






搜索引擎选型调研之Elasticsearch
最近的一个项目中,由于为了满足实时搜索的功能,一直在致力于选择合适的搜索引擎。起初的设计选型是Hbase+solr,用solr做hbase的二级索引,用coporcessor做索引同步。当单纯的对已有数据进行搜索时,solr表现还不错。但由于场景是实时建立索引时,solr会产生io阻塞,查询性能较差。再随着数据量的增加,solr的搜索效率会变得更低。为了满足实时搜索功能,随后发现了elasticsearch分布式搜索框架,期间也通过了多次反复验证讨论后,决定用elasticsearch做搜索引擎。它基本上所有我想要的特性都包含了:分布式搜索,分布式索引,自动分片,索引自动负载,自动发现,restful风格接口。于是开始使用部署了2台机子,即把索引分成5片,5个复本。
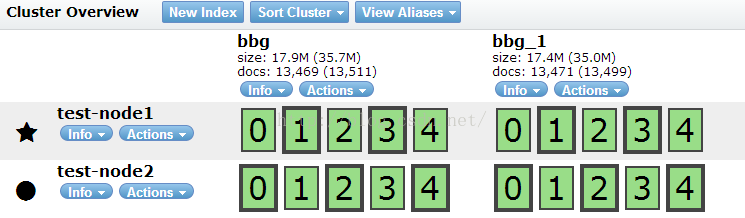
通过elasticsearch的一些管理工具插件可以很清晰的看到索引分片及分布情况:哪块分布在哪里,占用多少空间等都可以看到,并且可以管理索引。还发现当一台机挂了时,整个系统会对挂机里的内容重新分配到其它机器上,当挂掉的机重新加入集群时,又会重新把索引分配给它。当然,这些规则都是可以根据参数进行设置的,非常灵活。对它的搜索效率进行测试,查询时间基本上维持在200毫秒左右,第二次搜索的话因为有缓存,所以和solr差不多。但经过详细对比测试后发现,solr在建索引时的查询性能非常之差,因为solr在建索引时会产生io的阻塞,造成搜索性能的下降,但elasticsearch不会,因为它是先把索引的内容保存到内存之中,当内存不够时再把索引持久化到硬盘中,同时它还有一个队列,是在系统空闲时自动把索引写到硬盘中。
在浏览器输入:http://ip:9200/_plugin/bigdesk

Elasticsearch的存储方式有四种,1.像普通的lucene索引,存储在本地文件系统中。2.存储在分布式文件系统中,如freeds。3.存储在Hadoop的hdfs中。4.存储在亚马逊的s3云平台中。它支持插件机制,有丰富的插件。
Elasticsearch与Solr
性能对比:http://i.zhcy.tk/blog/elasticsearchyu-solr/
功能对比:http://solr-vs-elasticsearch.com/
elasticsearch官网:http://www.elasticsearch.org/
下面进行实战操作,使用Flume1.6+Elasticsearch2.3从数据采集到索引查询的操作。虽然官网推荐使用Logstash做数据采集,为了降低学习成本,另一方面对Flume比较熟悉。
一、Flume数据采集
(1) 编写自定义elasticsearch-sink的flume组件(默认flume与Elasticsearch版本冲突无法使用)
ElasticSearchCoreSink核心脚本:
public class ElasticSearchCoreSink extends AbstractSink implements Configurable{ private static Logger log = Logger.getLogger(ElasticSearchCoreSink.class); private String clusterName; //集群名称 private String indexName; //索引名称 private String indexType; //文档名称 private String hostName; //主机IP private long ttlMs=-1; //Elasticsearch的字段TTL失效时间 private String[] fields; //字段 private String splitStr; //扫描文本文件字段分隔符 private int batchSize; //缓冲提交数 private final Pattern pattern = Pattern.compile(TTL_REGEX,Pattern.CASE_INSENSITIVE); private Matcher matcher = pattern.matcher(""); private Client client=null; //Elasticsearch客户端 @Override public Status process() throws EventDeliveryException { Status status = null; Channel ch = getChannel(); Transaction txn = ch.getTransaction(); txn.begin(); try { Event event = ch.take(); String out = new String(event.getBody(),"UTF-8"); // Send the Event to the external repository. log.info("文本行信息>>>>"+out); int sz=out.split(splitStr).length; if(sz==fields.length){ String json=ElasticSearchClientFactory.generateJson(fields,out,splitStr); IndexRequestBuilder irb=client.prepareIndex(indexName, indexType).setSource(json); irb.setTTL(ttlMs); //存入缓冲 ElasticsearchWriter.addDocToCache(irb,batchSize); } txn.commit(); status = Status.READY; } catch (Throwable t) { txn.rollback(); status = Status.BACKOFF; if (t instanceof Error) { throw (Error)t; } } finally { txn.close(); } return status; } @Override public void configure(Context context) { String cn=context.getString("clusterName", "ClusterName"); String in=context.getString("indexName", "IndexName"); String it=context.getString("indexType", "IndexType"); String hn=context.getString("hostName", "127.0.0.1"); String tt=context.getString("ttl", "7*24*60*60*1000"); String fs=context.getString("fields", "content"); String ss=context.getString("splitStr", "\\|"); String bs=context.getString("batchSize","10"); this.clusterName=cn; this.indexName=in; this.indexType=it; this.hostName=hn; this.ttlMs=parseTTL(tt); this.splitStr=ss; this.fields=fs.trim().split(","); this.batchSize=Integer.parseInt(bs); for(String f:fields){ System.out.println("field@"+f); } if(client==null){ try { this.client=ElasticSearchClientFactory.getClient(hostName,clusterName); } catch (NoSuchClientTypeException e) { log.info("配置文件中:集群名字与主机有误,请检查!"); } } } private long parseTTL(String ttl) { matcher = matcher.reset(ttl); while (matcher.find()) { if (matcher.group(2).equals("ms")) { return Long.parseLong(matcher.group(1)); } else if (matcher.group(2).equals("s")) { return TimeUnit.SECONDS.toMillis(Integer.parseInt(matcher.group(1))); } else if (matcher.group(2).equals("m")) { return TimeUnit.MINUTES.toMillis(Integer.parseInt(matcher.group(1))); } else if (matcher.group(2).equals("h")) { return TimeUnit.HOURS.toMillis(Integer.parseInt(matcher.group(1))); } else if (matcher.group(2).equals("d")) { return TimeUnit.DAYS.toMillis(Integer.parseInt(matcher.group(1))); } else if (matcher.group(2).equals("w")) { return TimeUnit.DAYS.toMillis(7 * Integer.parseInt(matcher.group(1))); } else if (matcher.group(2).equals("")) { log.info("TTL qualifier is empty. Defaulting to day qualifier."); return TimeUnit.DAYS.toMillis(Integer.parseInt(matcher.group(1))); } else { log.debug("Unknown TTL qualifier provided. Setting TTL to 0."); return 0; } } log.info("TTL not provided. Skipping the TTL config by returning 0."); return 0; } }
ElasticsearchWriter缓冲提交组
public class ElasticsearchWriter { private static Logger log = Logger.getLogger(ElasticsearchWriter.class); private static int maxCacheCount = 10; // 缓存大小,当达到该上限时提交 private static Vector<IndexRequestBuilder> cache = null; // 缓存 public static Lock commitLock = new ReentrantLock(); // 在添加缓存或进行提交时加锁 private static int maxCommitTime = 60; // 最大提交时间,s public static Client client; static { log.info("elasticsearch init param"); try { client=ElasticSearchClientFactory.getClient(); cache = new Vector<IndexRequestBuilder>(maxCacheCount); // 启动定时任务,第一次延迟10执行,之后每隔指定时间执行一次 Timer timer = new Timer(); timer.schedule(new CommitTimer(), 10 * 1000, maxCommitTime * 1000); } catch (Exception ex) { ex.printStackTrace(); } } // 批量索引数据 public static boolean blukIndex(List<IndexRequestBuilder> indexRequestBuilders) { Boolean isSucceed = true; BulkRequestBuilder bulkBuilder = client.prepareBulk(); for (IndexRequestBuilder indexRequestBuilder : indexRequestBuilders) { bulkBuilder.add(indexRequestBuilder); } BulkResponse reponse = bulkBuilder.execute().actionGet(); if (reponse.hasFailures()) { isSucceed = false; } return isSucceed; } /** * 添加记录到cache,如果cache达到maxCacheCount,则提交 */ public static void addDocToCache(IndexRequestBuilder irb,int bachSize) { maxCacheCount=bachSize; commitLock.lock(); try { cache.add(irb); log.info("cache commit maxCacheCount:"+maxCacheCount); if (cache.size() >= maxCacheCount) { log.info("cache commit count:"+cache.size()); blukIndex(cache); cache.clear(); } } catch (Exception ex) { log.info(ex.getMessage()); } finally { commitLock.unlock(); } } /** * 提交定时器 */ static class CommitTimer extends TimerTask { @Override public void run() { commitLock.lock(); try { if (cache.size() > 0) { //大于0则提交 log.info("timer commit count:"+cache.size()); blukIndex(cache); cache.clear(); } } catch (Exception ex) { log.info(ex.getMessage()); } finally { commitLock.unlock(); } } } }
ElasticsearchClientFactory提供Client创建和bulk json功能
public class ElasticSearchClientFactory { private static Client client; public static Client getClient(){ return client; } public static Client getClient(String hostName, String clusterName) throws NoSuchClientTypeException { if (client == null) { // 集群模式 设置Settings System.out.println(">>>>>>>>>>>>>>>" + clusterName + ">>>>>" + hostName); Settings settings = Settings.settingsBuilder() .put("cluster.name", clusterName).build(); try { client = TransportClient .builder() .settings(settings) .build() .addTransportAddress( new InetSocketTransportAddress(InetAddress .getByName(hostName), 9300)); } catch (UnknownHostException e) { e.printStackTrace(); } } return client; } public static String generateJson(String[] fields,String text,String splitStr) throws ContentNoCaseFieldsException{ String[] texts=null; if(!StringUtils.isEmpty(text)){ texts=text.split(splitStr); if(texts.length==fields.length){ String json = ""; try { XContentBuilder contentBuilder = XContentFactory.jsonBuilder() .startObject(); for(int i=0;i<fields.length;i++){ contentBuilder.field(fields[i],texts[i]); } json = contentBuilder.endObject().string(); } catch (IOException e) { e.printStackTrace(); } return json; } } throw new ContentNoCaseFieldsException(); } }
(2) 配置Flume文件elasticsearch.conf
a1.sources =r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type =spooldir
a1.sources.r1.channels =c1
a1.sources.r1.spoolDir =/home/an/log
a1.sources.r1.fileHeader =true
# Describe the sink
a1.sinks.k1.type =org.plugins.sink.ElasticSearchCoreSink
a1.sinks.k1.hostName =192.168.226.120
a1.sinks.k1.indexName =dxmessages
a1.sinks.k1.indexType =dxmessage
a1.sinks.k1.clusterName =es_cloud
a1.sinks.k1.fields =rowkey,content,phone_no,publish_date
a1.sinks.k1.ttl =5m
a1.sinks.k1.splitStr =\\|
a1.sinks.k1.bachSize =100
# Use a channel which buffers events inmemory
a1.channels.c1.type =memory
a1.channels.c1.capacity =1000
a1.channels.c1.transactionCapacity =100
# Bind the source and sink to the channel
a1.sources.r1.channels =c1
a1.sinks.k1.channel =c1
二、建立Elasticsearch文档信息
Jcseg 作为国内知名的开源的中文分词器,对于中文分词有其独有的特点, 对于 elasticsearch 这一不错的文档检索引擎来说 Elasticsearch + Jcseg 这个组合,在处理中文检索上,可以说是黄金搭档啊!!最重要的是:方便,简单,易用,功能强大!Elasticsearch与jcseg整合,参考https://github.com/lionsoul2014/jcseg。配置jcseg.properties文件内容如下(不待翻译了,多看几遍就看懂了):
# jcseg properties file. # Jcseg function #maximum match length. (5-7) jcseg.maxlen=5 #recognized the chinese name.(1 to open and 0 to close it) jcseg.icnname=1 #maximum chinese word number of english chinese mixed word. jcseg.mixcnlen=3 #maximum length for pair punctuation text. jcseg.pptmaxlen=15 #maximum length for chinese last name andron. jcseg.cnmaxlnadron=1 #Wether to clear the stopwords.(set 1 to clear stopwords and 0 to close it) jcseg.clearstopword=0 #Wether to convert the chinese numeric to arabic number. (set to 1 open it and 0 to close it) # like '\u4E09\u4E07' to 30000. jcseg.cnnumtoarabic=1 #Wether to convert the chinese fraction to arabic fraction. jcseg.cnfratoarabic=1 #Wether to keep the unrecognized word. (set 1 to keep unrecognized word and 0 to clear it) jcseg.keepunregword=1 #Wether to start the secondary segmentation for the complex english words. jcseg.ensencondseg = 1 #min length of the secondary simple token. (better larger than 1) jcseg.stokenminlen = 2 #thrshold for chinese name recognize. # better not change it before you know what you are doing. jcseg.nsthreshold=1000000 #The punctuations that will be keep in an token.(Not the end of the token). jcseg.keeppunctuations=@#%.&+ ####about the lexicon #prefix of lexicon file. lexicon.prefix=lex #suffix of lexicon file. lexicon.suffix=lex #abusolte path of the lexicon file. #Multiple path support from jcseg 1.9.2, use ';' to split different path. #example: lexicon.path = /home/chenxin/lex1;/home/chenxin/lex2 (Linux) # : lexicon.path = D:/jcseg/lexicon/1;D:/jcseg/lexicon/2 (WinNT) #lexicon.path=/java/JavaSE/jcseg/lexicon lexicon.path={jar.dir}/lexicon #Wether to load the modified lexicon file auto. lexicon.autoload=0 #Poll time for auto load. (seconds) lexicon.polltime=120 ####lexicon load #Wether to load the part of speech of the entry. jcseg.loadpos=1 #Wether to load the pinyin of the entry. jcseg.loadpinyin=0 #Wether to load the synoyms words of the entry. jcseg.loadsyn=0在elasticsearch中建立对应索引模型:
curl -XPOST 'http://192.168.226.120:9200/dxmessages?pretty' -d '{ "mappings": { "dxmessage": { "_ttl": { "enabled": true }, "properties" : { "rowkey" : {"type" : "string","index" : "not_analyzed"}, "content" :{"type" : "string","analyzer" : "jcseg_simple","searchAnalyzer": "jcseg"}, "phone_no" : {"type" : "string","index" : "not_analyzed"}, "publish_date" :{"type" : "string","index" : "not_analyzed"} } } } }'
三、提交验证数据
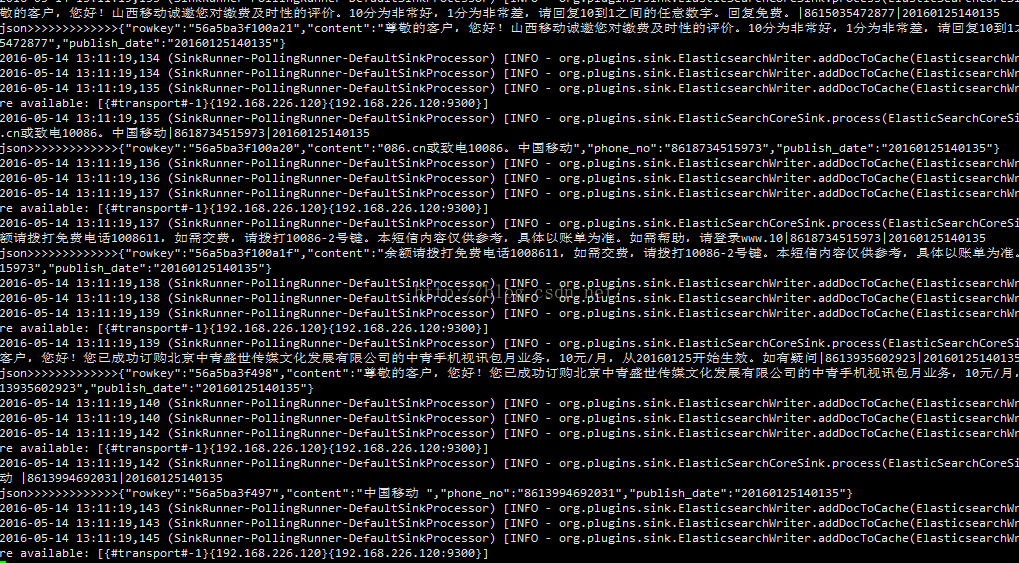
Flume采集数据
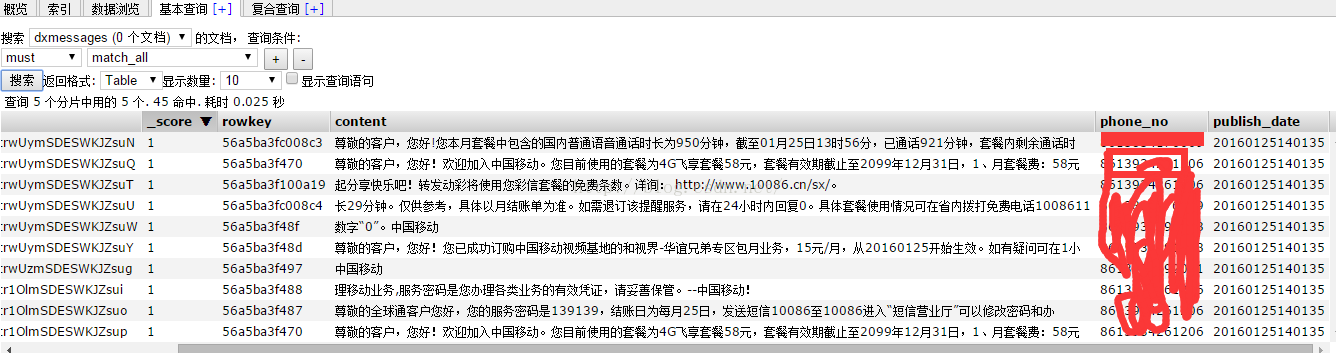
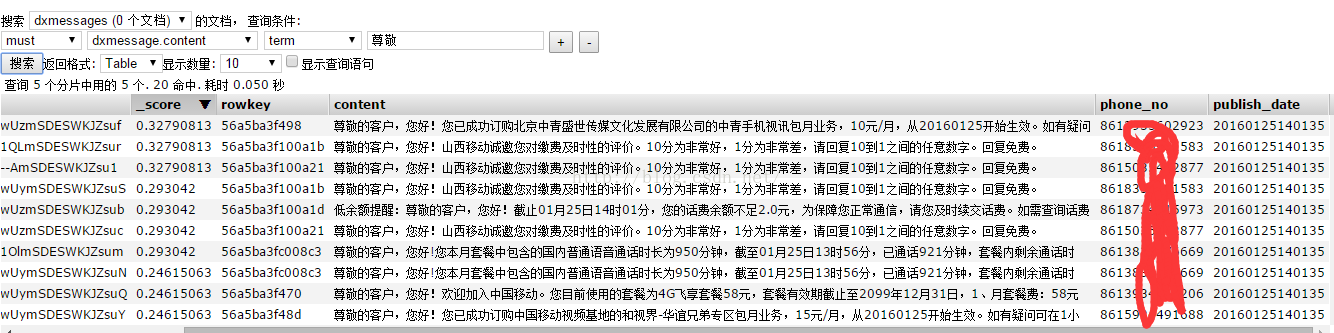
查询content字段存在“尊敬”相关信息














 6617
6617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









