










链接:https://www.zhihu.com/question/29411132/answer/51515231
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
刚好毕设相关,论文写完顺手就答了
先给出一个最快的了解+上手的教程:
直接看theano官网的LSTM教程+代码:LSTM Networks for Sentiment Analysis
但是,前提是你有RNN的基础,因为LSTM本身不是一个完整的模型,LSTM是对RNN隐含层的改进。一般所称的LSTM网络全叫全了应该是使用LSTM单元的RNN网络。教程就给了个LSTM的图,它只是RNN框架中的一部分,如果你不知道RNN估计看不懂。
比较好的是,你只需要了解前馈过程,你都不需要自己求导就能写代码使用了。
补充,今天刚发现一个中文的博客:LSTM简介以及数学推导(FULL BPTT)
不过,稍微深入下去还是得老老实实的好好学,下面是我认为比较好的
完整LSTM学习流程:
我一直都觉得了解一个模型的前世今生对模型理解有巨大的帮助。到LSTM这里(假设题主零基础)那比较好的路线是MLP->RNN->LSTM。还有LSTM本身的发展路线(97年最原始的LSTM到forget gate到peephole )
按照这个路线学起来会比较顺,所以我优先推荐的两个教程都是按照这个路线来的:
- 多伦多大学的 Alex Graves 的RNN专著《Supervised Sequence Labelling with Recurrent NeuralNetworks》
- Felix Gers的博士论文《Long short-term memory in recurrent neural networks》
这两个内容都挺多的,不过可以跳着看,反正我是没看完┑( ̄Д ̄)┍
还有一个最新的(今年2015)的综述,《ACritical Review of Recurrent Neural Networks for Sequence Learning》不过很多内容都来自以上两个材料。
其他可以当做教程的材料还有:
《FromRecurrent Neural Network to Long Short Term Memory Architecture Application toHandwriting Recognition Author》
《Generating Sequences With Recurrent Neural Networks》(这个有对应源码,虽然实例用法是错的,自己用的时候还得改代码,主要是摘出一些来用,供参考)
然后呢,可以开始编码了。除了前面提到的theano教程还有一些论文的开源代码,到github上搜就好了。
顺便安利一下theano,theano的自动求导和GPU透明对新手以及学术界研究者来说非常方便,LSTM拓扑结构对于求导来说很复杂,上来就写LSTM反向求导还要GPU编程代码非常费时间的,而且搞学术不是实现一个现有模型完了,得尝试创新,改模型,每改一次对应求导代码的修改都挺麻烦的。
其实到这应该算是一个阶段了,如果你想继续深入可以具体看看几篇经典论文,比如LSTM以及各个改进对应的经典论文。
还有楼上提到的《LSTM: A Search Space Odyssey》 通过从新进行各种实验来对比考查LSTM的各种改进(组件)的效果。挺有意义的,尤其是在指导如何使用LSTM方面。
不过,玩LSTM,最好有相应的硬件支持。我之前用Titan 780,现在实验室买了Titan X,应该可以说是很好的配置了(TitanX可以算顶配了)。但是我任务数据量不大跑一次实验都要好几个小时(前提是我独占一个显卡),(当然和我模型复杂有关系,LSTM只是其中一个模块)。
===========================================
如果想玩的深入一点可以看看LSTM最近的发展和应用。老的就不说了,就提一些比较新比较好玩的。
LSTM网络本质还是RNN网络,基于LSTM的RNN架构上的变化有最先的BRNN(双向),还有今年Socher他们提出的树状LSTM用于情感分析和句子相关度计算《Improved Semantic Representations From Tree-Structured LongShort-Term Memory Networks》(类似的还有一篇,不过看这个就够了)。他们的代码用Torch7实现,我为了整合到我系统里面自己实现了一个,但是发现效果并不好。我觉的这个跟用于建树的先验信息有关,看是不是和你任务相关。还有就是感觉树状LSTM对比BLSTM是有信息损失的,因为只能使用到子节点信息。要是感兴趣的话,这有一篇树状和线性RNN对比《(treeRNN vs seqRNN )When Are Tree Structures Necessary for DeepLearning of Representations?》。当然,关键在于树状这个概念重要,感觉现在的研究还没完全利用上树状的潜力。
今年ACL(2015)上有一篇层次的LSTM《AHierarchical Neural Autoencoder for Paragraphs and Documents》。使用不同的LSTM分别处理词、句子和段落级别输入,并使用自动编码器(autoencoder)来检测LSTM的文档特征抽取和重建能力。
还有一篇文章《Chung J, Gulcehre C, Cho K, et al. Gated feedback recurrent neural networks[J]. arXiv preprint arXiv:1502.02367, 2015.》,把gated的思想从记忆单元扩展到了网络架构上,提出多层RNN各个层的隐含层数据可以相互利用(之前的多层RNN多隐含层只是单向自底向上连接),不过需要设置门(gated)来调节。
记忆单元方面,BahdanauDzmitry他们在构建RNN框架的机器翻译模型的时候使用了GRU单元(gated recurrent unit)替代LSTM,其实LSTM和GRU都可以说是gated hidden unit。两者效果相近,但是GRU相对LSTM来说参数更少,所以更加不容易过拟合。(大家堆模型堆到dropout也不管用的时候可以试试换上GRU这种参数少的模块)。这有篇比较的论文《(GRU/LSTM对比)Empirical Evaluation of Gated Recurrent Neural Networks on SequenceModeling》
应用嘛,宽泛点来说就是挖掘序列数据信息,大家可以对照自己的任务有没有这个点。比如(直接把毕设研究现状搬上来(。・∀・)ノ゙):
先看比较好玩的,
图像处理(对,不用CNN用RNN):
《Visin F, Kastner K,Cho K, et al. ReNet: A Recurrent Neural Network Based Alternative toConvolutional Networks[J]. arXiv preprint arXiv:1505.00393, 2015》
4向RNN(使用LSTM单元)替代CNN。
使用LSTM读懂python程序:
《Zaremba W, Sutskever I.Learning to execute[J]. arXiv preprint arXiv:1410.4615, 2014.》
使用基于LSTM的深度模型用于读懂python程序并且给出正确的程序输出。文章的输入是短小简单python程序,这些程序的输出大都是简单的数字,例如0-9之内加减法程序。模型一个字符一个字符的输入python程序,经过多层LSTM后输出数字结果,准确率达到99%
手写识别:
《Liwicki M, Graves A,Bunke H, et al. A novel approach to on-line handwriting recognition based onbidirectional long short-term memory》
机器翻译:
《Sutskever I, VinyalsO, Le Q V V. Sequence to sequence learning with neural networks[C]//Advances inneural information processing systems. 2014: 3104-3112.》
使用多层LSTM构建了一个seq2seq框架(输入一个序列根据任务不同产生另外一个序列),用于机器翻译。先用一个多层LSTM从不定长的源语言输入中学到特征v。然后使用特征v和语言模型(另一个多层LSTM)生成目标语言句子。
《Cho K, Van Merriënboer B, Gulcehre C, et al. Learning phrase representations using rnn encoder-decoder for statistical machine translation[J]. arXiv preprint arXiv:1406.1078, 2014.》
这篇文章第一次提出GRU和RNN encoder-decoder框架。使用RNN构建编码器-解码器(encoder-decoder)框架用于机器翻译。文章先用encoder从不定长的源语言输入中学到固定长度的特征V,然后decoder使用特征V和语言模型解码出目标语言句子
以上两篇文章提出的seq2seq和encoder-decoder这两个框架除了在机器翻译领域,在其他任务上也被广泛使用。
《Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.》
在上一篇的基础上引入了BRNN用于抽取特征和注意力信号机制(attention signal)用于源语言和目标语言的对齐。
对话生成:
《Shang L, Lu Z, Li H. Neural Responding Machine for Short-Text Conversation[J]. arXiv preprint arXiv:1503.02364, 2015.》
华为诺亚方舟实验室,李航老师他们的作品。基本思想是把对话看成是翻译过程。然后借鉴Bahdanau D他们的机器翻译方法(encoder-decoder,GRU,attention signal)解决。训练使用微博评论数据。
《VINYALS O, LE Q,.A Neural Conversational Model[J]. arXiv:1506.05869 [cs], 2015.》
google前两天出的论文(2015-6-19)。看报道说结果让人觉得“creepy”:Google's New Chatbot Taught Itself to Be Creepy 。还以为有什么NB模型,结果看了论文发现就是一套用seq2seq框架的实验报告。(对话可不是就是你一句我一句,一个序列对应产生另一序列么)。论文里倒是说的挺谨慎的,只是说纯数据驱动(没有任何规则)的模型能做到这样不错了,但还是有很多问题,需要大量修改(加规则呗?)。主要问题是缺乏上下文一致性。(模型只用对话的最后一句来产生下一句也挺奇怪的,为什么不用整个对话的历史信息?)
句法分析:
《Vinyals O, Kaiser L,Koo T, et al. Grammar as a foreign language[J]. arXiv preprint arXiv:1412.7449,2014.》
把LSTM用于句法分析任务,文章把树状的句法结构进行了线性表示,从而把句法分析问题转成翻译问题,然后套用机器翻译的seq2seq框架使用LSTM解决。
信息检索:
《Palangi H, Deng L,Shen Y, et al. Deep Sentence Embedding Using the Long Short Term Memory Network:Analysis and Application to Information Retrieval[J]. arXiv preprintarXiv:1502.06922, 2015.》
使用LSTM获得大段文本或者整个文章的特征向量,用点击反馈来进行弱监督,最大化query的特性向量与被点击文档的特性向量相似度的同时最小化与其他未被点击的文档特性相似度。
图文转换:
图文转换任务看做是特殊的图像到文本的翻译问题,还是使用encoder-decoder翻译框架。不同的是输入部分使用卷积神经网络(Convolutional Neural Networks,CNN)抽取图像的特征,输出部分使用LSTM生成文本。对应论文有:
《Karpathy A, Fei-Fei L. Deepvisual-semantic alignments for generating image descriptions[J]. arXiv preprintarXiv:1412.2306, 2014.》
《Mao J, Xu W, Yang Y, et al. Deepcaptioning with multimodal recurrent neural networks (m-rnn)[J]. arXiv preprintarXiv:1412.6632, 2014.》
《Vinyals O, Toshev A, Bengio S, et al. Show andtell: A neural image caption generator[J]. arXiv preprint arXiv:1411.4555,2014.》
就粘这么多吧,呼呼~复制粘贴好爽\(^o^)/~
其实,相关工作还有很多,各大会议以及arxiv上不断有新文章冒出来,实在是读不过来了。。。
然而我有种预感,说了这么多,工作之后很有可能发现:
这些东西对我工作并没有什么卵用(>﹏<=
我是这样初步了解RNN和LSTM的,希望能有帮助:
1. 看牛津大学的Nando de Freitas教授的deep learning课程中关于RNN和LSTM的视频和讲义。Machine Learning
我觉得他的课程优点有这些:
1.1 配合着 Torch7(https://torch.ch),一边讲RNN和LSTM的内部结构,一边动手写代码。写完就了解RNN与LSTM的工作原理了。并且我自己觉得Torch7的Lua代码要比Theano的代码容易理解。
1.2 他的课程中关于BPTT( back-propagation through time )的讲解很清楚。我按照他的推荐计算了一个two time steps的rnn的bp,然后对BPTT算法的了解比原来要好一些。这是他课程的slides,里面有关于BPTT的推倒。https://www.cs.ox.ac.uk/people/nando.defreitas/machinelearning/lecture11.pdf
1.3 他的课程配合有一个github上的项目:oxford-cs-ml-2015/practical6 · GitHub 参考着他提供的对LSTM的实现的源代码能够加速理解。并且看懂了以后还能做一些自己的小扩展。
2. Stanford大学Feifei Li博士生Andrej Karpathy基于前面提到的nando教授的LSTM实现做了一个有趣的项目:char-rnn (karpathy/char-rnn · GitHub)。他在Nando版本基础上又加了对multi-layer,gpu的支持,还有一些其他deep learning里的小trick。推荐这个项目的原因是如果你看懂了nando的版本,那么Karpathy的版本也很容易看懂。并且马上就可以提供自己的数据做运用。比如:我把python的tornado,flask,django框架的代码合成了一个30万行的文件喂给这个LSTM。然后它就能写出貌似正确的python代码了。他还写过一篇博客讲解RNN和LSTM:The Unreasonable Effectiveness of Recurrent Neural Networks
4. CVPR15有一个关于Torch7和deep learning的tutorial,从这个tutorial里面能够快速入门torch7:Torch | Applied Deep Learning for Computer Vision with Torch
5. 如果以上都完成了,还想找一些机会读paper,自己实现,看别人的实现,那么在这个论坛上经常会有人提供一些新的paper的实现,比如:DeepMind的atari,DeepMind的DRAW,Google的BatchNorm等;torch/torch7
6. Torch7的邮件列表:Google 网上论坛
7. 最后,Alex Grave有一份文档很详细地讲解他自己生成sequence的方法。 http://arxiv.org/abs/1308.08501. 传说中的cs231n lecture 10,虽然youtube下架了,然而度盘上很多,实在找不到的请私信我。
2. karpathy的mini-char-rnn: https://gist.github.com/karpathy/d4dee566867f8291f086 (要翻墙),这个是python实现的rnn,包括bp的过程都有。
3. 如何用torch实现一层的lstm:LSTM implementation explained 超级详细,每一步运算都有代码和图解。
4. karpathy的char-rnn:GitHub - karpathy/char-rnn: Multi-layer Recurrent Neural Networks (LSTM, GRU, RNN) for character-level language models in Torch 就是上面那个一层lstm扩展成n层,跑起来还可以生成文本,很好玩。
首先,对于没有RNN基础的同学,强烈建议先看一下下面这篇论文
A Critical Review of Recurrent Neural Networks for Sequence Learning
里面的数学符号定义清楚,非常适合没有任何基础的童鞋对RNN和LSTM建立一个基本的认识。
然后,看完这篇论文以后,可以接着看下面这篇博客
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
里面对LSTM结构为什么这样设计,做了一步步的推理解释,非常的详细。
看完上面两个tutorial, 你对LSTM的结构已经基本了解了。如果希望对于如何训练LSTM, 了解BPTT算法的工作细节,可以看Alex Graves的论文
Supervised Sequence Labelling with Recurrent Neural Networks
这篇论文里有比较详细的公式推导,但是对于LSTM的结构却讲的比较混乱,所以不建议入门就看这篇论文。
看完了上面篇论文/教程以后,对于LSTM的理论知识就基本掌握了,下面就需要在实践中进一步加深理解,我还没有去实践,后面的答案等实践完以后回来再补上。
不过根据有经验的学长介绍,使用Theano自己实现一遍LSTM是一个不错的选择
我自己实现了一个,总结了一下。发现想学会lstm只要看看这张图就行了,你会发现除了矩阵多了些,没啥新东西。另外theano、torch都有现成的,可以直接拿来用。至于bptt,想自己写,就自己求一遍导,或者如果你对于nn bp很熟练,直接按照图中的箭头逆序bptt就可以了。至于调参,可以借鉴已有的大量工作,省心了不少。
代码:
java:lipiji/JRNN · GitHub
theano:lipiji/rnn-theano · GitHub
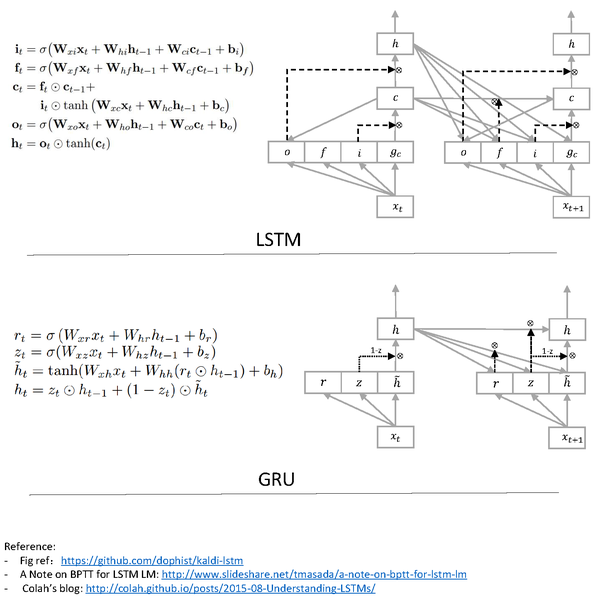
图中的链接:
A Note on BPTT for LSTM LM
http://www.slideshare.net/tmasada/a-note-on-bptt-for-lstm-lm (我基本上就是照着这个以及上图实现的bptt)
Fig ref:dophist/kaldi-lstm · GitHub
当然,Colah的blog那是写的很赞的:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Schmidhuber的一个LSTM教程 :Long Short-Term Memory: Tutorial on LSTM Recurrent Networks
Schmidhuber等人还写了这篇关于LSTM的文章 LSTM: A Search Space Odyssey: http://arxiv.org/pdf/1503.04069v1.pdf,也不错
至于动手写代码,题主可以再参考Deep Learning Tutorials里RNN和LSTM的部分了
写了一个tutorial,一步一步实现RNN,采用计算图和自动求导,无需手推BPTT,代码也非常灵活,定义了RNNLayer,只要修改RNNLayer就能变成LSTM或GRU等,激活函数(tanh或ReLu)和输出层(softmax)也可以指定。例子使用了rnnlm,训练RNN语言模型。感兴趣的请移步:
GitHub - pangolulu/rnn-from-scratch: Implementing Recurrent Neural Network from Scratch
2017年3月19日更新
知乎阅读地址:
gitbook阅读地址:
梯度消失和梯度爆炸
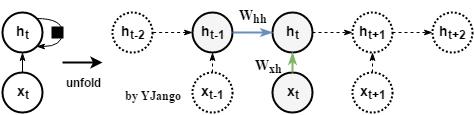
网络回忆:在《循环神经网络——介绍》中提到循环神经网络用相同的方式处理每个时刻的数据。
- 动态图:
- 数学公式:
设计目的:我们希望循环神经网络可以将过去时刻发生的状态信息传递给当前时刻的计算中。
实际问题:但普通的RNN结构却难以传递相隔较远的信息。
- 考虑:若只看上图蓝色箭头线的、隐藏状态的传递过程,不考虑非线性部分,那么就会得到一个简化的式子(1):
- (1)
如果将起始时刻的隐藏状态信息向第时刻传递,会得到式子(2)
- (2)
会被乘以多次,若允许矩阵进行特征分解
- (3)
- (4)
当特征值小于1时,不断相乘的结果是特征值的次方向 衰减; 当特征值大于1时,不断相乘的结果是特征值的t次方向 扩增。 这时想要传递的中的信息会被掩盖掉,无法传递到。
- (1)
- 类比:设想y,如果等于0.1,在被不断乘以0.1一百次后会变成多小?如果等于5,在被不断乘以5一百次后会变得多大?若想要所包含的信息既不消失,又不爆炸,就需要尽可能的将的值保持在1。
- 注:更多内容请参阅Deep Learning by Ian Goodfellow中第十章。
Long Short Term Memory (LSTM)
上面的现象可能并不意味着无法学习,但是即便可以,也会非常非常的慢。为了有效的利用梯度下降法学习,我们希望使不断相乘的梯度的积(the product of derivatives)保持在接近1的数值。
一种实现方式是建立线性自连接单元(linear self-connections)和在自连接部分数值接近1的权重,叫做leaky units。但Leaky units的线性自连接权重是手动设置或设为参数,而目前最有效的方式gated RNNs是通过gates的调控,允许线性自连接的权重在每一步都可以自我变化调节。LSTM就是gated RNNs中的一个实现。
LSTM的初步理解
LSTM(或者其他gated RNNs)是在标准RNN ()的基础上装备了若干个控制数级(magnitude)的gates。可以理解成神经网络(RNN整体)中加入其他神经网络(gates),而这些gates只是控制数级,控制信息的流动量。
数学公式:这里贴出基本LSTM的数学公式,看一眼就好,仅仅是为了让大家先留一个印象,不需要记住,不需要理解。
<img src="https://pic1.zhimg.com/v2-a6b43d50d70f9b94954a969ec3eaa3b4_b.png" data-rawwidth="385" data-rawheight="121" class="content_image" width="385">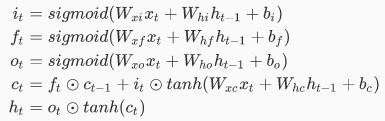
尽管式子不算复杂,却包含很多知识,接下来就是逐步分析这些式子以及背后的道理。 比如 的意义和使用原因,sigmoid的使用原因。
余下请阅读知乎阅读地址:循环神经网络--实现LSTM
声明:本译文与另一译者(刘翔宇)的版本(理解长短期记忆网络(LSTM NetWorks)-CSDN.NET)互为独立,特此向另一位译者道歉。
译自博客
Understanding LSTM Networks
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
中文版见
理解LSTM网络
理解不到位之处欢迎指正,译文如下:
# 理解LSTM网络
## 周期神经网络(Recurrent Neural Networks)
人类并非每一秒都在从头开始思考问题。当你阅读这篇文章时,你是基于之前的单词来理解每个单词。你并不会把所有内容都抛弃掉,然后从头开始理解。你的思考具有持久性。
传统的神经网络并不能做到这一点,这似乎是其一个主要的缺点。例如,想象你要把一部电影里面每个时间点所正在发生的事情进行分类。并不知道传统神经网络怎样才能把关于之前事件的推理运用到之后的事件中去。
周期神经网络解决了这个问题。它们是一种具有循环的网络,具有保持信息的能力。<img src="https://pic4.zhimg.com/168147be9809bf869e68cfaa2ecdcf2b_b.png" data-rawwidth="257" data-rawheight="400" class="content_image" width="257">
**如上图**所示,神经网络的模块*A*输入为,输出为
。模块*A*的循环结构使得信息从网络的上一步传到了下一步。
这个循环使周期神经网络看起来有点神秘。然而,如果你仔细想想就会发现它与普通的神经网络并没有太大不同。周期神经网络可以被认为是相同网络的多重复制结构,每一个网络把消息传给其继承者。如果我们把循环体展开就是这样,**如图所示**:<img src="https://pic4.zhimg.com/09abf0f0cb2f87b0abcad56997f2f3fb_b.png" data-rawwidth="600" data-rawheight="157" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic4.zhimg.com/09abf0f0cb2f87b0abcad56997f2f3fb_r.png">
这种链式属性表明,周期神经网络与序列之间有着紧密的联系。这也是运用这类数据最自然的结构。
当然它们已经得到了应用!过去几年中,RNNs已经被成功应用于各式各样的问题中:语音识别,语言建模,翻译,图像标注…等等。RNNs取得的各种瞩目成果可以参看Andrej Karpathy的博客:[The Unreasonable Effectiveness of Recurrent Neural Networks]( The Unreasonable Effectiveness of Recurrent Neural Networks)。确实效果让人非常吃惊。
取得这项成功的一个要素是『LSTMs』,这是一种非常特殊的周期神经网络,对于许多任务,比标准的版本要有效得多。几乎所有基于周期神经网络的好成果都使用了它们。本文将着重介绍LSTMs。
## 长期依赖问题(The Problem of Long-Term Dependencies)
RNNs的一个想法是,它们可能会能够将之前的信息连接到现在的任务之中。例如用视频前一帧的信息可以用于理解当前帧的信息。如果RNNs能够做到这些,那么将会非常使用。但是它们可以吗?这要看情况。
有时候,我们处理当前任务仅需要查看当前信息。例如,设想又一个语言模型基于当前单词尝试着去预测下一个单词。如果我们尝试着预测『the clouds are i n the *sky*』的最后一个单词,我们并不需要任何额外的信息了-很显然下一个单词就是『天空』。这样的话,如果目标预测的点与其相关信息的点之间的间隔较小,RNNs可以学习利用过去的信息。
但是也有时候我们需要更多的上下文信息。设想预测这句话的最后一个单词:『I grew up in France… I speak fluent *French*』。最近的信息表明下一个单词似乎是一种语言的名字,但是如果我们希望缩小确定语言类型的范围,我们需要更早之前作为France 的上下文。而且需要预测的点与其相关点之间的间隔非常有可能变得很大,**如图所示**:
<img src="https://pic1.zhimg.com/9e7cbd268eb0ae6c656495d44342a900_b.png" data-rawwidth="600" data-rawheight="276" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic1.zhimg.com/9e7cbd268eb0ae6c656495d44342a900_r.png">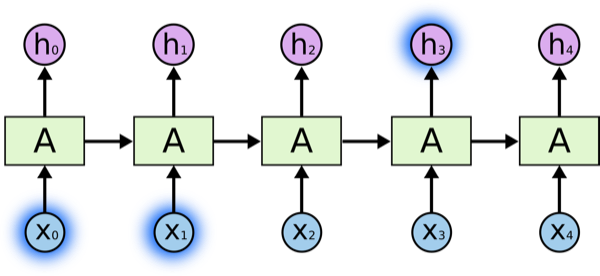
不幸的是,随着间隔增长,RNNs变得难以学习连接之间的关系了,**如图所示**:<img src="https://pic2.zhimg.com/38dc6bd14463aeee586ada6a3422070d_b.png" data-rawwidth="600" data-rawheight="206" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic2.zhimg.com/38dc6bd14463aeee586ada6a3422070d_r.png">
理论上来说,RNNs绝对能够处理这种『长期依赖』。人们可以小心选取参数来解决这种类型的小模型。悲剧的是,事实上,RNNs似乎并不能学习出来这些参数。这个问题已经在[Hochreiter (1991) [German]]( http://people.idsia.ch/~juergen/SeppHochreiter1991ThesisAdvisorSchmidhuber.pdf)与[Bengio, et al. (1994)]( http://www-dsi.ing.unifi.it/~paolo/ps/tnn-94-gradient.pdf)中被深入讨论,他们发现了为何RNNs不起作用的一些基本原因。
幸运的是,LSTMs可以解决这个问题!
## LSTM网络
长短时间记忆网络(Long Short Term Memory networks)——通常成为『LSTMs』——是一种特殊的RNN,它能够学习长时间依赖。它们由[Hochreiter & Schmidhuber (1997)]( http://deeplearning.cs.cmu.edu/pdfs/Hochreiter97_lstm.pdf)提出,后来由很多人加以改进和推广。他们在大量的问题上都取得了巨大成功,现在已经被广泛应用。
LSTMs是专门设计用来避免长期依赖问题的。记忆长期信息是LSTMs的默认行为,而不是它们努力学习的东西!
所有的周期神经网络都具有链式的重复模块神经网络。在标准的RNNs中,这种重复模块具有非常简单的结构,比如是一个tanh层,**如图所示**:
<img src="https://pic2.zhimg.com/5cd89ccc8fd59369cf81f8872a5e6b91_b.png" data-rawwidth="600" data-rawheight="224" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic2.zhimg.com/5cd89ccc8fd59369cf81f8872a5e6b91_r.png">
LSTMs同样具有链式结构,但是其重复模块却有着不同的结构。不同于单独的神经网络层,它具有4个以特殊方式相互影响的神经网络层,**如图所示**:
<img src="https://pic2.zhimg.com/fcddcec98b493dfcdb963d1d407bca85_b.png" data-rawwidth="600" data-rawheight="225" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic2.zhimg.com/fcddcec98b493dfcdb963d1d407bca85_r.png">
不要担心接下来涉及到的细节。我们将会一步步讲解LSTM的示意图。下面是我们将要用到的符号,**如图所示**:
<img src="https://pic4.zhimg.com/a3bf999e0fb2a13e3eb09aba0f2df887_b.png" data-rawwidth="600" data-rawheight="111" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic4.zhimg.com/a3bf999e0fb2a13e3eb09aba0f2df887_r.png">
在上图中,每一条线代表一个完整的向量,从一个节点的输出到另一个节点的输入。粉红色圆形代表了逐点操作,例如向量求和;黄色方框代表学习出得神经网络层。聚拢的线代表了串联,而分叉的线代表了内容复制去了不同的地方。
## LSTMs背后的核心思想
LSTMs的关键在于细胞状态,在图中以水平线表示。
细胞状态就像一个传送带。它顺着整个链条从头到尾运行,中间只有少许线性的交互。信息很容易顺着它流动而保持不变。**如图所示**:
<img src="https://pic1.zhimg.com/b557bc657982aaba8a03298c6da7e75c_b.png" data-rawwidth="600" data-rawheight="185" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic1.zhimg.com/b557bc657982aaba8a03298c6da7e75c_r.png">
LSTM通过称之为门(gates)的结构来对细胞状态增加或者删除信息。
门是选择性让信息通过的方式。它们的输出有一个sigmoid层和逐点乘积操作,**如图所示**:
<img src="https://pic4.zhimg.com/fff6530f1b195377eee0ffb5006c129f_b.png" data-rawwidth="245" data-rawheight="300" class="content_image" width="245">
Sigmoid 层的输出在0到1之间,定义了各成分被放行通过的程度。0值意味着『不让任何东西过去』;1值意味着『让所有东西通过』。
一个LSTM具有3种门,用以保护和控制细胞状态。
## 逐步讲解LSTM
LSTM的第一步是决定我们要从细胞中抛弃何种信息。这个决定是由叫做『遗忘门』的sigmoid层决定的。它以和
为输入,在
细胞输出一个介于0和1之间的数。其中1代表『完全保留』,0代表『完全遗忘』。
让我们回到之前那个语言预测模型的例子,这个模型尝试着根据之前的单词学习预测下一个单词。在这个问题中,细胞状态可能包括了现在主语的性别,因此能够使用正确的代词。当我们见到一个新的主语时,我们希望它能够忘记之前主语的性别。**如图所示**:
<img src="https://pic1.zhimg.com/a880588ec0a9d2015e12e8690458a4ec_b.png" data-rawwidth="600" data-rawheight="185" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic1.zhimg.com/a880588ec0a9d2015e12e8690458a4ec_r.png">
下一步是决定细胞中要存储何种信息。它有2个组成部分。首先,由一个叫做『输入门层』的sigmoid层决定我们将要更新哪些值。其次,一个tanh层创建一个新的候选向量,它可以加在状态之中。在下一步我们将结合两者来生成状态的更新。
在语言模型的例子中,我们希望把新主语的性别加入到状态之中,从而取代我们打算遗忘的旧主语的性别,**如图所示**:
<img src="https://pic3.zhimg.com/7241c9f22e310984417c8caf7a5d350e_b.png" data-rawwidth="600" data-rawheight="185" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic3.zhimg.com/7241c9f22e310984417c8caf7a5d350e_r.png">
现在我们可以将旧细胞状态了。之前的步骤已经决定了该怎么做,我们现在实际操作一下。
我们把旧状态乘以,用以遗忘之前我们决定忘记的信息。然后我们加上
。这是新的候选值,根据我们决定更新状态的程度来作为放缩系数。
在语言模型中,这里就是我们真正丢弃关于旧主语性别信息以及增添新信息的地方,**如图所示**:
<img src="https://pic2.zhimg.com/84fe628b2fc3a27c2ff8916a1c286c0d_b.png" data-rawwidth="600" data-rawheight="185" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic2.zhimg.com/84fe628b2fc3a27c2ff8916a1c286c0d_r.png">
最终,我们可以决定输出哪些内容。输出取决于我们的细胞状态,但是以一个过滤后的版本。首先,我们使用sigmoid层来决定我们要输出细胞状态的哪些部分。然后,把用tanh处理细胞状态(将状态值映射到-1至1之间)。最后将其与sigmoid门的输出值相乘,从而我们能够输出我们决定输出的值。**如图所示**:
<img src="https://pic3.zhimg.com/013e917a8b1080120b0e682b80ce723a_b.png" data-rawwidth="600" data-rawheight="185" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic3.zhimg.com/013e917a8b1080120b0e682b80ce723a_r.png">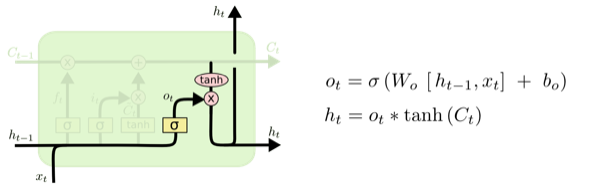
对于语言模型,在预测下一个单词的例子中,当它输入一个主语,它可能会希望输出相关的动词。例如,当主语是单数或复数时,它可能会以相应形式的输出。
## 各种LSTM的变化形式
目前我所描述的都是普通的LSTM。然而并非所有的LSTM都是一样的。事实上,似乎每一篇使用LSTMs的文章都有些细微差别。这些差别很小,但是有些值得一提。
其中一个流行的LSTM变化形式是由[Gers & Schmidhuber (2000)](ftp://ftp.idsia.ch/pub/juergen/TimeCount-IJCNN2000.pdf)提出,增加了『窥视孔连接(peephole connections)』。**如图所示**:
<img src="https://pic1.zhimg.com/0ca542fe79c8f0d1455e960138ae1f38_b.png" data-rawwidth="600" data-rawheight="185" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic1.zhimg.com/0ca542fe79c8f0d1455e960138ae1f38_r.png">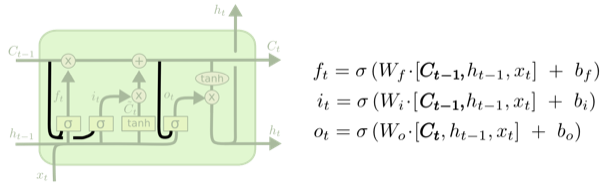
在上图中,所有的门都加上了窥视孔,但是许多论文中只在其中一些装了窥视孔。
另一个变种是使用了配对遗忘与输入门。与之前分别决定遗忘与添加信息不同,我们同时决定两者。只有当我们需要输入一些内容的时候我们才需要忘记。只有当早前信息被忘记之后我们才会输入。**如图所示**:
<img src="https://pic1.zhimg.com/b5c49957506b53fd6d21e363a95451e4_b.png" data-rawwidth="600" data-rawheight="185" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic1.zhimg.com/b5c49957506b53fd6d21e363a95451e4_r.png">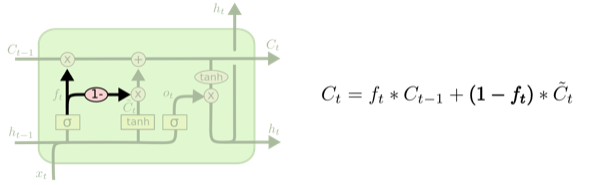
LSTM一个更加不错变种是 Gated Recurrent Unit(GRU),是由[Cho, et al. (2014)]( http://arxiv.org/pdf/1406.1078v3.pdf)提出的。这个模型将输入门与和遗忘门结合成了一个单独的『更新门』。而且同时还合并了细胞状态和隐含状态,同时也做了一下其他的修改。因此这个模型比标准LSTM模型要简单,并且越来越收到欢迎。**如图所示**:
<img src="https://pic1.zhimg.com/2df0ee4e56c67d5522ca6e17e5e9c3fc_b.png" data-rawwidth="600" data-rawheight="185" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic1.zhimg.com/2df0ee4e56c67d5522ca6e17e5e9c3fc_r.png">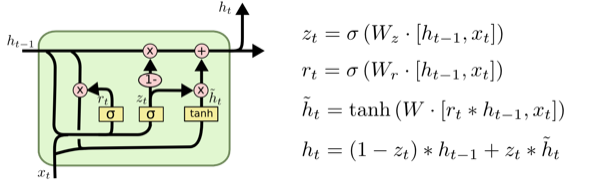
这些仅仅只是LSTM的少数几个著名变种。还有很多其他的种类,例如由[Yao, et al. (2015)]( http://arxiv.org/pdf/1508.03790v2.pdf) 提出的Depth Gated RNNs 。以及处理长期依赖问题的完全不同的手段,如[Koutnik, et al. (2014)]( http://arxiv.org/pdf/1402.3511v1.pdf)提出的Clockwork RNNs。
那种变种是最好的?这些不同重要吗?[Greff, et al. (2015)]( http://arxiv.org/pdf/1503.04069.pdf) 将各种著名的变种做了比较,发现其实基本上是差不多的。[Jozefowicz, et al. (2015)]( http://jmlr.org/proceedings/papers/v37/jozefowicz15.pdf) 测试了超过一万种RNN结构,发现了一些在某些任务上表现良好的模型。
## 结论
最开始我提到的杰出成就都是使用RNNs做出的。本质上所有这些成果都是使用了LSTMs。在大多数任务中,它们的表现确实非常优秀!
以公式的形式写下来,LSTMs看起来非常令人胆怯。然而通过本文的逐步讲解使得LSTM变得平易近人了。
LSTMs 是我们使用RNNs的重要一步。我们很自然地想到:还有下一步吗?研究者的普遍观点是:『有!下一大步就是「注意力」(Attention)。』其基本思想就是让RNN的每一步从更大范围的信息中选取。例如,假设你为图片打标签,它可能会为它输出的每一个词语选取图片的一部分作为输入。事实上,[Xu, et al. (2015)]( http://arxiv.org/pdf/1502.03044v2.pdf)就是这么做的——如果你想探索『注意力』的话,这是个有趣的引子!已经有大量使用『注意力』得到的良好成果,而且似乎更多的陈果也将要出现......
『注意力』并非是RNN研究中唯一一个激动人心的方向。例如,[Kalchbrenner, et al. (2015)]( http://arxiv.org/pdf/1507.01526v1.pdf)做出的Grid LSTMs 似乎很有前途。在生成模型中使用RNNs-例如[Gregor, et al. (2015)]( http://arxiv.org/pdf/1502.04623.pdf),[Chung, et al. (2015)]( http://arxiv.org/pdf/1506.02216v3.pdf)以及[Bayer & Osendorfer (2015) ]( http://arxiv.org/pdf/1411.7610v3.pdf)-似乎也很有趣。过去几年是RNN激动人心的阶段,未来几年将会更加如此!
补充一点:我也是基于前几个答案,然后自己看文章总结的经验,随便谢谢排名靠前的几个答案给我提供的文章
更新:今年(2017)的CS224d已经改名为CS224n,新增了大量内容,包括Dependancy Parsing、NMT、QA、FAIR的NLP专用CNN等等,每节课都有spotlight,课程作业也有更新。
课程主页:CS224n: Natural Language Processing with Deep Learning
全部讲课视频:https://www.youtube.com/playlist?list=PLU40WL8Ol94IJzQtileLTqGZuXtGlLMP_
课程材料打包下载(不含视频,有全部assignments、suggested readings、slides、lecture notes):http://pan.baidu.com/s/1dEWb5Rz
------------------------------------------------------原答案-------------------------------------------------------
读过很多RNN、LSTM的教程,包括colah和Andrej的博客、Alex的原文、Theano的deep learning tutorial、Bengio的那本书和各种review等等,个人感觉讲得最好最浅显易懂的还是这个:http://cs224d.stanford.edu/lecture_notes/notes4.pdf
个人认为这张图是画得最直观且道出本质的,把LSTM的设计动机、各个结构的原理、具体的计算过程都准确概括:
<img src="https://pic1.zhimg.com/5453dfb9ecc9c1fb9bab8fec05446d1c_b.png" data-rawwidth="1730" data-rawheight="1304" class="origin_image zh-lightbox-thumb" width="1730" data-original="https://pic1.zhimg.com/5453dfb9ecc9c1fb9bab8fec05446d1c_r.png">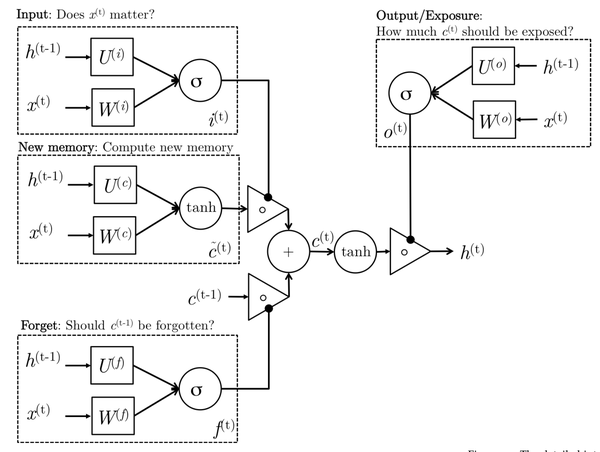
图来自斯坦福CS224d 2016 Lecture Notes 4
1. 计算input gate:决定输入中有多少要吸收进memory2. 计算forget gate:决定
的memory要忘掉多少3. 准备
的memory:根据
和
等待下一步运算4. 用input和forget gate控制
组合运算出
(输出)6. 用output gate控制放出
整个cell其实就是根据输入
和
事实上这份讲义没有像大多数RNN教程那样按照历史顺序来阐述LSTM及其变种,而是在介绍了基本的RNN后,先引入了GRU,再讲到LSTM,这样更易于初学者理解(详情见讲义原文)。
至于完整的数学推导,就看楼上的各种推荐了,例如baidu.com 的页面。
当然我个人强烈推荐整个CS224d课程Stanford University CS224d: Deep Learning for Natural Language Processing,从RNN的起源及发展过程都有详细介绍,我个人认为从头开始打基础,理解各种模型的设计动机和发展史比一上来就看文档写代码更重要。斯坦福课程设计的完善程度时常令我惊叹,公开传播其优质教育资源的做法更令我敬佩。之前 @杜客 的专栏 智能单元 - 知乎专栏 已经翻译了完整的CS231n,希望再接再厉把CS224d也翻译出来供各位享用,大家也可以加入翻译团队一起做贡献~
分为几个部分。
1. 理解RNN里面的数学。我是读这个教程入门的。 Recurrent Neural Network Tutorial, Part 4 前提是有UFLDL的基础或者至少是习惯了用矩阵方法来求导。否则Part 2和Part 3的代码你不知道是怎么推出来的。
2. 上面那个tutorial里面的东西太naive了,很多trick都没有。另外我也想看看真正的代码是怎么实现的。所以就简单的读了一下 GitHub - lisa-groundhog/GroundHog: Library for implementing RNNs with Theano
当时我还好奇一个问题,为什么RNN原理非常简单,用keras跑RNN也很简单,为什么GroundHog的代码却那么大。我总担心keras漏了什么。所以做了下面这个统计表格。最后发现,确实,如果考虑Library部分可以用keras等库替代,groundhog真正核心的模型构建部分也就1000多行。完全可以接受。
<img src="https://pic4.zhimg.com/0f17f8b2ed80ea77ab8037352ad099cf_b.png" data-rawwidth="1183" data-rawheight="943" class="origin_image zh-lightbox-thumb" width="1183" data-original="https://pic4.zhimg.com/0f17f8b2ed80ea77ab8037352ad099cf_r.png">
3. 最后我就放心大胆的用RNN了。为了确保我做的是对的,我用用keras repro了 GitHub - stanfordnlp/treelstm: Tree-structured Long Short-Term Memory networks (http://arxiv.org/abs/1503.00075) 一开始keras跑出来的结果总比github上的结果差,哪怕模型的结构都一样。后来发现就是因为我偷懒,没有用Glove embedding初始化结构。
文章链接如下:循环神经网络-Recurrent Neural Networks
循环神经网络(Recurrent Neural Networks)是目前非常流行的神经网络模型,在自然语言处理的很多任务中已经展示出卓越的效果。但是在介绍 RNN 的诸多文章中,通常都是介绍 RNN 的使用方法和实战效果,很少有文章会介绍关于该神经网络的训练过程。
循环神经网络是一个在时间上传递的神经网络,网络的深度就是时间的长度。该神经网络是专门用来处理时间序列问题的,能够提取时间序列的信息。如果是前向神经网络,每一层的神经元信号只能够向下一层传播,样本的处理在时刻上是独立的。对于循环神经网络而言,神经元在这个时刻的输出可以直接影响下一个时间点的输入,因此该神经网络能够处理时间序列方面的问题。
本文将会从数学的角度展开关于循环神经网络的使用方法和训练过程,在本文中,会假定读者已经掌握数学分析中的导数,偏导数,链式法则,梯度下降法等基础内容。本文将会使用传统的后向传播算法(Back Propagation)来训练 RNN 模型。
如果需要大致了解网络架构的内在原理,可以去看 Recurrent Neural Networks Tutorial, Part 1 ,帮助入门级读者回避了很多数学推导!并且有易懂的Python例子!
如果真的要弄清楚那些个公式都是怎么干活的啊...不妨戳开这个 The Unreasonable Effectiveness of Recurrent Neural Networks 和这个 Recurrent Neural Network Tutorial, Part 4 中推荐的paper!个人感觉都比较有代表性!
如果想顺手学下CNN,那就看这个吧 Stanford University CS231n: Convolutional Neural Networks for Visual Recognition ! 好有名的说!
RNN和LSTM的学习可以分这么几个阶段
1。 了解结构和数学推导(forward, backward propagation, BPTT)这个阶段可以只考虑几个基本的经典结构,重点放在参数学习上
2。了解具体领域里面使用的RNN结构以及为什么使用这样的结构,这个阶段可以多花些心思在architecture上面
3。实践
说一下第一阶段的个人经验(假定纯新手初学RNN),先上结论,RNN和LSTM的推导看着吓人,其实真的不难,可以通过一两篇文章快速上手。
1-1. 推荐Sequence Modeling: Recurrent and Recursive Nets作为初学者的第一篇文章,因为按照教科书章节的标准写的,模型背景,big picture 方面有清晰的解释,阅读起来非常舒服,目前为止即便中文博客里面也没有找到比他更易懂的资源。与之相比,Hochreiter 的大作Long Short-Term Memory 使用的notation和现在常用的notation不一致,而且默认读者已经有了RNN的基础,所以初读起来会很吃力
阅读这一篇的时候,在RNN部分,建议注意(1)shared parameter 和unfolding (computational graph)这两个术语(2)各种RNN变种的结构(3)gradient vanishing的解释。 至于RNN的backpropagation,有两步:对节点求导,然后对参数求导。关于第一步,文章里的"For each node N we need to compute the gradient recursively, based on the gradient computed at nodes that follow it in the graph. "这句话精辟地概括了DNN+BP或是RNN+BPTT的关键步骤:当我们关于网络里面的某个节点求导时,只需要(去forward propagation表达式里面)找到他的所有直接子节点,把目标函数关于这些子节点的导数集合起来就好了。读者可以用文章里面提供的RNN BPTT 去方便地熟悉这个其实非常标准化的流程。
至于LSTM部分,只要练习Unfold文章里面举例的graph (图10.16),并且动手把各种gate的表达式和图的各个Node对应起来,再看各种LSTM的formulation就应该不再会懵逼了。另外这幅图和formulation的对应关系上有点bug,动手刷一遍forward propagation应该不难找出来(关键词peephole)。
1-2。第二篇是LSTM: search space odyssey。一定程度上算是对1-1学习效果的自测吧:(1)如果1-1有仔细研究过,这一篇的LSTM结构图应该很容易看懂;(2)按照1-1里面的求导流程,这篇文章附录里面的求导公式,虽然比简单的RNN长很多,但是你应该会觉得足够直观易懂。 至于文章的主要结论,“Our results show that none of the variants can improve upon the standard LSTM architecture significantly, and demonstrate the forget gate and the output activation function to be its most critical components. ”,可以暂且记下,等第三阶段慢慢体会
1-3。然后就可以毫不费力地看著名的http://colah.github.io/posts/2015-08-Understanding-LSTMs/,了
1-4。可以读原著文章了最近接到指导老师给的“看一下LSTM”的任务。
虽然之前已经了解过LSTM以及RNN的基本原理和适用范围,但是还没有写过代码,因此通过这个机会,将RNN以及LSTM及其变体,更详细的了解一下,并尽量将其实现。
Below comes from Wikipedia:
递归神经网络(RNN)是两种人工神经网络的总称。一种是时间递归神经网络(recurrent neural network),另一种是结构递归神经网络(recursive neural network)。时间递归神经网络的神经元间连接构成有向图,而结构递归神经网络利用相似的神经网络结构递归构造更为复杂的深度网络。
不做特别说明,本文中我使用 RNN 指代 Recurrent Neural Network,或循环神经网路。
RNN 可以描述动态时间行为,因为和前馈神经网络(feedforward neural network)接受较特定结构的输入不同,RNN将状态在自身网络中循环传递,因此可以接受更广泛的时间序列结构输入。手写识别是最早成功利用RNN的研究结果。
Tomas Mikolov 和 Martin Karafiat 在 2010 年提出了一个 rnn based language model。这个语言模型主要被应用在两个方面:
- 对任意一个 sentence,我们可以根据其在现实世界中出现的可能性来给其打分。这就给我们了一种用来衡量语法和语义准确性的准则。基于 RNN 的语言模型已经被广泛应用在机器翻译中,前几天 Google 发布的 GNMT,就是基于 LSTM 的改进,而 LSTM 则是基于 RNN。
- 一个语言模型(language model)使我们可以用来生成新文本。最近在微博上看到了很多利用 RNN 来写诗等的有趣应用,比如学习汪峰作词,学习李商隐写诗……
大神 Andrej Karpathy 向我们展示了一个基于 rnn 的 character-level 的语言模型,原文在此:The Unreasonable Effectiveness of Recurrent Neural Networks。
1. 什么是 RNNs ?在传统的神经网络中,输入和输出一般是相互独立的。RNNs 的核心思想就是怎样利用输入的 sequential information。比如,在词序的预测中,我们要预测下一个单词,那就需要根据它前面的单词来推测当前的单词可能是什么。
RNNs 的 recurrent 表示 它对序列中的每个元素都执行同样的 task,每个 element 计算的输出依赖于之前的计算结果。更形象一点地说,RNNs 有了 ’memory‘,它可以捕捉到目前为止已经得到的信息。理论上,RNNs 是可以用于任一长度的序列的,但是实际上,它们只对前几步有比较好的记忆效果。
一个 RNN 的结果如下图所示,把它展开,就是右边的样子,他们的内部结构是完全一样的。箭头表示时间序列/输入序列。图片来源于 Nature。
举例来说,如果我们输入了一个长度为 5 个单词的句子,那这个 RNN 展开之后就是一个 5 层的神经网络,每层处理一个 word。
x 表示每一层的输入,s 表示 hidden state,这就是前面说到的 ’memory‘,它通过 x 和 上一层的 s 计算得到,计算的函数是一个非线性函数,比如 tanh 或者 ReLU。第一层的 hidden state 通常被初始化为 0。 o 表示输出。例如如果我要预测一句话的下一个词是什么,那这个输出就是基于自定义的 vocabulary 的概率分布。我们可以使用 softmax 函数来计算得到输出。
Someting to NOTE:
- captures information about what happened in all the previous time steps. The output at step is calculated solely based on the memory at time .
- a traditional deep neural network, which uses different parameters at each layer, a RNN shares the same parameters (U,W,V above) across all steps.This reflects the fact that we are performing the same task at each step, just with different inputs.
- There’re outputs at each time step, but depending on the task this may not be necessary. Similarly, we may not need inputs at each time step.The main feature of an RNN is its hidden state, which captures some information about a sequence.
目前 RNNs 被广泛应用于 NLP 领域,而现在绝大多数的 RNNs Model 都是 LSTMs。在了解 LSTM 之前,先看一下 RNNs 在 NLP 领域应用的一些例子:
- LANGUAGE MODELING AND GENERATING TEXT
- MACHINE TRANSLATION
- SPEECH RECOGNITION
- GENERATING IMAGE DESCRIPTIONS
同样是使用 BP 算法,不过有点不同:Backpropagation Through Time (BPTT)。前面提到,由于 RNNs 中的参数是网络中的所有 time steps 共享的,所以我们计算当前步的梯度时,也需要利用前一步的信息。例如,我们计算 t=4 的梯度时,我们需要反向传播到前一步,然后将它们的梯度相加。在更深入的了解之前,需要明确的是, BPTT 在学习 long term dependencies 的时候是有困难的。这个问题被称作 ’Vanishing/Exploding gradient problem‘。这个问题一般是指我们常说的 vanilla RNNs。
4. A brief overview of RNNs Extensionsvanilla是什么意思呢?
“Vanilla” is a common euphemism(委婉语) for “regular” or “without any fancy stuff.”
类似于 naive
-
Bidirectional RNNs
They are based on the idea that the output at time may not only depend on the previous elements in the sequence, but also future elements.
They are just two RNNs stacked on top of each other. The output is then computed based on the hidden state of both RNNs.
-
Deep (Bidirectional) RNNs
They are similar to Bidirectional RNNs, only that we now have multiple layers per time step. In practice this gives us a higher learning capacity (but we also need a lot of training data).
-
LSTM networks
They use a different function to compute the hidden state. The memory in LSTMs are called cellsand you can think of them as black boxes that take as input the previous state and current input . Internally these cells decide what to keep in (and what to erase from) memory. They then combine the previous state, the current memory, and the input. It turns out that these types of units are very efficient at capturing long-term dependencies.
在此使用 Python 实现了一个全功能的 RNN,并用 Threano 进行 GPU 加速。完整的代码在我的 Github。
-
Language Modeling
我们的目标是用 RNN 搭建一个 Language Model。话句话说,我们有一个 m 个单词的句子,语言模型可以让我们预测被观测 sentence 在给定的 dataset 中的概率。
基于贝叶斯理论,我们有:
在单词层面,一句话的概率就是每个单词在给定之前单词时出现概率的乘积。举个例子来说,“He went to buy some chocolate.” 的概率就是在给定 “He went to buy some” 时,“chocolate”出现的概率乘以给定 “He went to buy”时 “some” 出现的概率乘以 …… 以此类推。
但这为什么会管用呢 ?为什么我们要给一个句子加上概率分布?
- 首先,这种模型可以被用作一个打分机制(scoring mechanism)。例如,一个 MT 系统一般对一个输入会产生多个可选值。这是你就可以使用一个语言模型来选出概率最大的句子。直觉上来说,最可能的句子也更可能是语法正确的。在语音识别系统中也有类似的打分机制。
- 解决这种语言模型问题也会有一个很酷的副作用。因为我们能根据给定的前置词序列预测一个单词的概率,所以我们可以用它来生成新文本。这就是一个生成式的模型。大神Andrej Karparthy 有一篇文章 解释了语言模型的这种能力。——— Mark———(还没看)
在上面的等式中,每个 word 都是需要它之前的所有词的,但是在实际中,很多模型在表示这种长距离依赖的时候有些问题。导致这些问题的原因有太耗费计算资源,或者内存不足等。所以,RNNs 一般只会 look 当前词之前的几个词。当然实际操作会更复杂一点。稍后就会讲到。
-
训练数据集 及 预处理
为了训练我们的 language model,我们当然需要一些数据用来学习。幸运的是,训练语言模型并不需要 labels,只需要 raw data 就可以。此处使用的数据集是 15000 个稍长的 红迪网的评论,在此。用稍后我们搭建的模型生成的一句跟真正的评论员很像。在那之前,我们需要先对数据做一些预处理,使其符合我们的需要的格式。
-
Tokenize text
我们需要将评论分成单个的句子,然后分成单个的 word。这里我们使用的 NLTK 的 word_tokenize 和 sent_tokenize 方法。
-
去掉词频很低的词
大多数词只出现了一两次,将这些词语去掉可以让我们的模型训练的更加快速。由于对这些词我们并没有很多上下文的例子,所以我们也不能用它们来学习如何正确的使用这些词频很低的词。这根人学习的过程是很详细的。如果想要知道如何正确的使用某个词,我们需要在不同的上下文环境中体会它们使用上的差别。 在代码中,将 vocabulary 限制到了 **vocabulary_size** 个最常见的单词。并将所有不在我们的 vocabulary 中的单词 设置为 **UNKOWN_TOKEN**。将其跟其他单词同样看待,在训练结束后如果有 UNKOWN_TOKEN,要么将其随机换成不在 vocabulary 中的词,要么继续训练只生成不含 UNKOWN_TOKEN 的句子。 -
为每句话添加 SENTENCE_START 和 SENTENCE_END
这样做的意义在于,如果给的是 SENTENCE_START,它的下一个单词可能是什么。也就是,如何生成每句话第一个真正的 word。 -
建立 训练数据矩阵
输入到 RNN 中的是向量,不是字符串。因此向其他文本处理的模型一样,我们先建立 word 和 index/id 之间的映射关系:index_to_word 和 word_to_index。 For example, the word “friendly” may be at index 2001. A training example  may look like `[0, 179, 341, 416]`, where 0 corresponds to `SENTENCE_START`. The corresponding label 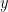 would be `[179, 341, 416, 1]`. Remember that our goal is to predict the next word, so y is just the x vector shifted by one position with the last element being the `SENTENCE_END` token. In other words, the correct prediction for word `179` above would be `341`, the actual next word.vocabulary_size = 8000 unknown_token = "UNKNOWN_TOKEN" sentence_start_token = "SENTENCE_START" sentence_end_token = "SENTENCE_END" # Read the data and append SENTENCE_START and SENTENCE_END tokens print "Reading CSV file..." with open('data/reddit-comments-2015-08.csv', 'rb') as f: reader = csv.reader(f, skipinitialspace=True) reader.next() # Split full comments into sentences sentences = itertools.chain(*[nltk.sent_tokenize(x[0].decode('utf-8').lower()) for x in reader]) # Append SENTENCE_START and SENTENCE_END sentences = ["%s %s %s" % (sentence_start_token, x, sentence_end_token) for x in sentences] print "Parsed %d sentences." % (len(sentences)) # Tokenize the sentences into words tokenized_sentences = [nltk.word_tokenize(sent) for sent in sentences] # Count the word frequencies word_freq = nltk.FreqDist(itertools.chain(*tokenized_sentences)) print "Found %d unique words tokens." % len(word_freq.items()) # Get the most common words and build index_to_word and word_to_index vectors vocab = word_freq.most_common(vocabulary_size-1) index_to_word = [x[0] for x in vocab] index_to_word.append(unknown_token) word_to_index = dict([(w,i) for i,w in enumerate(index_to_word)]) print "Using vocabulary size %d." % vocabulary_size print "The least frequent word in our vocabulary is '%s' and appeared %d times." % (vocab[-1][0], vocab[-1][1]) # Replace all words not in our vocabulary with the unknown token for i, sent in enumerate(tokenized_sentences): tokenized_sentences[i] = [w if w in word_to_index else unknown_token for w in sent] print "\nExample sentence: '%s'" % sentences[0] print "\nExample sentence after Pre-processing: '%s'" % tokenized_sentences[0] # Create the training data X_train = np.asarray([[word_to_index[w] for w in sent[:-1]] for sent in tokenized_sentences]) y_train = np.asarray([[word_to_index[w] for w in sent[1:]] for sent in tokenized_sentences])经过处理后的 training example 像下面这样:x: SENTENCE_START what are n't you understanding about this ? ! [0, 51, 27, 16, 10, 856, 53, 25, 34, 69] y: what are n't you understanding about this ? ! SENTENCE_END [51, 27, 16, 10, 856, 53, 25, 34, 69, 1] -
构造 RNN
前面已经了解了 RNN 的结构,这里我们开始具体介绍这里的模式是怎样的。 输入 x 是一个 sequence of words,x 的每个元素都是一个单词。但是这里我们还有一件事要做。由于据陈惩罚的机理限制,我们不能直接使用单词的 index 作为输入,而是使用 vocabulary_size 大小的 one-hot vector。也就是说,每个 word 都变成了一个 vector,这样输入 x 也就变成了 matrix,这时每一行表示一个word。我们在神经网络中执行这一转换,而不是在之前的预处理中。同样的,输出 o 也有类似的格式,o 是一个矩阵,它的每一行是一个 vocabulary_size 长的 vector,其中每个元素代表其所对应的位置的所对应的单词表中的单词在输入的这句话中,出现在下一个待预测位置的概率。 我们先回顾一下 RNN 中的等式关系:  在推倒过程中写下矩阵和向量的维度是一个好习惯,我们假设选出了一个 8000 个词的 vocabulary。 Hidden layer 的 size H = 100。这里的 hidden layer size 可以看做是我们的 RNN 模型的 “memory”。增大这个值标表示我们可以学习更加复杂的模式。这也会导致额外的计算量。现在我们有如下变量:  这里的 U, V, W 都是我们的神经网络需要学习的参数。因此,我们一共需要 2HC + H^2 = 2\*100\*8000 + 100\*100 = 1,610,000。温度也告诉我们了我们的模型的瓶颈在哪里。由于 x_t 是 独热编码的向量,将它与 U 相乘本质上等同于选择 U 的一列,所以我们不需要做全部的乘法。还有,我们的网络中,最大的矩阵乘法是 V.dot(s_t). 这就是我们尽可能让我们的 vocabulary size 尽可能小的原因。 有了这些基础的概念之后,我们开始实现我们的神经网络: -
初始化
class RNNNumpy: def __init__(self, word_dim, hidden_dim=100, bptt_truncate=4): # Assign instance variables self.word_dim = word_dim self.hidden_dim = hidden_dim self.bptt_truncate = bptt_truncate # Randomly initialize the network parameters self.U = np.random.uniform(-np.sqrt(1./word_dim), np.sqrt(1./word_dim), (hidden_dim, word_dim)) self.V = np.random.uniform(-np.sqrt(1./hidden_dim), np.sqrt(1./hidden_dim), (word_dim, hidden_dim)) self.W = np.random.uniform(-np.sqrt(1./hidden_dim), np.sqrt(1./hidden_dim), (hidden_dim, hidden_dim))这里我们不能直接将 U,V,W 直接初始化为 0, 因为这会导致在所有的 layers 中的 semmetric calculations 的问题。我们必须随机初始化它。因为很多研究表明,合适的初始化对训练结果是有影响的。并且最好的初始化方法取决于我们选择什么样的激活函数,当前模型我们使用的是 tanh。[这篇论文](http://jmlr.org/proceedings/papers/v9/glorot10a/glorot10a.pdf)说一种推荐的办法是将权重随机初始化为在 +-1/sqrt(n) 之间的数。 -
前向传播( predict word probabilities)
def forward_propagation(self, x): # The total number of time steps T = len(X) # During forward propagation, we save all hidden states in s because need them later # We add one additional element for the initial hidden, which we set to 0 s = np.zeros((T+1, self,hidden_dim)) s[-1] = np.zeros(self.hidden_dim) # The outputs at each time step. Again, we save them for later o = np.zeros((T, self.word_dim)) # For each time step ... for t in np.arange(T): # Note that we are indxing U by x[t]. This is the same as multiplying U with a one-hot vector. s[t] = np.tanh(self.U[:, x[t]] + self.W.dot(s[t-1])) o[t] = softmax(self.V.dot(s[t])) return [o,s] RNNNumpy.forward_propagation = forward_propagation这里返回的 o 和 s 会在接下来被用作计算梯度,这样可以避免重复计算。输出 o 的每一个元素都代表单词表中每个词出现的概率。但在有些时候,我们仅需要概率最高的那个 word,为此我们可以做如下 **precdict**:def predict(self, x): # Perform forward propagation and return index of the highest score o, s = self.forward_propagation(x) return np.argmax(o, axis=1) RNNNumpy.predict = predict现在来看一下效果:np.random.seed(10) model = RNNNumpy(vocabulary_size) o, s = model.forward_propagation(X_train[10]) print o.shape() print o(45, 8000) [[ 0.00012408 0.0001244 0.00012603 ..., 0.00012515 0.00012488 0.00012508] [ 0.00012536 0.00012582 0.00012436 ..., 0.00012482 0.00012456 0.00012451] [ 0.00012387 0.0001252 0.00012474 ..., 0.00012559 0.00012588 0.00012551] ..., [ 0.00012414 0.00012455 0.0001252 ..., 0.00012487 0.00012494 0.0001263 ] [ 0.0001252 0.00012393 0.00012509 ..., 0.00012407 0.00012578 0.00012502] [ 0.00012472 0.0001253 0.00012487 ..., 0.00012463 0.00012536 0.00012665]]```
45 表示有对于给定的句子的 45 个word,我们的模型产出了 8000 个预测结果,分别代表下一个词的概率。需要注意的是,因为我们是随机初始化的 U, V, W,因此这里产出的”预测“实际上也是随机的结果。下面给出了概率最高的词的索引:
python predictions = model.predict(X_train[10]) print predictions.shape print predictions
(45,) [1284 5221 7653 7430 1013 3562 7366 4860 2212 6601 7299 4556 2481 238 2539 21 6548 261 1780 2005 1810 5376 4146 477 7051 4832 4991 897 3485 21 7291 2007 6006 760 4864 2182 6569 2800 2752 6821 4437 7021 7875 6912 3575]-
计算损失
在训练网络之前,我们首先需要定义一个衡量误差的 metric,这就是以前常说的损失函数 loss function L。我们的目标是找到使得损失函数最小化的 U, V, W。损失函数的一种常见的选择就是交叉熵损失。如果我们有 N 个训练样本(words)和 C 个类别(vocabulary_size),那么给定了真实的label值,我们的预测 o 的损失函数是:
def calculate_total_loss(self, x, y): L = 0 # For each sentence ... for i in np.arange(len(y)): o, s = self.forward_propagation(x[i]) # We only care about our prediction of the 'correct' words correct_word_predictions = o[np.arange(len(y[i])), y[i]] # Add to the loss based on how off we are L += -1 * np.sum(np.log(correct_word_predictions)) return L def calculate_loss(self, x, y): # Divide the total loss by the number of training examples N = np.sum((len(y_i) for y_i in y)) return self.calculate_total_loss(x,y)/N RNNNumpy.calculate_total_loss = calculate_total_loss RNNNumpy.calculate_loss = calculate_loss在随机情况下,我们的实现计算出的损失可以当做 baseline。随机的情况也可以用于保证我们的实现是正确的。vocabulary 中有 C 个 words,所以理论上每个 word 被预测到的概率应该是 1/C,这时候我们得到的损失函数是 logC:
# Limit to 1000 examples to save time print "Expected Loss for random predictions: %f" % np.log(vocabulary_size) print "Actual loss: %f" % model.calculate_loss(X_train[:1000], y_train[:1000])Expected Loss for random predictions: 8.987197 Actual loss: 8.987440我们计算出的结果跟理论值很接近,这说明我们的实现是正确的。
-
使用 BPTT 和 SGD 训练 RNN
再次明确一下我们的目标:
找到使得损失函数最小的 U, V, W
最常用的方式是 随机梯度下降 Stochastic Gradient Descend。SGD的思路是很简单的,在整个训练样本中迭代,每次迭代我们朝某个使得无插减小的方向 nudge 我们的参数。这些方向通过分别对 L 求 U, V, W的偏导来确定。 SGD 也需要 learning rate,它定义了每一步我们要迈多大。 SGD 也是神经网络最受欢迎的一种优化的方式,也适用于其他很多的机器学习算法。关于如何优化 SGD 也已经有了很多的研究,比如使用 batching,parallelism 和 adaptive learning rates。尽管基本想法很简单,将 SGD 实现地很有效率却是一个比较复杂的事情。
关于 SGD 的更多内容,这里有个教程.
这里实现的是一个简单版本的 SGD,即使没有任何关于优化的基础知识,也是可以看懂的。
现在问题来了,我们应该如何计算梯度呢?在传统的神经网络中,我们使用反向传播算法。在 RNN 中,我们使用的是它的一个变体: Backpropagation Through Time(BPTT)。由于参数是在所有的层之间共享的,因此当前层的梯度值的计算除了要基于当前的这一步,还有依赖于之前的 time steps。这其实就是应用微积分的链式法则。目前我们只是宽泛地谈了一下 BPTT,后面会做详细介绍。
关于 back propagation ,这里有两个博客可以参考:1, 2
目前暂时将 BPTT 看作一个黑盒,它以训练数据(x,y)为输入,返回损失函数在 U, V, W 上的导数值。
def bptt(self, x, y): pass RNNNumpy.bptt = bptt -
Gradient Checking
这里提供的一条 tip 是,在你实现反向传播算法的时候,最好也实现一个 gradient checking,它用来验证你的代码是否正确。 gradient checking 的想法是某个参数的倒数等于那一点的斜率,我们可以将参数变化一下,然后除以变化率来近似地估计:
然后我们可以比较使用 BP 计算的梯度和使用上面的公式计算的梯度。如果没有很大的差别的话,说明我们的实现是正确的。
上面的估计需要计算每个参数的 total loss,因此 gradient checking 也是很耗时的操作,在这里,我们只要在一个小规模的例子上模拟一下就可以了。
def gradient_check(self, x, y, h=0.001, error_threshold=0.01): # Calculate the gradients using backpropagation. We want to checker if these are correct. bptt_gradients = self.bptt(x, y) # List of all parameters we want to check. model_parameters = ['U', 'V', 'W'] # Gradient check for each parameter for pidx, pname in enumerate(model_parameters): # Get the actual parameter value from the mode, e.g. model.W parameter = operator.attrgetter(pname)(self) print "Performing gradient check for parameter %s with size %d." % (pname, np.prod(parameter.shape)) # Iterate over each element of the parameter matrix, e.g. (0,0), (0,1), ... it = np.nditer(parameter, flags=['multi_index'], op_flags=['readwrite']) while not it.finished: ix = it.multi_index # Save the original value so we can reset it later original_value = parameter[ix] # Estimate the gradient using (f(x+h) - f(x-h))/(2*h) parameter[ix] = original_value + h gradplus = self.calculate_total_loss([x],[y]) parameter[ix] = original_value - h gradminus = self.calculate_total_loss([x],[y]) estimated_gradient = (gradplus - gradminus)/(2*h) # Reset parameter to original value parameter[ix] = original_value # The gradient for this parameter calculated using backpropagation backprop_gradient = bptt_gradients[pidx][ix] # calculate The relative error: (|x - y|/(|x| + |y|)) relative_error = np.abs(backprop_gradient - estimated_gradient)/(np.abs(backprop_gradient) + np.abs(estimated_gradient)) # If the error is to large fail the gradient check if relative_error > error_threshold: print "Gradient Check ERROR: parameter=%s ix=%s" % (pname, ix) print "+h Loss: %f" % gradplus print "-h Loss: %f" % gradminus print "Estimated_gradient: %f" % estimated_gradient print "Backpropagation gradient: %f" % backprop_gradient print "Relative Error: %f" % relative_error return it.iternext() print "Gradient check for parameter %s passed." % (pname) RNNNumpy.gradient_check = gradient_check # To avoid performing millions of expensive calculations we use a smaller vocabulary size for checking. grad_check_vocab_size = 100 np.random.seed(10) model = RNNNumpy(grad_check_vocab_size, 10, bptt_truncate=1000) model.gradient_check([0,1,2,3], [1,2,3,4]) -
SGD 实现
现在我们已经可以为参数计算梯度了:
- sgd_step 用来计算梯度值和进行批量更新
- 一个在训练集上迭代的外部循环,并且不断调整 learning rate
# Performs one step of SGD def numpy_sdg_step(self, x, y, learning_rate): # Calculate the gradients: dLdU, dLdV, dLdW = self.bptt(x,y) # Change parameters according to gradients and learning rate self.U -= learning_rate * dLdU self.V -= learning_rate * dLdV self.W -= learning_rate * dLdW RNNNumpy.sgd_step = numpy_sdg_step# Outer SGD loop # - model: The RNN model instance # - X_train: The training dataset # - y_train: The training data labels # - learning_rate: Initial learning rate for SGD # - nepoch: Number of times to iterate through the complete dataset # - evaluate_loss_after: Evaluate the loss after this many epochs def train_with_sgd(model, X_train, y_train, learning_rate=0.005, nepoch=100, evaluate_loss_after=5): losses = [] num_examples_seen = 0 for epoch in range(nepoch): # Optionally evaluate the loss if (epoch % evaluate_loss_after == 0): loss = model.calculate_loss(X_train, y_train) losses.append(num_examples_seen, loss)) time = datetime.now().strftime('%Y-%n-%d %H:%M:%S') print '%s: Loss after num_examples_seen=%d epoch=%d' %(time, num_examples_seen, epoch, loss) # Adjust the learning rate if loss increases if(len(losses) >: 1 and losses[-1][1] > losses[-2][1]): learning_rate = learning_rate * 0.5 print 'Setting learning rate to %f' % learning_rate sys.stdout.flush() # For each training example ... for i in range(len(y_train)): # One SGD step model.sgd_step(X_train[i], y_train[i], learning_rate) num_examples_seen += 1到这里,已经基本完成了。先试一下:
np.random.seed(10) model = RNNNumpy(vocabulary_size) %timeit model.sgd_step(X_train[10], y_train[10], 0.005)你会发现速度真的很慢,因此我们需要加速我们的代码:
例如,使用 hierarchical softmax 或者加一个 projection layer 来避免大矩阵的乘法操作(这里和这里)
这里并没有采用上面提到的优化方式,因为我们还有一个选择,在 GPU 上跑我们的 model。在那之前,去哦们现在一个小数据集上测试一下 loss 是不是下降的:
np.random.seed(10) # Train on a small subset of the data to see what happens model = RNNNumpy(vocabulary_size) losses = train_with_sgd(model, X_train[:100], y_train[:100], nepoch=10, evaluate_loss_after=1)2015-09-30 10:08:19: Loss after num_examples_seen=0 epoch=0: 8.987425 2015-09-30 10:08:35: Loss after num_examples_seen=100 epoch=1: 8.976270 2015-09-30 10:08:50: Loss after num_examples_seen=200 epoch=2: 8.960212 2015-09-30 10:09:06: Loss after num_examples_seen=300 epoch=3: 8.930430 2015-09-30 10:09:22: Loss after num_examples_seen=400 epoch=4: 8.862264 2015-09-30 10:09:38: Loss after num_examples_seen=500 epoch=5: 6.913570 2015-09-30 10:09:53: Loss after num_examples_seen=600 epoch=6: 6.302493 2015-09-30 10:10:07: Loss after num_examples_seen=700 epoch=7: 6.014995 2015-09-30 10:10:24: Loss after num_examples_seen=800 epoch=8: 5.833877 2015-09-30 10:10:39: Loss after num_examples_seen=900 epoch=9: 5.710718我么可以看到, loss 的确是在一直下降的。
-
使用 Theano 在 GPU 上训练我们的网络
这里有一个 Theano 的[教程](tutorial。
重新写了一个RNNTheano,将 numpy 的计算使用 Theano 中的计算进行了替代。
np.random.seed(10) model = RNNTheano(vocabulary_size) %timeit model.sgd_step(X_train[10], y_train[10], 0.005) -
生成文本
现在已经得到了模型,我们可以用来生成文本了:
def generate_sentence(model): # We start the sentence with the start token new_sentence = [word_to_index[sentence_start_token]] # Repeat until we get an end token while not new_sentence[-1] == word_to_index[sentence_end_token]: next_word_probs = model.forward_propagation(new_sentence) sampled_word = word_to_index[unknown_token] # We don't want to sample unknown words while sampled_word == word_to_index[unknown_token]: samples = np.random.multinomial(1, next_word_probs[-1]) sampled_word = np.argmax(samples) new_sentence.append(sampled_word) sentence_str = [index_to_word[x] for x in new_sentence[1:-1]] return sentence_str num_sentences = 10 senten_min_length = 7 for i in range(num_sentences): sent = [] # We want long sentences, not sentences with one or two words while len(sent) < senten_min_length: sent = generate_sentence(model) print " ".join(sent)下面是测试效果:
Anyway, to the city scene you’re an idiot teenager. What ? ! ! ! ! ignore! Screw fitness, you’re saying: https Thanks for the advice to keep my thoughts around girls. Yep, please disappear with the terrible generation.
-
现在的模型存在的问题是
vanilla RNN 几乎不能成成有意义的文本,因为它不能学习隔了很多步的依赖关系。
接下来我们先深入了解一下 BPTT 和 vanishing gradient,然后开始介绍 LSTM。
在这一部分,主要了解一下 BPTT 以及它跟传统的反向传播算法有什么区别。然后尝试理解 vanishing gradient 的问题,这个问题也催生出了后来的 LSTMs 和 GRUs,后两者也是当今 NLP 领域最有效的模型之一。
起初,vanishing gradient 问题是在 1991 年被 Sepp Hochreiter 首次发现的,并且在最近由于深层架构的使用而越来越受关注。
这一部分需要偏导以及基本的反向传播理论的基础,如果你并不熟悉的话,可以看这里,这里和这里。
-
BPTT
上式为我们如何计算总的交叉熵损失。
我们将每句话 sentence 看做一个 training example,因此整体的损失就是每一步的损失的和
再次明确,我们的目标是计算出损失函数对 U, V, W 的梯度,然后使用梯度下降算法来学习更好的参数。类似于我们将误差相加,我们也将每个训练样本在每一步的梯度相加:
为了计算这些梯度值,我们使用求到的链式法则。这就是所谓的反向传播算法,它使误差从后向前传播。比如,我们以 E3 为例:
由于,所以我们需要继续向前求导:
从上面这个式子我们可以看出,由于 W 是在每一步共享的,我们在 t=3 的时候需要一直反向传播到 t=0 time step:
这其实跟我们在深度前向反馈神经网络中用的标准的反向传播算法是相通的,不同的地方在于对于 W 我们将每一步求和。在传统的 NN 中我们并没有在层间共享权值,因此我们也就不需要求和这一步。
def bptt(self, x, y): def bptt(self, x, y): T = len(y) # Perform forward propagation o, s = self.forward_propagation(x) # We accumulate the gradients in these variables dLdU = np.zeros(self.U.shape) dLdV = np.zeros(self.V.shape) dLdW = np.zeros(self.W.shape) delta_o = o delta_o[np.arange(len(y)), y] -= 1. # For each output backwards ... for t in np.arange(T)[::-1]: dLdV += np.outer(delta_o[t], s[t].T) delta_t = self.V.T.dot(delta_o[t])*(1-(s[t]**2)) # Back Propagation Through Time (for at most self.bptt_truncate steps) for bptt_step in np.arange(max(0,t-self.bptt_truncate), t+1)[::-1]: # print "Backpropagation step t=%d bptt step=%d" %(t, bptt_step) dLdW += np.outer(delta_t, s[bptt_step-1]) dLdU[:,x[bptt_step]] += delta_t # Update delta for next step delta_t = self.W.T.dot(delta_t) * (1 - s[bptt_step-1] ** 2) return [dLdU, dLdV, dLdW]看到这里你应该也能体会到为什么标准的 RNNs 很难训练了,sequence 可能会相当长,因此你需要法相传播很多层,在实际中,很多人会选择将反向传播 truncate 为 a few steps。
-
the Vanishing Gradient Problem
让我们再看一下这个公式:
其中,是一个链式法则,例如,
值得注意的是,因为我们是在对一个 vector function 关于一个 vector 求导,结果其实就是一个矩阵,这个矩阵叫做 雅克比矩阵(Jacobian Matrix),其中每个元素都是逐点的求导:
上面的 Jacobian Matrix 的第二范式的上界是 1,这是很符合直觉的,因为我们使用的 tanh(双曲正切)激活函数将所有的值映射到 0-1 之间,它的导数也被限定在 1 内。下图是 tanh 和它的导数:
我们可以看到, tanh 的导数在两端均为 0。他们都接近一条直线。当这种情况发生时,我们说对应的神经元已经 saturate 了。它们的梯度值为 0,并且在 drive 之前层的其他梯度值也朝 0 发展。因此,矩阵中有 small values 的多个矩阵乘法会使得梯度值以指数级的速度 shrinking。最终,在几步之后,梯度就会彻底消失掉。这时,来自很远的地方的梯度贡献变成了 0,这些步也就没有了贡献。因此,你最终还是无法学习长距离依赖。Vanishing Gradient 并不只在 RNNs 中存在,它们在 deep Feedforward Neural Networks 中也存在,只是 RNNs 一般倾向于生成更深层次的神经网络,也就使得这个问题在 RNNs 中尤其明显。
类比一下,如果矩阵中的值变得很大那么神经网络的参数会开始 ”exploging“, 而不是 ”vanishing“。因此,我们将这类问题称作 ”exploding/vanishing gradient problem“。
实际中人们更长接触到的是 vanishing problem,这有两个原因:
- exploding gradient 一般是很明显的,因为到某一步时,这些参数值会变成 NaN,你的程序也会 crash 掉。
- 在到达一个阈值时截断 clip 梯度可以比较好的解决 exploding 的问题,但是 vanishing 就没这么容易解决了,因为它表现得不如 exploding 明显。
幸运的是,现在已经有一些可行的操作来应对 vanishing gradient 的问题。
例如,对 W 进行更加合适的初始化操作会 alleviate 这个问题。
人们更倾向于采用 ReLU 来替代 tanh 或者 sigmoid 来作为激活函数使用。ReLU 的导数是一个常数,要么为 0,要么为 1。所以它可以比较好地规避 vanishing 的问题。
更加进阶的方法就是使用 LSTMs 或者 GRU 了
LSTMs 最早在 1997 年被提出,它可能是目前为止 NLP 领域应用最广泛的模型。
GRUs 第一次提出是在 2014 年,它是一个简化版本的 LSTMs。
以上两种 RNN 结构都是用来显式地被设计为解决 vanishing gradient 问题,现在让我们正式开始:
在完整的了解 RNNs 的细节之前,我已经学习过了 LSTMs,详情见我的这篇 深入理解LSTM。
概括来说,LSTMs 针对 RNNs 的 long-term dependencies 问题,引入了 门机制 gating 来解决这个问题。先来回顾一下上面我这篇 post 中提到的 LSTMs 的主要的计算公式:
其中,o 表示逐点操作。
i, f, o 分别是 输入、遗忘和输出门。从上面我们一刻看到他们的公式是相同的,只不过对应的参数矩阵不同。关于input, forget 和 output 分别代表什么意义,看上面这篇 post。需要注意的一点是,所有这些 gates 有相同的维度 d,d 就是 hidden state size。比如,前面的 RNNs 实现中的 hidden_size = 100。
g 是基于当前输入和前一步隐状态的 hidden state。这跟前面的 vanilla RNNs 是一样求的。只是将 U,W 的名字改了一下。但是,我们没有像在 RNN 中那样将 g 当做 new hidden state,而是用前面的 input gate 挑选出其中一些来。
c_t 是当前 unit 的 ’memory‘。从上面的公式可以看出,它定义了我们怎样将之前的记忆和和新的输入结合在一起。给定了 c_t,我们就可以计算出 hidden_state s_t,使用上面的公式。
不知你是否已经感觉到, plain/vanilla RNNs 可以看做是 LSTMs 的一个特殊变体,你把 input gate 固定位 1,forget gate 固定位 0, output gate 固定位 1,你就几乎得到了一个标准的 RNN。唯一不同的地方是多了个 tanh。
综上,门机制使得 LSTMs 可以显式地解决长距离依赖的问题。通过学习门的参数,网络就知道了如何处理它的 memory。
现在已经有了很多 LSTMs 的变体,比如一种叫做 peephole 的变体:
这里有一篇关于评估 LSTM 的不同结构的 paper: LSTM: A Search Space Odyssey。
-
GRUs
GRU(Gated Recurrent Unit) 有两个 gate, 一个 reset gate r, 一个 update gate z。顾名思义,reset gate 决定如何组合新的输入和之前的记忆,update gate 决定多少之前的记忆被保留。如果将 reset gate 置为全 1,将 update gate 置为全 0,就得到了 vanilla RNNs。
GRU 和 LSTM 的区别主要在于:
- GRU 只有两个 gates。
- GRU 没有 internal memory(c_t),没有 output gate
- GRU 的 input 和 forget 耦合在一起,形成 update gate。reset gate 直接被作用在 previous hidden state 上。因此,reset gate 实际上在 LSTM 中被分在了 r 和 z 中。
- GRU 在计算输出时,不再使用另外的非线性函数处理。
-
实例: LSTM Networks for Sentiment Analysis
这个实例来自于 Theano 的官方文档,使用 IMDB dataset 来做情感分析。
具体来说,给定一篇影评,预测出评价是积极的还是消极的,这是一个二分类问题。
LSTM model introduces a new structure called a memory cell (see below). A memory cell is composed of four main elements:
- an input gate
- a neuron with a self-recurrent connection (a connection to itself)
- a forget gate
- an output gate
The self-recurrent connection has a weight of 1.0 and ensures that, barring any outside interference, the state of a memory cell can remain constant from one timestep to another.
The gates serve to modulate the interactions between the memory cell itself and its environment.
- The input gate can allow incoming signal to alter the state of the memory cell or block it.
- On the other hand, the output gate can allow the state of the memory cell to have an effect on other neurons or prevent it.
- Finally, the forget gate can modulate the memory cell’s self-recurrent connection, allowing the cell to remember or forget its previous state, as needed.
完整的计算步骤如下:
在这个情感分析模型中,此处在计算一个 cell 的 output gate activation function 时省略了memory cell state C_t,这样做的目的是提高效率。因此,上面的(5)需要将 VoCt去掉。
整个模型由一个 LSTM layer 和一个 average pooling layer 和一个 logistic regression layer 层组成,如下图所示:
From an input sequence , the memory cells in the LSTM layer will produce a representation sequence . This representation sequence is then averaged over all timesteps resulting in representation h. Finally, this representation is fed to a logistic regression layer whose target is the class label associated with the input sequence.
在实现时, (1), (2), (3) and (5) 是并行计算的,这是可行的因为这些等式并不依赖于其他等式。这里通过将 W* 和 U* 和 b* 分别连接成 W,U 和 b,然后通过下面的等式进行计算:
计算出结果后,将其分开就得到了 , , 和,然后对每一个独立的应用非线性函数。
代码在此:
- lstm.py : Main script. Defines and train the model.
- imdb.py : Secondary script. Handles the loading and preprocessing of the IMDB dataset.
将上面两个文件放在同一个文件夹下,然后执行
THEANO_FLAGS="floatX=float32" python lstm.py这个模型支持 SGD,AdaDelta 和 RMSProp 等优化方法。推荐使用 AdaDelta 或者 RMSProp,因为 SGD 在这个任务中真的很慢。
训练过程中,可以看到 Cost在逐渐减小:
设置的最大迭代次数是 100 次,在我的电脑上用 GPU 跑本次实验的结果如下:
学习整个 LSTMs 的过程我主要看了如下五个材料,并查阅了其他相关的术语定义,完成了其中的 RNN 和 LSTM 的两个实验。
-
《神经网络与深度学习》— 吴岸城,第 4.7 节
- 图解LSTM神经网络架构及其11种变体(附论文)
- Recurrent Neural Networks Tutorial[1-4]
- Understanding LSTM Networks
- LSTM Networks for Sentiment Analysis
其中,最后一篇参考资料引用了如下内容:
Introduction of the LSTM model:
- [pdf] Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780.
Addition of the forget gate to the LSTM model:
- [pdf] Gers, F. A., Schmidhuber, J., & Cummins, F. (2000). Learning to forget: Continual prediction with LSTM. Neural computation, 12(10), 2451-2471.
More recent LSTM paper:
- [pdf] Graves, Alex. Supervised sequence labelling with recurrent neural networks. Vol. 385. Springer, 2012.
Papers related to Theano:
- [pdf] Bastien, Frédéric, Lamblin, Pascal, Pascanu, Razvan, Bergstra, James, Goodfellow, Ian, Bergeron, Arnaud, Bouchard, Nicolas, and Bengio, Yoshua. Theano: new features and speed improvements. NIPS Workshop on Deep Learning and Unsupervised Feature Learning, 2012.
- [pdf] Bergstra, James, Breuleux, Olivier, Bastien, Frédéric, Lamblin, Pascal, Pascanu, Razvan, Desjardins, Guillaume, Turian, Joseph, Warde-Farley, David, and Bengio, Yoshua. Theano: a CPU and GPU math expression compiler. In Proceedings of the Python for Scientific Computing Conference (SciPy), June 2010.
在写这篇完整的 post 的最后,我想总结一下目前还没有解决的问题:
- 公式的正确书写格式。目前几乎所有公式是直接复制或者不标准地用字符表示的,这个需要日后学习 LaTeX 。
- 最近在逐个实现这些模型的过程中,对理论如何转化为计算机可以操作的步骤之间的体会越来越深刻,日后学习心的概念时,尽量紧跟着看一下如何具体操作。
- 关于 SGD 的各种优化方法,需要进一步的了解,目前为止只是了解了最基本的形式,对于 AdaDelta 和 RMSProp 等方法还需要具体去看。
- 关于 GRU 和 LSTM 的区别,这个只能是通过使用来体会这两者的差别。
总而言之,post 虽然写完,但还是有很多坑要填。 —_—
https://zhuanlan.zhihu.com/p/22266022














 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









