







一、HDFS概念
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets. HDFS relaxes a few POSIX requirements to enable streaming access to file system data. HDFS was originally built as infrastructure for the Apache Nutch web search engine project. HDFS is now an Apache Hadoop subproject. The project URL is http://hadoop.apache.org/hdfs/.
HDFS是一个主/从(Mater/Slave)体系结构,从最终用户的角度来看,它就像传统的文件系统一样,可以通过目录路径对文件执行CRUD操作。但由于分布式存储的性质,HDFS集群拥有一个NameNode和多个DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。客户端连接NameNode以获取文件的元数据,而真正的文件I/O操作是直接和DataNode进行交互的。 下图为HDFS总体结构示意图。
二、HDFS特点
1、HDFS的优势
集群规模动态扩展:节点动态加入到集群,可以数百数千个
流式读写:HDFS的设计思想“一次写入,多次读取”,一个数据集一旦由数据源生成,就会被复制分发到不同的存储节点中,然后响应各种各样的数据分析任务请求。HDFS处理 的应用一般是批处理,而不是用户交互式处理, 注重的是数据的吞吐量而不是数据的访问速度 。
廉价的商用机器:HDFS设计时充分考虑可靠性、安全性及高可用性,因此Hadoop对硬件要求比较低,可以运行于廉价的商用机器集群,无需昂贵的高可用性机器
2. HDFS的局限性:
不适合低延迟数据访问:HDFS针对处理超大数据量高而设计,这种设计是以高延迟为代价的。不适合低延迟的系统。
不支持多用户写入及任意修改文件:不支持多用户对同一文件进行操作,而且写操作只能在文件末尾完成,即追加操作。
三、HDFS体系结构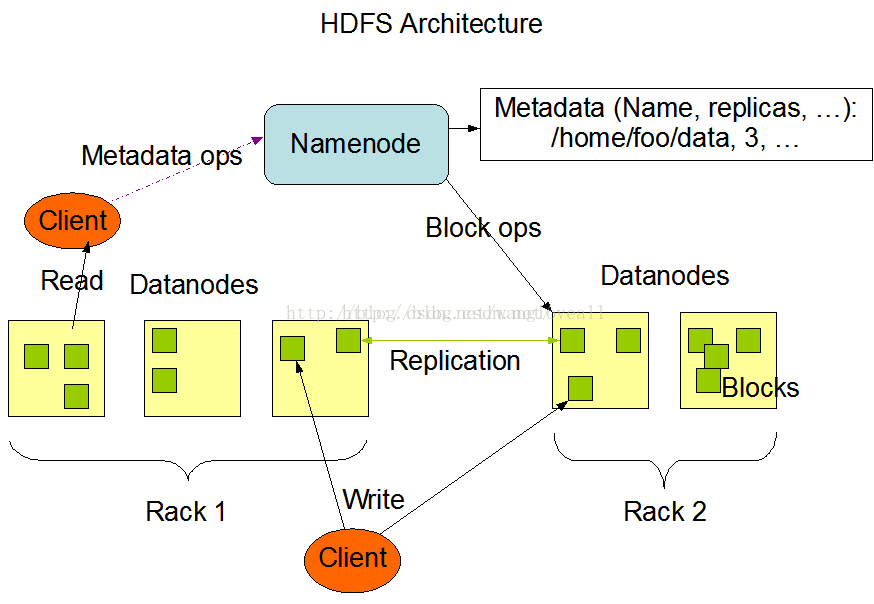
NameNode分布式文件系统中的管理者。主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。
2、 Secondary namenode
并非NameNode的热备; 辅助NameNode,分担其工作量; 定期合并fsimage和fsedits,推送给NameNode; 在紧急情况下,可辅助恢复NameNode。
3、 DataNode
DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同时周期性地将所有存在的Block信息发送给NameNode。
Slavel 存储实际的数据块 执行数据块读/写
4、 Client
文件切分与NameNode交互,获取文件位置信息; 与DataNode交互,读取或者写入数据; 管理HDFS; 访问HDFS。
5、文件写入
1) Client向NameNode发起文件写入的请求。
6、 文件读取
1) Client向NameNode发起文件读取的请求。














 755
755











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









