







 本文探讨了求解众数的算法,包括哈希表、排序和二叉搜索树,并提出了一种基于二叉搜索树的改进算法——ModeTree。ModeTree每个节点包含key和times(出现次数),通过左右旋转维护性质,使得众数更靠近根节点。算法复杂度在最坏情况下为O(n^2),但可以通过随机化上旋优化。在众数出现次数多的情况下,效率接近O(n)。
本文探讨了求解众数的算法,包括哈希表、排序和二叉搜索树,并提出了一种基于二叉搜索树的改进算法——ModeTree。ModeTree每个节点包含key和times(出现次数),通过左右旋转维护性质,使得众数更靠近根节点。算法复杂度在最坏情况下为O(n^2),但可以通过随机化上旋优化。在众数出现次数多的情况下,效率接近O(n)。
求众数是一个古老的问题。众数:是一组数据中出现次数最多的数值。求众数的主要算法有:
1,hash表 时间复杂度为O(n),但空间极大,通常让人难以承受
2,排序 对元素表进行排序,然后统计元素出现的个数,得出众数。时间复杂度为O(nlgn),空间复杂度为O(n)
3,二叉搜索树 用rbtree之类的树来实现。如果实现的好,复杂度和排序接近。
这三种方法各有所长,但是都有一些问题。所以最近我脑洞大开,想扩张二叉搜索树以实现更简单、更高效的众数算法。这个算法的复杂度约为O(nlgn),但是实际来看,效率比普通的二叉树实现效率高得多。看一下简单的性能测试(随机数据):
- Core(TM) i3-3240T 2.90GHz
- 4.00GB
- Windows 7 32位
| 数据量/n | MyTreeTimes/ms | std::mapTimes/ms | pbds::rbtreeTimes/ms | std::sortTimes/ms |
|---|---|---|---|---|
| 100000 | 15 | 78 | 93 | 32 |
| 1000000 | 143 | 811 | 936 | 343 |
| 10000000 | 1435 | 8253 | 9397 | 4040 |
可见,这种方法比现有的树算法优势明显,对于排序方法也有一定优势(当然这也有手写快于封装的因素)。但这还只是随机数据的测试,如果数据是特殊的(众数出现次数很多),效率会更高。
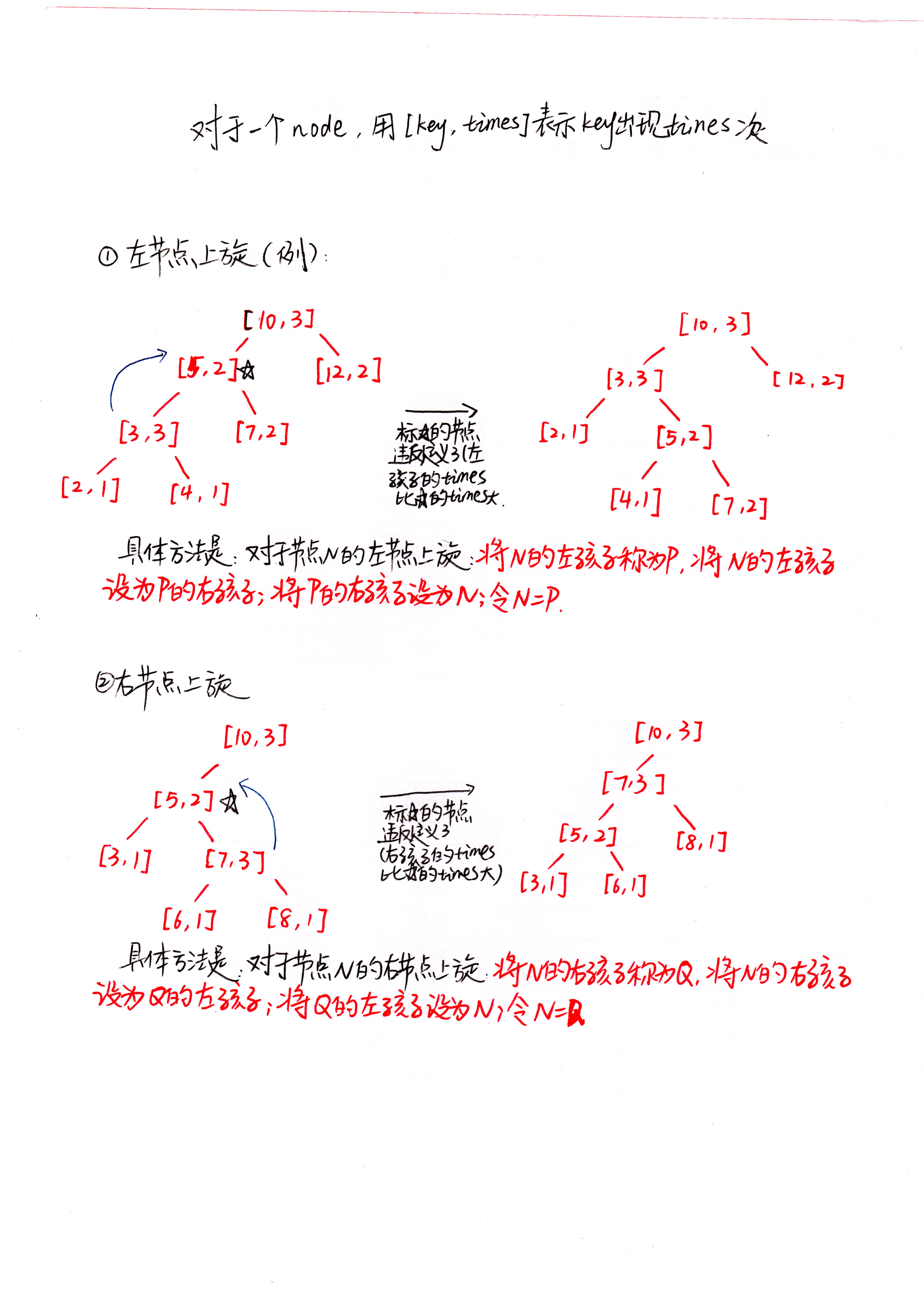
好了关子卖完了,这种算法的思路很简(ju)单(ruo):对于一个bst,每一个node记录两个值:key和times(数字和出现的次数)。bst基于key构建,而每次插入时,一旦当前节点子树的times大于当前节点的times,就把子树上旋。经过多次插入后,根的key即是一个众数,times即是它出现的次数。
对于这种树(下面称ModeTree)的定义是:
- 空树是ModeTree
- 一个对{key, times, leftchild, rightchild}称为一个节点
- 如果对于任意一个节点N,N的左孩子是空树或者左孩子的key小于N的key,N的右节点是空树或者右孩子的key大于N的key,且N的times大于或等于它的孩子的times,则N是ModeTree
如果还是不太懂,我们就把需要的知识复习一下。
0、数据结构
普通二叉树多一个times值、、这个没什么问题,直接上代码
typedef struct node;
typedef node *tree;
struct node {
int key;
/*这个是数字本身*/
int times;
/*出现的次数*/
tree lc, rc;
/*左右孩子*/
};
tree root;1、treap的左右旋转
这里的思想和treap有点接近,而且旋转操作和treap是一样一样的。可以参考我的其他文章http://blog.csdn.net/oiljt12138/article/details/50411996
在这里用一幅图解释左右旋转(注意具体方法):
代码给出
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1579
1579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









