcsegTaskConfig(AnaylyzerTools.class.getResource("").getPath()+"jcseg.properties");
ADictionary dic = DictionaryFactory.createDefaultDictionary(config);
ArrayList<String> list=new ArrayList<String>();
ASegment seg=null;
try {
seg = (ASegment) SegmentFactory.createJcseg(JcsegTaskConfig.COMPLEX_MODE, new Object[]{config, dic});
} catch (JcsegException e1) {
e1.printStackTrace();
}
try {
seg.reset(new StringReader(str));
IWord word = null;
while ( (word = seg.next()) != null ) {
list.add(word.getValue());
}
} catch (IOException e) {
e.printStackTrace();
}
return list;
}
public static void main(String[] args) {
String str="HBase中通过row和columns确定的为一个存贮单元称为cell。显示每个元素,每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引。迎泽区是繁华的地方,营业厅营业";
List<String> list=AnaylyzerTools.anaylyzerWords(str);
for(String word:list){
System.out.println(word);
}
System.out.println(list.size());
}
}
(4)Spark代码实现
import org.apache.spark._
import utils.AnaylyzerTools
/**
* Created by Administrator on 2016/4/6.
*/
object AnalyzerDemo {
//分词排序后取出词频最高的前10个
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("my app").setMaster("local")
val sc = new SparkContext(conf)
val data=sc.textFile("D:\\aaab.txt").map(x => {
val list=AnaylyzerTools.anaylyzerWords(x) //分词处理
list.toString.replace("[", "").replace("]", "").split(",")
}).flatMap(x => x.toList).map(x => (x.trim(),1)).reduceByKey(_+_).top(10)(Ord.reverse).foreach(println)
}
//分词排序
object Ord extends Ordering[(String,Int)]{
def compare(a:(String,Int), b:(String,Int))=a._2 compare (b._2)
}
}
数据文本:
















 1446
1446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









