







 本文详细介绍了malloc和free函数的工作原理,包括它们如何管理和扩展进程的堆空间,以及虚拟地址到物理地址的映射机制。
本文详细介绍了malloc和free函数的工作原理,包括它们如何管理和扩展进程的堆空间,以及虚拟地址到物理地址的映射机制。
本文介绍malloc的实现及其malloc在进行堆扩展操作,并分析了虚拟地址到物理地址是如何实现映射关系。
ordeder原创,原文链接: http://blog.csdn.net/ordeder/article/details/41654509
1背景知识
1.1 进程的用户空间
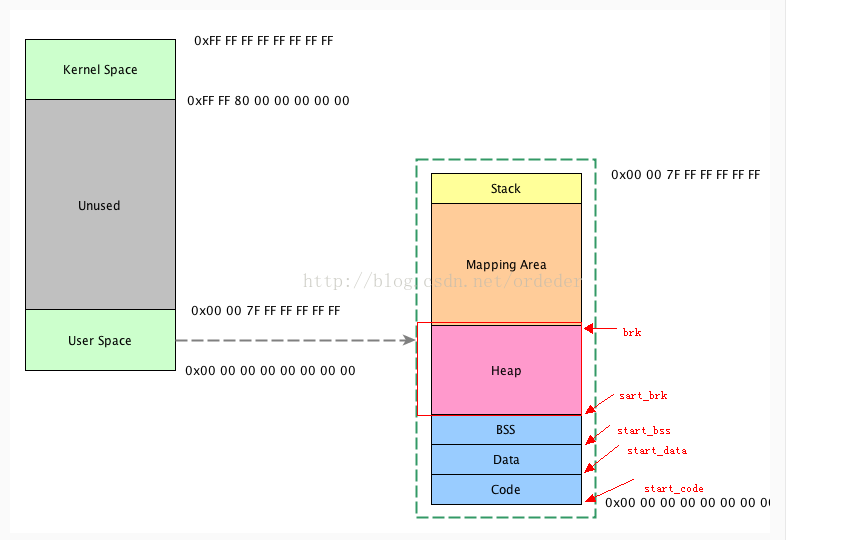
图1:来源 http://www.open-open.com/lib/view/open1409716051963.html
该结构是由进程task_struct.mm_struct进行管理的mm_struct的定义如下:
struct mm_struct {
struct vm_area_struct * mmap; /* list of VMAs */
...
pgd_t * pgd; //用于地址映射
atomic_t mm_users; /* How many users with user space? */
atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
int map_count; /* number of VMAs */
...
//描述用户空间的段分布:数据段,代码段,堆栈段
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long rss, total_vm, locked_vm;
...
};结构中的startxxx与endxxx描述了进程用户空间数据段的所在地址。对于堆空间而言,start_brk是堆空间的起始地址,堆是向上扩展的。对于进程堆空间的扩展,brk来记录堆的顶部位置。而进程动态申请的空间的已经使用到的地址空间(正在使用的变量)是被映射的,这些地址空间记录于链表struct vm_area_struct * mmap中。
1.2 地址映射
虚拟地址和物理地址的映射 : http://blog.csdn.net/ordeder/article/details/41630945
2 malloc 和free
malloc用于用户空间堆扩展的函数接口。该函数是C库,属于封装了相关系统调用(brk())的glibc库函数。而不是系统调用(系统可没有sys_malloc()。如果谈及malloc函数涉及的系统内核的那些操作,那么总体可以分为用户空间层面和内核空间层面来讨论。
2.1 用户层
malloc 的源码可见 http://repo.or.cz/w/glibc.git/blob/HEAD:/malloc/malloc.c
Malloc和free是在用户层工作的,该接口为用户提供一个比较方便管理堆的接口。它的主要工作是维护一个空闲的堆空间缓冲区链表。该缓冲区可以用如下数据结构表述:
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
简化版的空闲缓冲区链表如下所示,图中head即为上述的malloc_chunk结构。而紧接着的size大小的内存区间是该chunk对应的数据区。
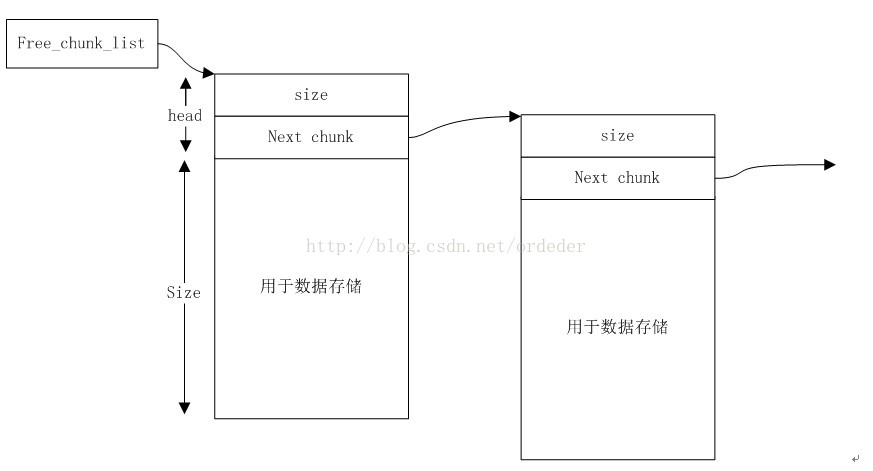
【malloc】
每当进程调用malloc,首先会在该堆缓冲区寻找足够大小的内存块分配给进程(选择缓冲区中的那个块就有首次命中和最佳命中两种算法)。如果freechunklist已无法满足需求的chunk时,那么malloc会通过调用系统调用brk()将进程空间的堆进行扩展,在新扩展的堆空间上建立一个新的chunk并加入到freelist中,这个过程相当于进程批量想系统申请一块内存(大小可能比实际需求大得多)。
malloc返回的地址是chunk的中用于存储数据的首地址,即: chunk + sizeof(chunk)
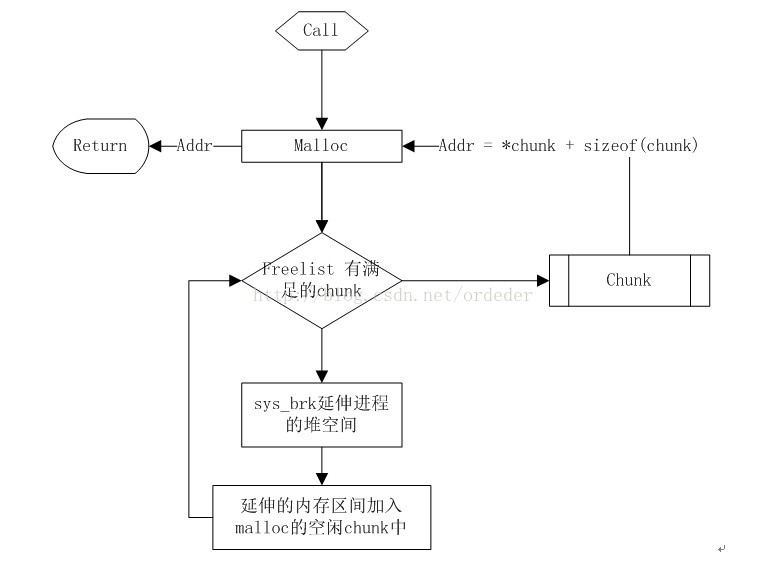
一个简单的首次命中malloc的伪代码:
chunk free_list
malloc(size)
foreach(chuck in freelist)
if(chunk.size >size)
return chunk + sizeof(chunk)
//空闲缓冲区无法满足需求,那么像系统批发内存
add = sys_brk(brk+(size +sizeof(chunk)))
newchunk = (chunk)add;
newchunk.size = size;
...
return newchunk + sizeof(newchunk)
【free】
free操作是对堆空间的回收,回收的区块并不是立即返还给内核。而是将区块对应的chunk“标记”为空闲,加入空闲队列中。当然,如果空闲队列中出现相邻地址的chunk,那么可以考虑合并,已解决内存的碎片化,一遍满足之后的大内存申请的需求。
free(add)
pchunk = add - sizeof(chunk)
insert_to_freelist(pchunk)2.2 内核层
上文中,malloc的空闲chunk列表无法满足用户的需求,那么要通过sys_brk()进行堆的扩展,这时候才真正算得上进入内核空间。sys_brk()涉及的主要操作有:
1. 在mm_struct中的堆上界brk延伸到newbrk:即申请一块vma,vma.start=brk vma.end=newbrk
2. 为该虚拟区间块进行物理内存的映射:从虚拟空间vma.start~vma.end中的每个内存页进行映射:
addr = vma.start
do{
handle_mm_fault(mm,vma,addr,...)
addr += PAGESIZE
}while(addr< vma.end)函数handle_mm_fault为addr所在的内存页映射物理页面。实现虚拟空间到物理空间的换算和映射。
1.通过alloc_page申请一个物理页面;
2.换算addr在进程pdg映射中所在的pte地址;
3.将addr对应的pte设置为物理页面的首地址。
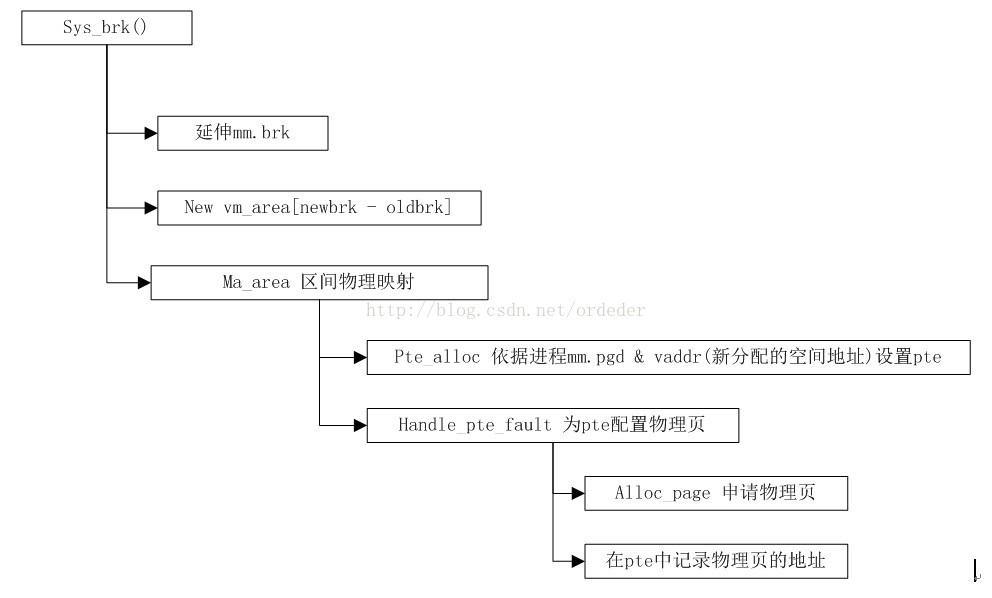
2.3 虚拟地址与物理地址
当进程读取堆空间的地址vaddr时,虚拟地址vaddr到物理页面的映射如下图所示。
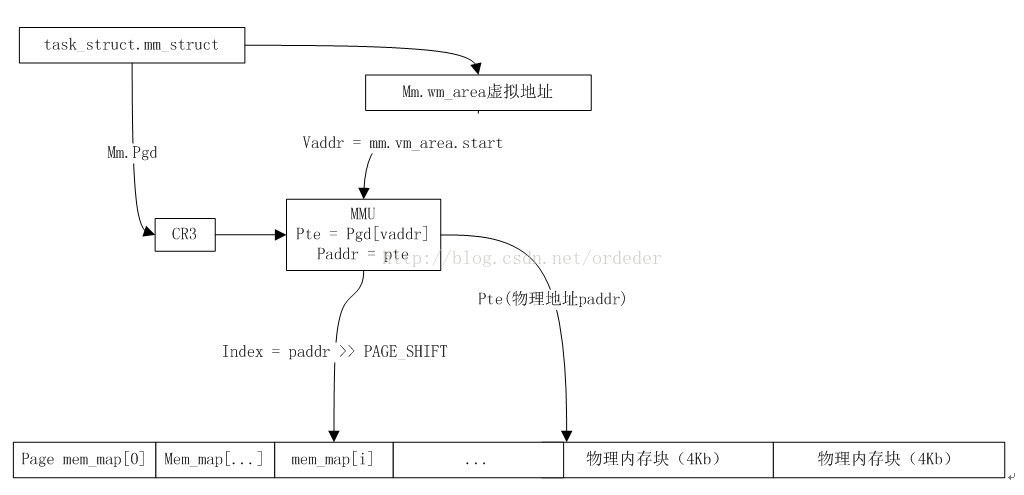
1. 用户空间的虚拟地址vaddr通过MMU(pgd,pmd,pte)找到对应的页表项pte记录的物理地址paddr
2. 页表项paddr的高20位是物理页号:index = x >> PAGE_SHIFT,同理,index后面补上12个0就是物理页表的首地址。
3. 通过物理页号,我们可以再内核中找到该物理页的描述的指针mem_map[index]。Page结构可以参考http://blog.csdn.net/ordeder/article/details/41630945。
3 总结
1 Malloc 和 free 怎么看着就是个用户空间的内存池。特别free的实现。
2 堆的扩展依据brk的移动。Vm_area记录了虚拟空间中已使用的地址块。
3 每个进程的虚拟地址到物理地址的映射是有进程mm.pgd决定的,在该结构中记录了虚拟页号到物理页号的映射关系。
参考
内核源码情景分析
http://blog.csdn.net/kobbee9/article/details/7397010
http://www.open-open.com/lib/view/open1409716051963.html
附录
#define pgd_offset(mm, address) ((mm)->pgd + pgd_index(address))
int handle_mm_fault(struct mm_struct *mm, struct vm_area_struct * vma,
unsigned long address, int write_access)
{
int ret = -1;
pgd_t *pgd;
pmd_t *pmd;
pgd = pgd_offset(mm, address);
pmd = pmd_alloc(pgd, address);
if (pmd) {
pte_t * pte = pte_alloc(pmd, address); //pmd是空的,所以返回的是pgd[address]的pte项目
if (pte)
ret = handle_pte_fault(mm, vma, address, write_access, pte);
}
return ret;
}
//32位地址,pmd没有意义
extern inline pmd_t * pmd_alloc(pgd_t * pgd, unsigned long address)
{
return (pmd_t *) pgd;
}
//为address地址所在的页构建pte索引项
extern inline pte_t *pte_alloc(pmd_t *pmd, unsigned long address)
{
address = (address >> PAGE_SHIFT) & (PTRS_PER_PTE - 1);
if (pmd_none(*pmd)) {
pte_t *page = get_pte_fast();
if (!page)
return get_pte_slow(pmd, address);
pmd_set(pmd,page);
return page + address;
}
if (pmd_bad(*pmd)) {
__bad_pte(pmd);
return NULL;
}
return (pte_t *)__pmd_page(*pmd) + address;
}
//为address对应的页面分配物理页面
static inline int handle_pte_fault(struct mm_struct *mm,
struct vm_area_struct * vma, unsigned long address,
int write_access, pte_t * pte)
{
pte_t entry;
entry = *pte;
if (!pte_present(entry)) {
...
if (pte_none(entry))
return do_no_page(mm, vma, address, write_access, pte);//缺页,分配物理页
...
}
...
return 1;
}
static int do_no_page(struct mm_struct * mm, struct vm_area_struct * vma,
unsigned long address, int write_access, pte_t *page_table)
{
struct page * new_page;
pte_t entry;
//匿名(对于虚拟存储空间而言)的物理映射
if (!vma->vm_ops || !vma->vm_ops->nopage)
return do_anonymous_page(mm, vma, page_table, write_access, address);
//一下是文件的缺页处理,在此不表
...
}
//通过page指针,即可计算page的物理地址: 物理地址 = (page指针 - mem_map)* 页大小 + 物理内存起始地址
/*
* 匿名映射,用于虚存到物理内存
*/
static int do_anonymous_page(struct mm_struct * mm, struct vm_area_struct * vma, pte_t *page_table, int write_access, unsigned long addr)
{
struct page *page = NULL;
pte_t entry = pte_wrprotect(mk_pte(ZERO_PAGE(addr), vma->vm_page_prot));
if (write_access) {
page = alloc_page(GFP_HIGHUSER); //从高端内存中分配内存
if (!page)
return -1;
clear_user_highpage(page, addr);
entry = pte_mkwrite(pte_mkdirty(mk_pte(page, vma->vm_page_prot)));
mm->rss++;
flush_page_to_ram(page);
}
set_pte(page_table, entry); // *page_table = entry;
/* No need to invalidate - it was non-present before */
update_mmu_cache(vma, addr, entry);
return 1; /* Minor fault */
}
#define __MEMORY_START CONFIG_MEMORY_START //物理内存中用于动态分配使用的起始地址
void flush_page_to_ram(struct page *pg)
{
unsigned long phys;
/* Physical address of this page */
phys = (pg - mem_map)*PAGE_SIZE + __MEMORY_START;
__flush_page_to_ram(phys_to_virt(phys));
}
#define __virt_to_phys(vpage) ((vpage) - PAGE_OFFSET + PHYS_OFFSET)
#define __phys_to_virt(ppage) ((ppage) + PAGE_OFFSET - PHYS_OFFSET)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









