http://shiyanjun.cn/archives/1097.html
基于Spark通用计算平台,可以很好地扩展各种计算类型的应用,尤其是Spark提供了内建的计算库支持,像Spark Streaming、Spark SQL、MLlib、GraphX,这些内建库都提供了高级抽象,可以用非常简洁的代码实现复杂的计算逻辑、这也得益于Scala编程语言的简洁性。这里,我们基于1.3.0版本的Spark搭建了计算平台,实现基于Spark Streaming的实时计算。
我们的应用场景是分析用户使用手机App的行为,描述如下所示:
- 手机客户端会收集用户的行为事件(我们以点击事件为例),将数据发送到数据服务器,我们假设这里直接进入到Kafka消息队列
- 后端的实时服务会从Kafka消费数据,将数据读出来并进行实时分析,这里选择Spark Streaming,因为Spark Streaming提供了与Kafka整合的内置支持
- 经过Spark Streaming实时计算程序分析,将结果写入Redis,可以实时获取用户的行为数据,并可以导出进行离线综合统计分析
Spark Streaming介绍
Spark Streaming提供了一个叫做DStream(Discretized Stream)的高级抽象,DStream表示一个持续不断输入的数据流,可以基于Kafka、TCP Socket、Flume等输入数据流创建。在内部,一个DStream实际上是由一个RDD序列组成的。Sparking Streaming是基于Spark平台的,也就继承了Spark平台的各种特性,如容错(Fault-tolerant)、可扩展(Scalable)、高吞吐(High-throughput)等。
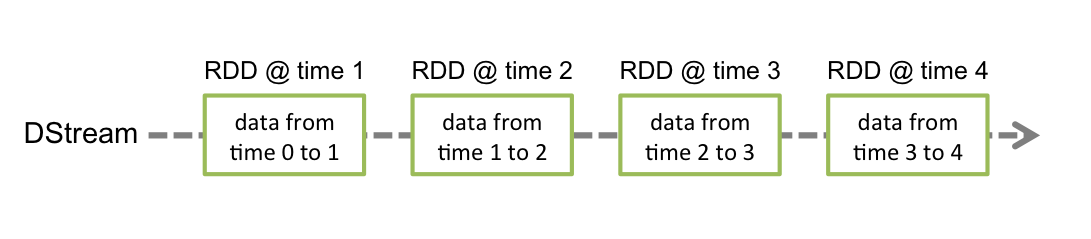
在Spark Streaming中,每个DStream包含了一个时间间隔之内的数据项的集合,我们可以理解为指定时间间隔之内的一个batch,每一个batch就构成一个RDD数据集,所以DStream就是一个个batch的有序序列,时间是连续的,按照时间间隔将数据流分割成一个个离散的RDD数据集,如图所示(来自官网):
我们都知道,Spark支持两种类型操作:Transformations和Actions。Transformation从一个已知的RDD数据集经过转换得到一个新的RDD数据集,这些Transformation操作包括map、filter、flatMap、union、join等,而且Transformation具有lazy的特性,调用这些操作并没有立刻执行对已知RDD数据集的计算操作,而是在调用了另一类型的Action操作才会真正地执行。Action执行,会真正地对RDD数据集进行操作,返回一个计算结果给Driver程序,或者没有返回结果,如将计算结果数据进行持久化,Action操作包括reduceByKey、count、foreach、collect等。关于Transformations和Actions更详细内容,可以查看官网文档。
同样、Spark Streaming提供了类似Spark的两种操作类型,分别为Transformations和Output操作,它们的操作对象是DStream,作用也和Spark类似:Transformation从一个已知的DStream经过转换得到一个新的DStream,而且Spark Streaming还额外增加了一类针对Window的操作,当然它也是Transformation,但是可以更灵活地控制DStream的大小(时间间隔大小、数据元素个数),例如window(windowLength, slideInterval)、countByWindow(windowLength, slideInterval)、reduceByWindow(func, windowLength, slideInterval)等。Spark Streaming的Output操作允许我们将DStream数据输出到一个外部的存储系统,如数据库或文件系统等,执行Output操作类似执行Spark的Action操作,使得该操作之前lazy的Transformation操作序列真正地执行。
Kafka+Spark Streaming+Redis编程实践
下面,我们根据上面提到的应用场景,来编程实现这个实时计算应用。首先,写了一个Kafka Producer模拟程序,用来模拟向Kafka实时写入用户行为的事件数据,数据是JSON格式,示例如下:
1 | {"uid":"068b746ed4620d25e26055a9f804385f","event_time":"1430204612405","os_type":"Android","click_count":6} |
一个事件包含4个字段:
- uid:用户编号
- event_time:事件发生时间戳
- os_type:手机App操作系统类型
- click_count:点击次数
下面是我们实现的代码,如下所示:
01 | package org.shirdrn.spark.streaming.utils |
03 | import java.util.Properties |
04 | import scala.util.Properties |
05 | import org.codehaus.jettison.json.JSONObject |
06 | import kafka.javaapi.producer.Producer |
07 | import kafka.producer.KeyedMessage |
08 | import kafka.producer.KeyedMessage |
09 | import kafka.producer.ProducerConfig |
10 | import scala.util.Random |
12 | object KafkaEventProducer { |
14 | private val users = Array( |
15 | "4A4D769EB9679C054DE81B973ED5D768", "8dfeb5aaafc027d89349ac9a20b3930f", |
16 | "011BBF43B89BFBF266C865DF0397AA71", "f2a8474bf7bd94f0aabbd4cdd2c06dcf", |
17 | "068b746ed4620d25e26055a9f804385f", "97edfc08311c70143401745a03a50706", |
18 | "d7f141563005d1b5d0d3dd30138f3f62", "c8ee90aade1671a21336c721512b817a", |
19 | "6b67c8c700427dee7552f81f3228c927", "a95f22eabc4fd4b580c011a3161a9d9d") |
21 | private val random = new Random() |
23 | private var pointer = -1 |
25 | def getUserID() : String = { |
27 | if(pointer >= users.length) { |
35 | def click() : Double = { |
43 | def main(args: Array[String]): Unit = { |
44 | val topic = "user_events" |
45 | val brokers = "10.10.4.126:9092,10.10.4.127:9092" |
46 | val props = new Properties() |
47 | props.put("metadata.broker.list", brokers) |
48 | props.put("serializer.class", "kafka.serializer.StringEncoder") |
50 | val kafkaConfig = new ProducerConfig(props) |
51 | val producer = new Producer[String, String](kafkaConfig) |
55 | val event = new JSONObject() |
57 | .put("uid", getUserID) |
58 | .put("event_time", System.currentTimeMillis.toString) |
59 | .put("os_type", "Android") |
60 | .put("click_count", click) |
63 | producer.send(new KeyedMessage[String, String](topic, event.toString)) |
64 | println("Message sent: " + event) |
通过控制上面程序最后一行的时间间隔来控制模拟写入速度。下面我们来讨论实现实时统计每个用户的点击次数,它是按照用户分组进行累加次数,逻辑比较简单,关键是在实现过程中要注意一些问题,如对象序列化等。先看实现代码,稍后我们再详细讨论,代码实现如下所示:
01 | object UserClickCountAnalytics { |
03 | def main(args: Array[String]): Unit = { |
04 | var masterUrl = "local[1]" |
05 | if (args.length > 0) { |
10 | val conf = new SparkConf().setMaster(masterUrl).setAppName("UserClickCountStat") |
11 | val ssc = new StreamingContext(conf, Seconds(5)) |
14 | val topics = Set("user_events") |
15 | val brokers = "10.10.4.126:9092,10.10.4.127:9092" |
16 | val kafkaParams = Map[String, String]( |
17 | "metadata.broker.list" -> brokers, "serializer.class" -> "kafka.serializer.StringEncoder") |
20 | val clickHashKey = "app::users::click" |
23 | val kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics) |
25 | val events = kafkaStream.flatMap(line => { |
26 | val data = JSONObject.fromObject(line._2) |
31 | val userClicks = events.map(x => (x.getString("uid"), x.getInt("click_count"))).reduceByKey(_ + _) |
32 | userClicks.foreachRDD(rdd => { |
33 | rdd.foreachPartition(partitionOfRecords => { |
34 | partitionOfRecords.foreach(pair => { |
36 | val clickCount = pair._2 |
37 | val jedis = RedisClient.pool.getResource |
39 | jedis.hincrBy(clickHashKey, uid, clickCount) |
40 | RedisClient.pool.returnResource(jedis) |
46 | ssc.awaitTermination() |
上面代码使用了Jedis客户端来操作Redis,将分组计数结果数据累加写入Redis存储,如果其他系统需要实时获取该数据,直接从Redis实时读取即可。RedisClient实现代码如下所示:
01 | object RedisClient extends Serializable { |
02 | val redisHost = "10.10.4.130" |
04 | val redisTimeout = 30000 |
05 | lazy val pool = new JedisPool(new GenericObjectPoolConfig(), redisHost, redisPort, redisTimeout) |
07 | lazy val hook = new Thread { |
09 | println("Execute hook thread: " + this) |
13 | sys.addShutdownHook(hook.run) |
























 487
487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









