







在大学学习数据库的时候,不明白为什么会学习很多关系代数、设计范式的理论。但是,有了这些理论基础,在遇到问题的时候脑袋会有灵光一闪的感觉。那种感觉很像是大雾天太阳照射大地的感觉,心中一片光亮。^_^
那么,范式是什么呢?
课本中的定义:范式是“符合某一种级别的关系模式的集合,表示一个关系内部各属性之间的联系的合理化程度”。–《数据库理论》
通俗的讲,他是一套成型的设计原则,照着这种原则设计数据库能够少走弯路。
接下来,简单的介绍下三个范式。
One
1NF的定义为:符合1NF的关系中的每个属性都不可再分。下表所示的情况,就不符合1NF的要求。
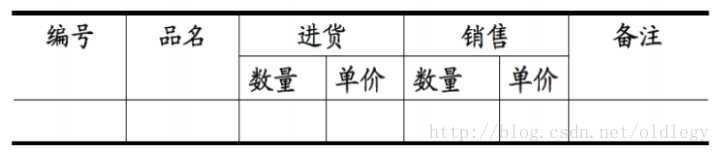
同样的,下表中也不符合1NF:
| 用户id | 用户名 | 所属角色id |
|---|---|---|
| 1 | user1 | 2,5,9 |
一般来说上边的用户表的方式较为常见,我在刚毕业编程的时候,曾经有朋友交给我这种方式,也让我吃了一些苦头。
下表符合第一范式:
| 编号 | 品名 | 进货数量 | 进货单价 | 销售数量 | 销售单价 | 备注 |
|---|---|---|---|---|---|---|
用户表:
| 用户id | 用户名 |
|---|---|
| 1 | user1 |
用户角色关系表
| 用户id | 角色id |
|---|---|
| 1 | 2 |
| 1 | 5 |
| 1 | 9 |
Two
2NF在1NF的基础之上,消除了非主属性对于码的部分函数依赖。
函数依赖:
我们可以这么理解(但并不是特别严格的定义):若在一张表中,在属性(或属性组)X的值确定的情况下,必定能确定属性Y的值,那么就可以说Y函数依赖于X,写作 X → Y。
码:能够确定表中所有其他字段值的字段或者字段组合。
对于下表中的数据,找不到任何一条记录,它们的学号相同而对应的姓名不同。所以我们可以说姓名函数依赖于学号,写作 学号 → 姓名。但是,其中(学号,课程)->分数,就是说学号跟课程才能确定分数。
因此我们首先选取表中的码。就是通过表中所有属性的依赖关系(决定关系)来确定码。
学号->姓名
学号->系名
学号,课程->分数
因此,能够决定所有其他属性的字段或者字段组合是(学号,课程)字段组合,选取该组合为码。
那么,对于码(学号,课程)来说,学号,课程->姓名属于部分函数依赖,因为码(学号,课程)的部分属性学号就能确定姓名这个属性。
| 学号 | 姓名 | 系名 | 课程 | 分数 |
|---|---|---|---|---|
| 002001 | 王明 | 地理信息学院 | 大学数学 | 95 |
| 002001 | 王明 | 地理信息学院 | 大学英语 | 92 |
| 002003 | 张芳 | 地理信息学院 | 计算机基础 | 96 |
因此上表不能满足第二范式,如果不能满足范式,可以通过拆表来解决:
| 学号 | 姓名 | 系名 |
|---|---|---|
| 002001 | 王明 | 地理信息学院 |
学号->姓名
学号->系名
| 学号 | 课程 | 分数 |
|---|---|---|
| 002001 | 大学数学 | 95 |
| 002001 | 大学英语 | 92 |
学号,课程->分数
那么现在上表满足第二范式了,仍然不满足第三范式。试想下,如果该系更名,那么就需要修改学生表中的所有系名。请看:数据库三大范式-引出
用数据库的专业属于,学号-> 系名属于传递依赖,因为学号->系编号 ->系名。
由此引出第三范式:
Three
第三范式(3NF) 3NF在2NF的基础之上,消除了非主属性对于码的传递函数依赖。
那么下表中,学号->系名属于传递依赖,不满足第三范式。
| 学号 | 姓名 | 系名 |
|---|---|---|
| 002001 | 王明 | 地理信息学院 |
同样,如果某个表不满足第三范式,通过拆表来解决。将传递依赖进行拆除,放到新的表中。
如下:
| 学号 | 姓名 | 系编号 |
|---|---|---|
| 002001 | 王明 | 002 |
| 系编号 | 系名 |
|---|---|
| 002 | 地理信息学院 |
那么为什么,我们将系编号添置在学生表中作为一个属性,而不像下面两张表一样再写一个关系表呢?
| 学号 | 系编号 |
|---|---|
| 002001 | 002 |
| 学号 | 姓名 |
|---|---|
| 002001 | 王明 |
因为学生:学院 之间是1:M,就是说是1对多的关系。如果您对实体表之间的关系感兴趣,请看下一节。
由于,博客增加了一些内容,因此进行了延期。对此,明义经典感到很抱歉。亲,请见谅啊。















 705
705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









