









一、XML基本知识
1.什么是xml?
xml是 可扩展的标记性语言2.xml的三大作用!
1.数据存储
2.作为工程,或者模块,框架的配置文件
3.数据共享,数据传输。数据交换格式。
比如说我们要用XML文件来描述图书信息:
<?xml version="1.0" encoding="UTF-8"?>
<books> <!-- 这是xml注释 -->
<book id="SN123123413241"> <!-- book标签描述一本图书 id属性描述 的是图书 的编号 -->
<name>java编程思想</name> <!-- name标签描述 的是图书 的信息 -->
<author>华仔</author> <!-- author单词是作者的意思 ,描述图书作者 -->
<price>9.9</price> <!-- price单词是价格,描述的是图书 的价格 -->
</book>
<book id="SN12341235123"> <!-- book标签描述一本图书 id属性描述 的是图书 的编号 -->
<name>葵花宝典</name> <!-- name标签描述 的是图书 的信息 -->
<author>班长</author> <!-- author单词是作者的意思 ,描述图书作者 -->
<price>5.5</price> <!-- price单词是价格,描述的是图书 的价格 -->
</book>
</books>简单总结:XML 最主要是用来 数据描述、存储数据 和 数据共享,以及数据传输(数据交换格式)。
3、xml语法
3.1、文档声明
我们先创建一个简单XML文件,用来描述图书信息。1)创建一个xml文件
<?xml version="1.0" encoding="UTF-8"?> xml声明。
<!-- xml声明 version是版本的意思 encoding是编码 -->而且这个<?xml 要连在一起写,否则会有报错
属性
version 是版本号
encoding 是xml的文件编码
standalone="yes/no" 表示这个xml文件是否是独立的xml文件
2)图书有id属性 表示唯一 标识,书名,有作者,价格的信息
<?xml version="1.0" encoding="UTF-8"?>
<!--
<?xml version="1.0" encoding="UTF-8"?>
这是xml文件的声明,表示这里面的内容是xml文件
version属性是表示版本的意思 1.0
encoding 表示xml文件的编码
-->
<books><!-- books是xml文件的根元素 -->
<book id="SN1234132412"> <!-- book表示一个图书的信息 id属性为图书的唯一 编码 -->
<name>葵花宝典</name><!-- name属性表示书名 -->
<author>班长</author><!-- author属性表示作者 -->
<price>9.9</price><!-- price属性表示价格 -->
</book>
<book id="SN1234132412"> <!-- book表示一个图书的信息 id属性为图书的唯一 编码 -->在浏览器中可以查看到文档
3.2、xml注释
xml 和 HTML 注释 一样 : <!-- html 注释 -->
3.3、元素(标签)
1)什么是xml元素
元素是指从开始标签到结束标签的内容。
例如:<title>java编程思想</title>
元素 我们可以简单的理解为是 标签。
Element 翻译 元素
2)XML 命名规则
XML 元素必须遵循以下命名规则:
2.1)含字母、数字以及其他的字符
例如:
<book id="SN213412341"> <!-- 描述一本书 -->
<author>班导</author> <!-- 描述书的作者信息 -->
<name>java编程思想</name> <!-- 书名 -->
<price>9.9</price> <!-- 价格 -->
</book>2.2)名称不能以数字或者标点符号开始
2.3)名称不能以字符 “xml”(或者 XML、Xml)开始 (它是可以的)
2.4)名称不能包含空格
3)xml中的元素(标签)也 分成 单标签和双标签:
单标签
格式: <标签名 属性=”值” 属性=”值” ...... />
双标签
格式:< 标签名 属性=”值” 属性=”值” ......>文本数据或子标签</标签名>
3.4、xml属性
xml的标签属性和html 的标签属性是非常类似的,属性可以提供元素的额外信息在标签上可以书写属性:
一个标签上可以书写多个属性。每个属性的值可以使用 引号 引起来。
规则和标签的书写规则一致。
3.5、语法规则:
所有 XML 元素都须有关闭标签(也就是闭合)XML 标签对大小写敏感
XML 必须正确地嵌套
XML 文档必须有根元素
XML 的属性值须加引号
xml 中的特殊字符(<,>必须使用特殊字符来代替)<,>
3.6、文本区域(CDATA区)
CDATA 格式:<![CDATA[这里可以把你输入的字符原样显示,不会解析xml]]>
二、xml解析技术介绍
不管是html文件还是xml文件它们都是标记型文档,都可以使用w3c组织制定的dom技术来解析。
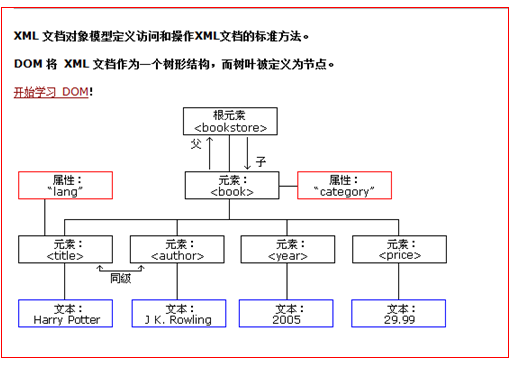
document对象表示的是整个文档(可以是html文档,也可以是xml文档)
早期JDK为我们提供了两种xml解析技术Dom和Sax简介(已经过时,但我们需要知道这么个东西)
dom解析技术是W3C组织制定的,而所有的编程语言都对这个解析技术使用了自己语言的特点进行实现。
Java对dom技术解析标记也做了实现。
早期sun公司就制定的 dom 技术。它需要把整个xml文件一下子加载到内存对象中。然后创建大量的dom内存对象,然后通过getElementById、getElementsByName 、getElementsByTagName 等方法一层一层遍历解析。
dom解析:性能和内存消耗都非常差
sun公司在JDK5版本对 dom解析技术进行升级:SAX( Simple API for XML )
SAX解析,它跟W3C制定的dom解析不太一样。它是以类似事件机制通过回调告诉用户当前正在解析的内容。
它是一行一行的读取xml文件进行解析的。不会创建大量的dom对象。
所以它在解析xml的时候,在内存的使用上。和性能上。都优于Dom解析。
第三方的解析:
jdom 在dom基础上进行了封装 、
dom4j 又对jdom 进行了封装。
pull 主要用在Android 手机开发,是在跟sax非常类似都是事件机制解析xml文件。
这个Dom4j 它是第三方的解析技术。我们需要使用第三方给我们提供好的类库才可以解析xml文件。
三、dom4j解析技术(重点*****)
由于dom4j 它不是sun公司的技术,而属于第三方公司的技术,我们需要使用dom4j 就需要到dom4j官网下载dom4j的jar包。1.Dom4j 类库的使用
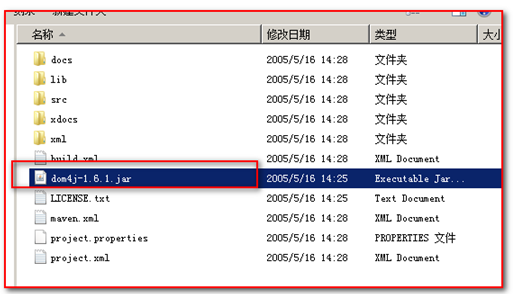
1)、把 dom4j-1.6.1.jar 类包,拷贝到工程 lib 目录下
2)、然后把jar包添加到当前的classpath路径中
dom4j 编程步骤:
1.先读取xml文件,生成document对象
2.通过Document对象获取到根标签对象
3.通过根标签对象.elements(标签名); 获取到所有的指定标签名的孩子节点集合
4.然后一层一层遍历到你要操作的元素节点进行操作。比如
a)getText() 可以获取标签中的文本
b)setText() 就可以修改标签中的文本内容
5.将修改后的document保存到硬盘中。
1.1、获取document对象
需要解析的books.xml文件内容<?xml version="1.0" encoding="UTF-8"?>
<books>
<book sn="SN12341232">
<name>辟邪剑谱</name>
<price>9.9</price>
<author>班主任</author>
</book>
<book sn="SN12341231">
<name>葵花宝典</name>
<price>99.99</price>
<author>班长</author>
</book>
</books>析获取Document对象的代码
第一步,先创建SaxReader对象。这个对象,用于读取xml文件,并创建Document
/**
* 解析xml第一步,读取xml文件生成document对象
* @throws DocumentException
*/
@Test
public void getDocument() throws DocumentException {
// 先创建一个SAXread对象读取xml文件生成document对象
SAXReader reader = new SAXReader();
Document document = reader.read("src/books.xml");
System.out.println(document);
}1.2、遍历 标签 获取所有标签中的内容(*****重点)
需要分四步操作:第一步,先读取xml文件生成document对象
第二步,通过document对象获取根元素对象
第三步,通过根元素对象.elements(标签名) 得到指定标签名的孩子元素集合
第四步,一层一层遍历获取到你想要操作的孩子节点。然后调用对象.getText()获取文本内容
/**
* 获取xml文件中所有文本内容
* @throws DocumentException
*/
@Test
public void readXML() throws DocumentException {
// 第一步,先读取xml文件生成document对象
SAXReader reader = new SAXReader();
Document document = reader.read("src/books.xml");
// 第二步,通过document对象获取根元素对象
Element rootElement = document.getRootElement();
// .asXML()方法把当前元素对象。转换成为xml的字符串
// System.out.println(rootElement.asXML());
// 第三步,通过根元素对象.elements(标签名) 得到指定标签名的孩子元素集合
List<Element> bookList = rootElement.elements("book");
// System.out.println(bookList.size());
for (Element book : bookList) {
// 第四步,一层一层遍历获取到你想要操作的孩子节点。然后调用对象.getText()获取文本内容
// 获取 当前元素中属性的值
String snValue = book.attributeValue("sn");
// System.out.println(snValue);
// 通过book标签对象.element(标签名) 获取指定标签名的孩子元素
Element nameElement = book.element("name");
// .getText()获取 元素中的文本内容
String nameText = nameElement.getText();
// System.out.println(nameText);
// System.out.println(nameElement.asXML());
// elementText(标签名)可以直接获取指定标签名的孩子元素的文本内容
String priceText = book.elementText("price");
// System.out.println(priceText);
// 获取author元素的文本内容
String authorText = book.elementText("author");
// 把获取 的xml的文本内容转换成为bean对象
Book bookBean = new Book(snValue, nameText, Double.valueOf(priceText), authorText);
System.out.println(bookBean);
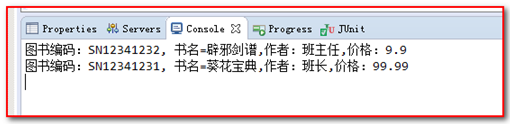
// System.out.println("图书编码:" + snValue + ", 书名="
// + nameText + ",作者:" + authorText + ",价格:" + priceText);
}
}打印内容 :
1.3、增加元素和属性
需求:给班长添加一个<girl boyfriend=”班长”>凤姐</girl>元素。/**
* 第二本图书的后面添加<girl boyfriend=”班长”>凤姐</girl>元素
*
* @throws DocumentException
* @throws IOException
*/
@Test
public void addXML() throws DocumentException, IOException {
// 第一步,先读取xml文件生成document对象
SAXReader reader = new SAXReader();
Document document = reader.read("src/books.xml");
// 第二步,通过document.getRootElement()获取到根元素对象
Element rootElement = document.getRootElement();
// 第三步,通过根元素对象.elements("book").get(1)获取到第二个book元素对象
Element secondBook = (Element) rootElement.elements("book").get(1);
// System.out.println(secondBook.asXML());
// 第四步,通过book元素对象.addElement(标签名); 创建标签对象
Element girlElement = secondBook.addElement("girl"); // 在第二个book中添加<girl></girl>
// 第五步,给新创建的girl标签设置文本内容和添加属性
girlElement.setText("凤姐");
girlElement.addAttribute("boyfriend", "班长");
// System.out.println(document.asXML());
// 第六步,保存修改好的xml内容到硬盘文件中
// 第一种将document保存到硬盘文件的方法
// FileWriter out = new FileWriter("foo.xml");
// document.write(out);
// out.close();
// 第二种输出的方法。使用dom4j提交好的xmlWriter来实现输出
// XMLWriter writer = new XMLWriter(new FileWriter("output.xml"));
// writer.write(document);
// writer.close();
// 第三种将document保存到硬盘的方法
//它会先将xml文件格式化后输出到硬盘中
// OutputFormat prettyFormat = OutputFormat.createPrettyPrint();
// XMLWriter writer2 = new XMLWriter(new FileWriter("output2.xml"), prettyFormat);
// writer2.write(document);
// writer2.close();
// 第四种将document保存到硬盘的方法
// 它会将xml文件中无用的空格和换行去掉
// 第四种方法常用于格式后进行网络的输出
OutputFormat compactFormat = OutputFormat.createCompactFormat();
XMLWriter writer3 = new XMLWriter(new FileWriter("output3.xml"), compactFormat);
writer3.write(document);
writer3.close();
}2、XPath快速搜索技术
XPath其他是一种表达式快速搜索的技术。
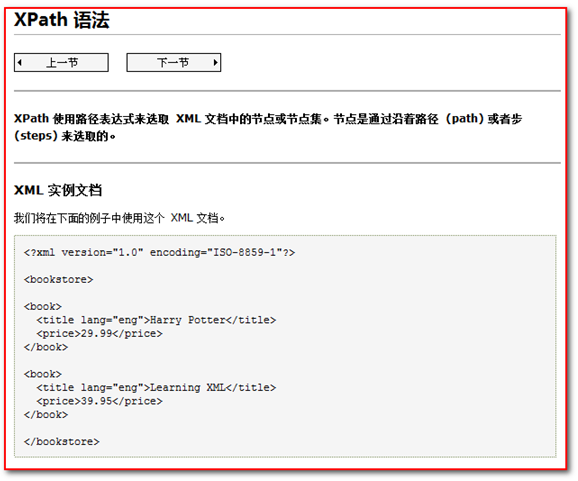
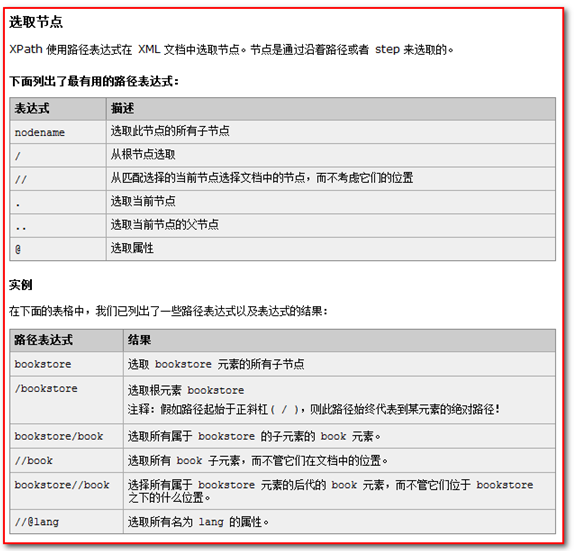
XPath 练习:
需求1. 获取books下的所有book标签 /books/book
需求2. 获取根标签下的books元素下的book元素,且这个book元素拥有sn属性,且值为SN12341231。下的name元素
需求3. 获取根标签下的books元素下的第一个book元素 /books/book[1]
@Test
public void xPathTest() throws DocumentException {
// XPath 练习:
// 需求1. 获取books下的所有book标签
// 需求2. 获取根标签下的books元素下的book元素,且这个book元素拥有abc属性,且值为true。下的name元素
// 需求3. 获取根标签下的books元素下的第一个book元素
Document document = Dom4jUtils.getDocument("src/books.xml");
// 需求1. 获取books下的所有book标签
// /books/book
List<Node> nodes = document.selectNodes("/books/book");
System.out.println(nodes.size());
// 需求3. 获取根标签下的books元素下的第一个book元素
// /books/book[1] //这个xPath的的下标从1开始
Node bookNode = document.selectSingleNode("/books/book[1]");
System.out.println(bookNode.asXML());
// 需求2. 获取根标签下的books元素下的book元素,且这个book元素拥有abc属性,且值为true。下的name元素
// /books/book[@abc='true']/name
Node nameNode = document.selectSingleNode("/books/book[@abc='true']/name");
System.out.println(nameNode.asXML());
}XPath 第三方类库的依赖lib 包,没有找到,报错。找需要的类库,导入项目
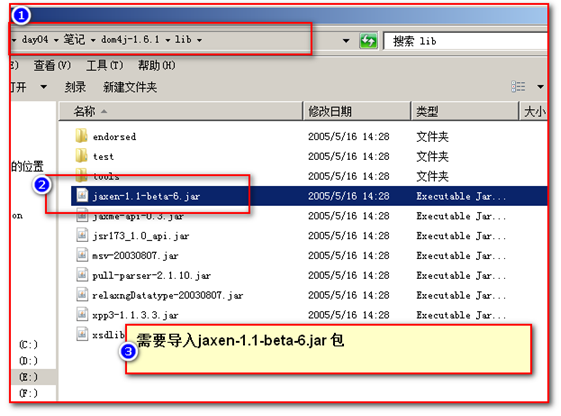
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









