







主要内容
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("sentences", new KestrelSpout("kestrel.backtype.com",
22133,
"sentence_queue",
new StringScheme()));
builder.setBolt("split", new SplitSentence(), 10)
.shuffleGrouping("sentences");
builder.setBolt("count", new WordCount(), 20)
.fieldsGrouping("split", new Fields("word"));
上面的topology从Kestrel queue读取句子,将这些句子划分成词组,然后按照前面划分词组时统计的每个词的次数发送每个词。离开spout的某个tuple可能会触发创建很多基于它的tuples:句子中每个单词都会对应一个tuple,同时每个单词的次数也会对应一个tuple。消息的树状结构如下所示:
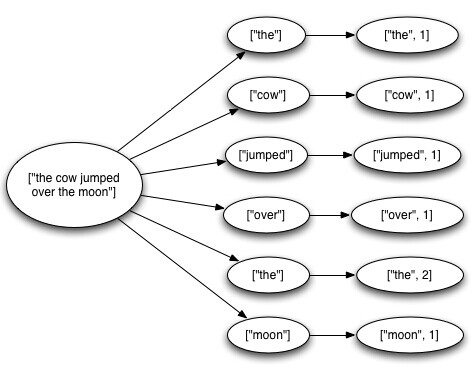
当元组树已经耗尽并且树中的每个消息都已被处理时,Storm认为元组从“完全处理”的一个元组中脱离。 当其树的消息未能在指定的超时内完全处理时,元组被认为失败。 可以使Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS配置在特定于拓扑的基础上配置此超时,默认值为30秒。
<span style="font-family:Comic Sans MS;font-size:14px;">public interface ISpout extendsSerializable {
voidopen(Map conf, TopologyContext context,SpoutOutputCollector collector);
voidclose();
voidnextTuple();
voidack(Object msgId);
voidfail(Object msgId);
}</span>当消息完整处理或失败时发生了什么
为了理解这个问题,让我们来看看一个元组从一个出口的生命周期。作为参考,这里是spouts实现的接口(有关更多信息,请参阅Javadoc):<span style="font-family:Comic Sans MS;font-size:14px;">public interface ISpout extends Serializable {
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
void close();
void nextTuple();
void ack(Object msgId);
void fail(Object msgId);
}</span>首先,Storm通过Spout的nextTuple方法从Spout申请一个tuple。在open方法中,Spout使用此方法提供SpoutOutputCollector去发射一个tuple到输出streams中去。当发射一个tuple时,Spout会提供一个“message id”,用来后面区分不同的tuple。例如, KestrelSpout从kestrel队列中读取消息,然后在发射时会将Kestrel为消息提供的id作为“message id”。发射一条消息到SpoutOutputCollector,如下所示:
<span style="font-family:Comic Sans MS;font-size:14px;">_collector.emit(newValues("field1", "field2", 3), msgId);</span>然后,这个tuple会发送到bolts,同时Storm会跟踪已被创建的消息树状图。如果Storm检测到一个tuple已被“fully processed”, Storm将会在发射这个tuple的Spout上调用ack方法,参数msgId就是这个Spout提供给Storm的“message id”。类似的,如果这个tuple超时了, Storm会调用Spout上调用fail方法。注意, 一个tuple只能被创建它的Spout task上进行acked或者failed。因此,即使一个Spout在集群上正在执行很多tasks,一个tuple也只能被创建它的task进行acked或failed,而其他的task则不行。
再次使用KestrelSpout作为例子,看一下Spout是怎样保证消息处理的。当KestrleSpout从Kestrel 队列中拿出消息后,它打开这个消息。这就意味着消息并不会真正被从队列取出,而是处于等待状态,它需要确认消息已经被完整处理。当处于挂起(等待)状态时,消息不会被发送到队列的其他消费者。此外,如果客户端断开连接,则将该客户端的所有待处理消息放回队列。当打开消息时,Kestrel向客户端提供消息的数据以及消息的唯一ID。当将元组发送到SpoutOutputCollector时,KestrelSpout使用该确切的id作为元组的“消息id”。稍后,当在KestrelSpout上调用ack或fail时,KestrelSpout向Kestrel发送一个ack或fail消息,消息id将消息从队列中取出或重新启动。
消息可靠性
元组创建时通知storm
public class SplitSentence extends BaseRichBolt {
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context, OutputCollector collector){
_collector = collector;
}
public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
_collector.emit(tuple, new Values(word));
}
_collector.ack(tuple);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}_collector.emit(new Values(word));一个输出的元组可以被锚定到多个输入元组上,叫做多锚定(multi-anchoring)。这在做流的合并或者聚合的时候非常有用。一个多锚定的元组处理失败,会导致Spout上重新处理对应的多个输入元组。多锚定是通过指定一个多个输入元组的列表而不是单个元组来完成的。例如:
List<Tuple> anchors = new ArrayList<Tuple>();
anchors.add(tuple1);
anchors.add(tuple2);
_collector.emit(anchors, new Values(word));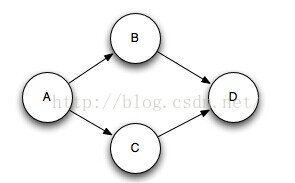
Spout元组A触发了B和C两个元组,而这两个元组作为输入,共同作用后触发D元组。
元组处理完毕后通知storm
当前消息树的根元组处理失败了,可以利用OutputCollector的fail函数来立即通知Storm。例如,应用程序可能捕捉到了数据库客户端的一个异常,就显示地通知Storm输入元组处理失败。通过显示地通知Storm元组处理失败,这个Spout元组就不用等待超时而能更快地被重新处理。
Storm需要占用内存来跟踪每个元组,所以每个被处理的元组都必须被确认。因为如果不对每个元组进行确认,任务最终会耗光可用的内存。
做聚合或者合并操作的Bolt可能会延迟确认一个元组,直到根据一堆元组计算出了一个结果后,才会确认。聚合或者合并操作的Bolt,通常也会对他们的输出元组进行多锚定。
Storm以一种有效的方式实现可靠性
acker任务
一个Storm拓扑有一组特殊的"acker"任务,它们负责跟踪由每个Spout元组触发的消息的处理状态。当一个"acker"看到一个Spout元组产生的有向无环图中的消息被完全处理,就通知当初创建这个Spout元组的Spout任务,这个元组被成功处理。可以通过拓扑配置项Config.TOPOLOGY_ACKER_EXECUTORS来设置一个拓扑中acker任务executor的数量。Storm默认TOPOLOGY_ACKER_EXECUTORS和拓扑中配置的Worker的数量相同(关于executor和Worker的介绍,参见理解Storm并发一文)--对于需要处理大量消息的拓扑来说,需要增大acker executor的数量。元组的生命周期
理解Storm的可靠性实现方式的最好方法是查看元组的生命周期和元组构成的有向无环图。当拓扑的Spout或者Bolt中创建一个元组时,都会被赋予一个随机的64比特的标识(message id)。acker任务使用这些id来跟踪每个Spout元组产生的有向无环图的处理状态。在Bolt中产生一个新的元组时,会从锚定的一个或多个输入元组中拷贝所有Spout元组的message-id,所以每个元组都携带了自己所在元组树的根节点Spout元组的message-id。当确认一个元组处理成功了,Storm就会给对应的acker任务发送特定的消息--通知acker当前这个Spout元组产生的消息树中某个消息处理完了,而且这个特定消息在消息树中又产生了一个新消息(新消息锚定的输入是这个特定的消息)。举个例子,假设"D"元组和"E"元组是基于“C”元组产生的,那么下图描述了确认“C”元组成功处理后,元组树的变化。图中虚线框表示的元组代表已经在消息树上被删除了:
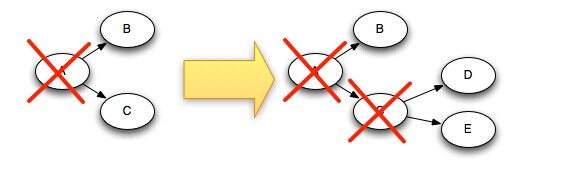
当“C”从树中移除时,同一时刻,“D”和“E”会加到树中。树永远不能过早的结束。
正如上面已经提到的,在一个拓扑中,可以有任意数量的acker任务。这导致了如下的两个问题:
1、当拓扑中的一个元组确认被处理完,或者产生一个新的元组时,Storm应该通知哪个acker任务?
2、通知了acker任务后,acker任务如何通知到对应的Spout任务?
Storm采用对元组中携带的Spout元组message-id哈希取模的方法来把一个元组映射到一个acker任务上(所以同一个消息树里的所有消息都会映射到同一个acker任务)。因为每个元组携带了自己所处的元组树中根节点Spout元组(可能有多个)的标识,所以Storm就能决定通知哪个acker任务。
当一个Spout任务产出一个新的元组,仅需要简单的发送一个消息给对应的acker(Spout元组message-id哈希取模)来告知Spout的任务标示(task id),以此来通知acker当前这个Spout任务负责这个消息。当acker看到一个消息树被完全处理完,它就能根据处理的元组中携带的Spout元组message-id来确定产生这个Spout元组的task id,然后通知这个Spout任务消息树处理完成(调用 Spout任务的ack函数)。
实现细节
对于拥有上万节点(或者更多)的巨大的元组树,跟踪所有的元组树会耗尽acker使用的内存。acker任务不显示地(记录完整的树型结构)跟踪元组树,相反它使用了一种每个Spout元组只占用固定大小空间(大约20字节)的策略。这个跟踪算法是Storm工作的关键,而且是重大突破之一。一个acker任务存储了从一个Spout元组message-id到一对值的映射关系spout-message-id--><spout-task-id, ack-val>。第一个值是创建了这个Spout元组的任务id,用来后续处理完成时通知到这个Spout任务。第二个值是一个64比特的叫做“ack val”的数值。它是简单的把消息树中所有被创建或者被确认的元组message-id异或起来的值。每个消息创建和被确认处理后都会异或到"ack val"上,A xor A = 0,所以当一个“ack val”变成了0,说明整个元组树都完全被处理了。无论是很大的还是很小的元组树,"ack val"值都代表了整个元组树中消息的处理状态。由于元组message-id是随机的64比特的整数,所以同一个元组树中不同元组message-id发生撞车的可能性特别小,因此“ack val”意外的变成0的可能性非常小。如果真的发生了这种情况,而恰好这个元组也处理失败了,那仅仅会导致这个元组的数据丢失。
使用异或操作来跟踪消息树处理状态的想法非常有才。因为消息的数量可能有成千上万条,每个都单独跟踪(读者可以思考下怎么搞)是非常低效而且不可水平扩展的。而且采用异或的方式后,就不依赖于acker接收到消息的顺序了。
搞明白了可靠性的算法,让我们看看所有失败的场景下Storm如何避免数据丢失:
Bolt任务挂掉:导致一个元组没有被确认,这种场景下,这个元组所在的消息树中的根节点Spout元组会超时并被重新处理
acker任务挂掉:这种场景下,这个acker挂掉时正在跟踪的所有的Spout元组都会超时并被重新处理
Spout任务挂掉:这种场景下,需要应用自己实现检查点机制,记录当前Spout成功处理的进度,当Spout任务挂掉之后重启时,继续从当前检查点处理,这样就能重新处理失败的那些元组了。
调整可靠性
acker任务是轻量级的,所以在一个拓扑中不需要太多的acker任务。可以通过Storm UI(id为"__acker"的组件)来观察acker任务的性能。如果吞吐量看起来不正常,就需要添加更多的acker任务。
去掉可靠性
如果可靠性无关紧要--例如你不关心元组失败场景下的消息丢失--那么你可以通过不跟踪元组的处理过程来提高性能。不跟踪一个元组树会让传递的消息数量减半,因为正常情况下,元组树中的每个元组都会有一个确认消息。另外,这也能减少每个元组需要存储的id的数量(指每个元组存储的Spout message-id),减少了带宽的使用。有三种方法来去掉可靠性:
设置Config.TOPOLOGY_ACKERS为0。这种情况下,Storm会在Spout吐出一个元组后立马调用Spout的ack函数。这个元组树不会被跟踪。当产生一个新元组调用emit函数的时候通过忽略消息message-id参数来关闭这个元组的跟踪机制。
如果你不关心某一类特定的元组处理失败的情况,可以在调用emit的时候不要使用锚定。由于它们没有被锚定到某个Spout元组上,所以当它们没有被成功处理,不会导致Spout元组处理失败。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









