









1、理解执行计划
1-1.什么是执行计划
oracle数据库在执行sql语句时,oracle的优化器会根据一定的规则确定sql语句的执行路径,以确保sql语句能以最优性能执行.在oracle数据库系统中为了执行sql语句,oracle可能需要实现多个步骤,这些步骤中的每一步可能是从数据库中物理检索数据行,或者用某种方法准备数据行,让编写sql语句的用户使用,oracle用来执行语句的这些步骤的组合被称为执行计划。
当执行一个sql语句时oracle经过了4个步骤:
①.解析sql语句:主要在共享池中查询相同的sql语句,检查安全性和sql语法与语义。
②.创建执行计划及执行:包括创建sql语句的执行计划及对表数据的实际获取。
③.显示结果集:对字段数据执行所有必要的排序,转换和重新格式化。
④.转换字段数据:对已通过内置函数进行转换的字段进行重新格式化处理和转换.
1-2.查看执行计划
查看sql语句的执行计划,比如一些第三方工具 需要先执行utlxplan.sql脚本创建explain_plan表。
SQL> conn system/123456 as sysdba
-- 如果下面语句没有执行成功,可以找到这个文件,单独执行这个文件里的建表语句
SQL> @/rdbms/admin/utlxplan.sql
SQL> grant all on sys.plan_table to public;set autotrace on explain:执行sql,且仅显示执行计划
set autotrace on statistics:执行sql 且仅显示执行统计信息
set autotrace on :执行sql,且显示执行计划与统计信息,无执行结果
set autotrace traceonly:仅显示执行计划与统计信息,无执行结果
set autotrace off:关闭跟踪显示计划与统计
比如要执行SQL且显示执行计划,可以使用如下的语句:
SQL> set autotrace on explain
SQL> col ename format a20;
SQL> select empno,ename from emp where empno=7369;SQL> explain plan for
2 select * from cfreportdata where outitemcode='CR04_00160' and quarter='1' and month='2015';
Explained
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 3825643284
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%C
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 115 | 3
| 1 | TABLE ACCESS BY INDEX ROWID| CFREPORTDATA | 1 | 115 | 3
|* 2 | INDEX RANGE SCAN | PK_CFREPORTDATA | 1 | | 2
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OUTITEMCODE"='CR04_00160' AND "MONTH"='2015' AND "QUARTER"='1')
filter("MONTH"='2015' AND "QUARTER"='1')
15 rows selectedPL/SQL DEVELOPER提供了一个执行计划窗口,如果在SQL Windows的窗口,按F8是执行该sql,按f5会显示该sql的执行计划。
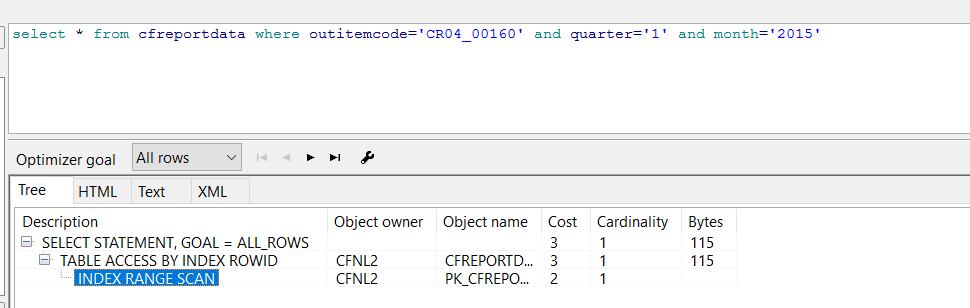
3.理解执行计划
1.全表扫描(full table scans):这种方式会读取表中的每一条记录,顺序地读取每一个数据块直到结尾标志,对于一个大的数据表来说,使用全表扫描会降低性能,但有些时候,比如查询的结果占全表的数据量的比例比较高时,全表扫描相对于索引选择又是一种较好的办法。
2.通过ROWID值获取(table access by rowid):行的rowid指出了该行所在的数据文件,数据块及行在该块中的位置,所以通过rowid来存取数据可以快速定位到目标数据上,是oracle存取单行数据的最快方法。
3.索引扫描(index scan):先通过索引找到对象的rowid值,然后通过rowid值直接从表中找到具体的数据,能大大提高查找的效率。
2.连接查询的表顺序
默认情况下,优化器会使用all_rows优化方式,也就是基于成本的优化器CBO生成执行计划,CBO方式会根据统计信息来产生执行计划.
统计信息给出表的大小,多少行,每行的长度等信息,这些统计信息起初在库内是没有的,是做analyee后才发现的,很多时候过期统计信息会令优化器做出一个错误的执行计划,因此应及时更新这些信息。
在CBO模式下,当对多个表进行连接查询时,oracle分析器会按照从右到左的顺序处理from子句中的表名。例如:
select a.empno,a.ename,c.deptno,c.dname,a.log_action from emp_log a,emp b,dept c如果有3个以上的表连接查询,就需要 选择交叉表作为基础表。交叉表是指那个被其他表所引用的表,由于emp_log是dept与emp表中的交叉表,既包含dept的内容又包含emp的内容。
select a.empno,a.ename,c.deptno,c.dname,a.log_action from emp b,dept c,emp_log a;
3.指定where条件顺序
在查询表时,where子句中条件的顺序往往影响了执行的性能。默认情况下,oracle采用自下而上的顺序解析where子句,因此在处理多表查询时,表之间的连接必须写在其他的where条件之前,但是过滤数据记录的条件则必须写在where子句的尾部,以便在过滤了数据之后再进行连接处理,这样可以提升sql语句的性能。
SELECT a.empno, a.ename, c.deptno, c.dname, a.log_action, b.sal
FROM emp b, dept c, emp_log a
WHERE a.deptno = b.deptno AND a.empno=b.empno AND c.deptno IN (20, 30) SELECT a.empno, a.ename, c.deptno, c.dname, a.log_action, a.mgr
FROM emp b, dept c, emp_log a
WHERE c.deptno IN (20, 30) AND a.deptno = b.deptno4.避免使用*符号
有时我们习惯使用*符号,如
SELECT * FROM emp5.使用decode函数
是Oracle才具有的一个功能强大的函数
比如统计emp表中部门编号为20和部门编号为30的员工的人数和薪资汇总,如果不使用decode那么就必须用两条sql语句
select count(*),SUM(sal) from emp where deptno=20;
union
select count(*),SUM(sal) from emp where deptno=30;通过decode语句,可以再一个sql查询中获取到相同的结果,并且将两行结果显示为单行。
SELECT COUNT (DECODE (deptno, 20, 'X', NULL)) dept20_count,
COUNT (DECODE (deptno, 30, 'X', NULL)) dept30_count,
SUM (DECODE (deptno, 20, sal, NULL)) dept20_sal,
SUM (DECODE (deptno, 30, sal, NULL)) dept30_sal
FROM emp;关于decode函数详解:http://blog.csdn.net/ochangwen/article/details/52733273
6.使用where而非having
where子句和having子句都可以过滤数据,但是where子句不能使用聚集函数,如count max min avg sum等函数。因此通常将Having子句与Group By子句一起使用
注意:当利用Group By进行分组时,可以没有Having子句。但Having出现时,一定会有Group By
需要了解的是,WHERE语句是在GROUP BY语句之前筛选出记录,而HAVING是在各种记录都筛选之后再进行过滤。也就是说HAVING子句是在从数据库中提取数据之后进行筛选的,因此在编写SQL语句时,尽量在筛选之前将数据使用WHERE子句进行过滤,因此执行的顺序应该总是这样。
①.使用WHERE子句查询符合条件的数据
②.使用GROUP BY子句对数据进行分组。
③.在GROUP BY分组的基础上运行聚合函数计算每一组的值
④.用HAVING子句去掉不符合条件的组。
例子:查询部门20和30的员工薪资总数大于1000的员工信息
select empno,deptno,sum(sal)
from emp group by empno,deptno
having sum(sal) > 1000 and deptno in (20,30);select empno,deptno,sum(sal)
from emp where deptno in (20,30)
group by empno,deptno having sum (sal) > 1000;7.使用UNION而非OR
如果要进行OR运算的两个列都是索引列,可以考虑使用union来提升性能。
例子:比如emp表中,empno和ename都创建了索引列,当需要在empno和ename之间进行OR操作查询时,可以考虑将这两个查询更改为union来提升性能。
select empno,ename,job,sal from emp where empno > 7500 OR ename LIKE 'S%';select empno,ename,job,sal from emp where empno > 7500
UNION
select empno,ename,job,sal from emp where ename LIKE 'S%';如果坚持使用OR语句,①. 需要记住尽量将返回记录最少的索引列写在最前面,这样能获得较好的性能,例如empno > 7500 返回的记录要少于对ename的查询,因此在OR语句中将其放到前面能获得较好的性能。②.另外一个建议是在 要对单个字段值进行OR计算的时候,可以考虑使用IN来代替
select empno,ename,job,sal from emp where deptno=20 OR deptno=30;8.使用exists而非IN
比如查询位于芝加哥的所有员工列表可以考虑使用IN
SELECT *
FROM emp
WHERE deptno IN (SELECT deptno
FROM dept
WHERE loc = 'CHICAGO');SELECT a.*
FROM emp a
WHERE NOT EXISTS (SELECT 1
FROM dept b
WHERE a.deptno = b.deptno AND loc = 'CHICAGO'); SELECT *
FROM emp
WHERE deptno NOT IN (SELECT deptno
FROM dept
WHERE loc = 'CHICAGO'); SELECT a.*
FROM emp a, dept b
WHERE a.deptno = b.deptno AND b.loc <> 'CHICAGO'; select a.* from emp a
where NOT EXISTS (
select 1 from dept b where a.deptno =b.deptno and loc='CHICAGO');PLSQL在处理逻辑表达式值的时候,使用的是短路径的计算方式。
DECLARE
v_sal NUMBER := &sal; --使用绑定变量输入薪资值
v_job VARCHAR2 (20) := &job; --使用绑定变量输入job值
BEGIN
IF (v_sal > 5000) OR (v_job = '销售') --判断执行条件
THEN
DBMS_OUTPUT.put_line ('符合匹配的OR条件');
END IF;
END; 举个例子,对于and逻辑运算符来说,只有左右两边的运算为真,结果才为真。如果前面的结果第一个运算时false值,就不会进行第二个运算、
DECLARE
v_sal NUMBER := &sal; --使用绑定变量输入薪资值
v_job VARCHAR2 (20) := &job; --使用绑定变量输入job值
BEGIN
IF (Check_Sal(v_sal) > 5000) AND (v_job = '销售') --判断执行条件
THEN
DBMS_OUTPUT.put_line ('符合匹配的AND条件');
END IF;
END; DECLARE
v_sal NUMBER := &sal; --使用绑定变量输入薪资值
v_job VARCHAR2 (20) := &job; --使用绑定变量输入job值
BEGIN
IF (v_job = '销售') AND (Check_Sal(v_sal) > 5000) --判断执行条件
THEN
DBMS_OUTPUT.put_line ('符合匹配的AND条件');
END IF;
END;
10.避免隐式类型转换














 366
366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









