







首先表示抱歉,年底大家都懂的,又涉及SupportYun系统V1.0上线。故而第四篇文章来的有点晚了些~~~对关注的朋友说声sorry!
SupportYun系统当前一览:
首先说一下,文章的进度一直是延后于系统开发进度的。
当前系统V1.0 已经正式上线服役了,这就给大家欣赏几个主要界面~~
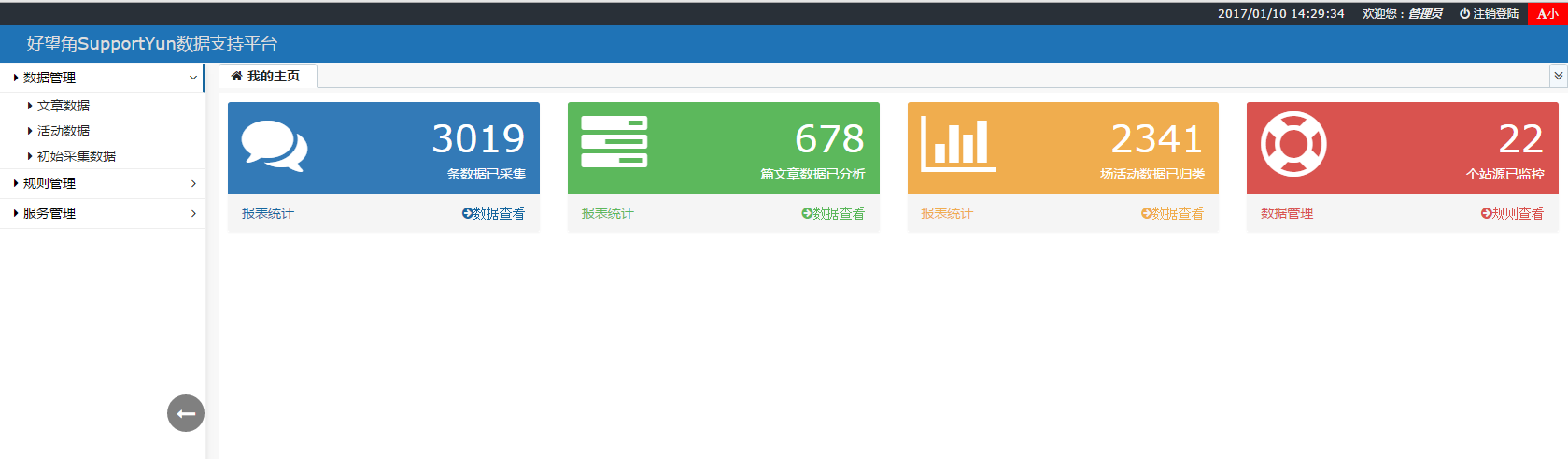
哈哈~这是系统主页,极简风格。主体框架使用的是 B-JUI ,偶然间看到的一个开源框架,相信它的作者会把它做得越来越好!

这是数据列表的功能页面,大家对这个table应该非常熟悉哈,我使用的是easyUI的datagrid,没办法谁叫他简单便捷呢~~
再给大家秀一秀V1.1版本正在开发的一个界面:【搜一搜】
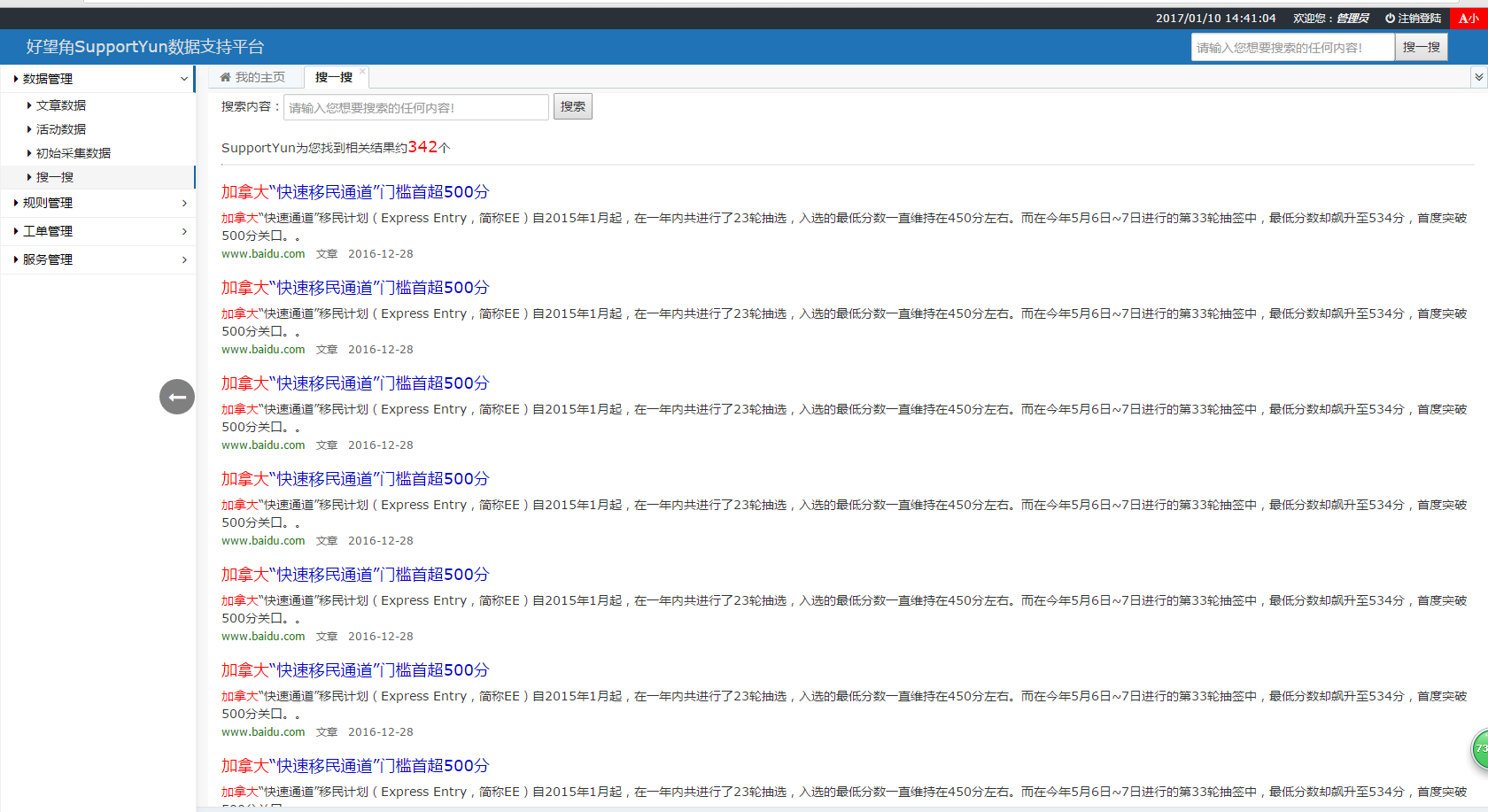
嘿嘿~有木有一种百度搜索结果的既视感...没办法,谁叫俺是个程序员呢,也设计不出来啥好样式,只有照着百度自己拼凑了一个!
技术只是解决问题的选择,而不是解决问题的根本。
爬取微信公众号方案:
不知道为什么,这个系统做着做着我身上就又多了一个使命:爬取微信文章。
谁叫咱是拿钱干活,而不是拿钱吩咐人干活的呢!哎~还非得作为紧急任务添加到了即将上线的V1.0版本,哭>>>>>
“工欲善其事,必先利其器!”
“说人话!”
“我先百度一下怎么做~~~”
所以啊,程序员最离不开的还是万能的搜索引擎。借助几个小时在搜索引擎看的相关帖子、博客、文章等等内容,我也大致总结了一下网友们提到的可以实现的方案:
1.微信API获取 ——想想都是醉了,肿么可能...
2.抓取微信历史文章页面 ——据说每个微信公众号都有一个固定地址的历史文章页面,嗯,我看行...
3.通过搜狗搜索微信,抓取结果列表 ——啊哦,这不就成了抓网页了么,我的系统有现成的方案啊...
4.使用类似新榜这样的内容网站平台 ——本质和搜狗应该想差不大...
5.能搜到很多各式各样的抓取软件,看介绍是有类似功能的,不过不是要钱就是要各种币,故我也没做尝试...
嗯,刀磨锋利了,该选几棵树试试效果了。
以博主这几个小时摄取的知识来看,第3/4两条,通过搜狗、新榜来爬取它们的网页比较靠谱,也和SupportYun当前系统相符(本来咱就是一个单纯的网站爬取系统)。至于第二条,爬历史文章,这个由于BOSS的关注点更在于能抓取到最新的文章,而不是大量的历史文章,故而放弃尝试。
我到底该学什么?------别问,学就对了;
我到底该怎么做?------别问,做就对了。
初尝搜狗搜索,抓取微信公众号文章:
打开搜狗搜索,我们可以看到,搜索微信文章分两种模式:搜文章、搜公众号
先来看搜文章:

根据搜索结果,我们发现,这相当于内容搜索,结果不局限于任何公众号。由于博主的BOSS要求的是爬取指定的一堆微信公众号的最新文章...所以,放弃搜文章。不过大家要是有其他需求,还是可以通过这个方案来构建url抓取数据的。
我们再来看搜公众号是个什么鬼:
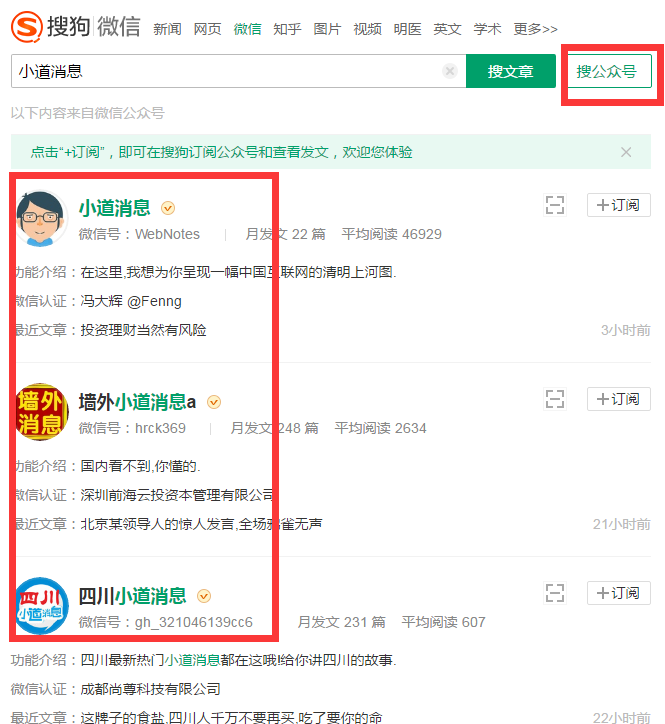
OK,我们点击某一个公众号进去看看。额~~~居然让输入验证码。好万恶!
进去后我们发现是直接到了微信的列表页,观察url,有过时的风险。以小道消息的url为例:
http://mp.weixin.qq.com/profile?src=3×tamp=1484034436&ver=1&signature=5ANAj3eXwUD5KImAqpqhfnnzIx49V9*lzIc-MKxq21VwMoq51PCrd2NxcOqQPbt35Zg5SrRXDB418Rj48HCV5Q==
在url中看见timestamp=1484034436这种带有时间戳的参数,一般都会存在过期问题,博主多次尝试对该url的时间戳进行替换,发现signature参数的值应该是与时间戳有所关联,故而很难自己重新构建url。
假如我们先忽略掉验证码与列表url过期问题,毕竟我们还有搜索文章那一条路,是不存在这两个问题的。那么我们看到的就是一个标准的列表页面:

抓取这种页面是SupportYun系统的强项,具体代码大家可以看第二篇文章:
记一次企业级爬虫系统升级改造(二):基于AngleSharp实现的抓取服务
注:此处详情页的url也是会过时的,经过博主试验,我们只需要在url后面统
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5280
5280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









