









本篇博文将介绍 Scrapy 爬取 CSDN 博文详情页并写入文件,这里以 http://blog.csdn.net/oscer2016/article/details/78007472 这篇博文为例:
1. 先执行以下几个命令:
scrapy startproject csdnblog
cd csdnblog/
scrapy genspider -t basic spider_csdnblog csdn.net2. 编写 settings.py :
设置用户代理,解除 ITEM_PIPELINES 注释,用户代理可在审查元素中查看:
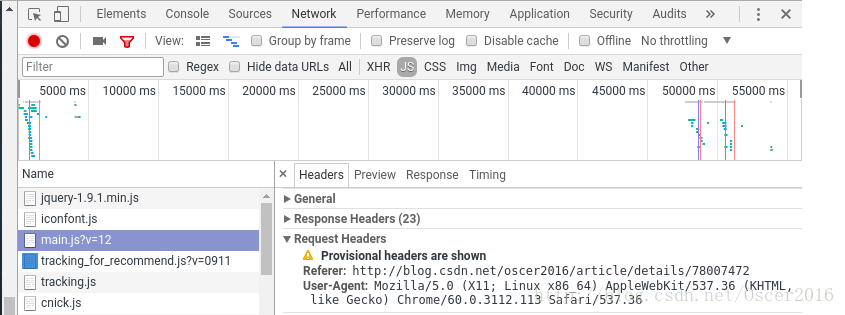
# 修改以下两处
vim csdnblog/settings.pyUSER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
ITEM_PIPELINES = {
'csdnblog.pipelines.CsdnblogPipeline': 300,
}
3. 编写要抽取的数据域 (items.py) :
vim csdnblog/items.py # -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class CsdnblogItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
url = scrapy.Field()
releaseTime = scrapy.Field()
readnum = scrapy.Field()
article = scrapy.Field()4. 编写 piplines.py:
vim csdnblog/pipelines.py# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
import re
class CsdnblogPipeline(object):
def process_item(self, item, spider):
data = re.findall("http://blog.csdn.net/(.*?)/article/details/(\d*)", item['url'])
# 构造文件名
filename = data[0][0] + '_' + data[0][1] + '.txt'
text = "标题: " + item['title'] + "\n博文链接: " + item['url'] + "\n发布时间: " \
+ item['releaseTime'] + "\n\n正文: " + item['article']
fp = open(filename, 'w')
fp.write(text)
fp.close()
return item
5. 编写爬虫代码:
vim csdnblog/spiders/spider_csdnblog.py# -*- coding: utf-8 -*-
import scrapy
import re
from scrapy import Request
from csdnblog.items import CsdnblogItem
class SpiderCsdnblogSpider(scrapy.Spider):
name = 'spider_csdnblog'
allowed_domains = ['csdn.net']
start_urls = ['http://blog.csdn.net/oscer2016/article/details/78007472']
def parse(self, response):
item = CsdnblogItem()
# 新版主题博客数据抽取
item['url'] = response.url
item['title'] = response.xpath('//h1[@class="csdn_top"]/text()').extract()[0].encode('utf-8')
item['releaseTime'] = response.xpath('//span[@class="time"]/text()').extract()[0].encode('utf-8')
item['readnum'] = response.xpath('//button[@class="btn-noborder"]/span/text()').extract()[0]
data = response.xpath('//div[@class="markdown_views"]')
item['article'] = data.xpath('string(.)').extract()[0]
# 将数据传入pipelines.py,然后写入文件
yield item
6. 运行项目:
scrapy crawl spider_csdnblog --nolog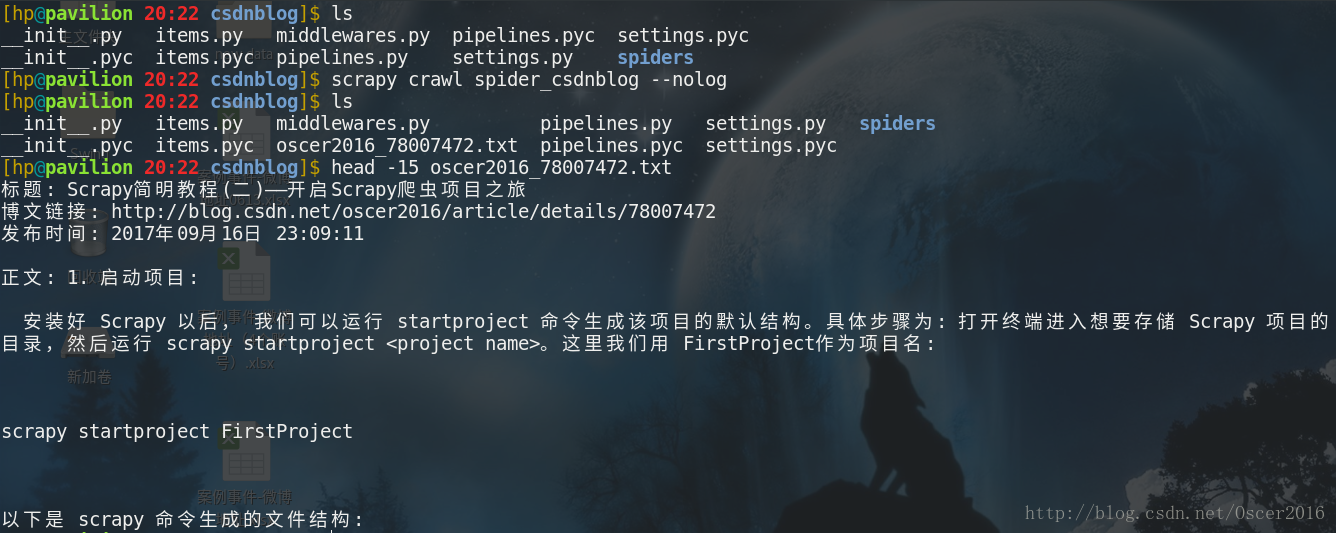
至此,博文相关数据已正确抽取并存入文件,下一篇博客将介绍爬取 CSDN 全部博客专家的所有博文并存入 MongoDB。














 430
430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









