









Android消息处理机制深度解析笔记
前言
很多程序猿(媛)都对消息处理机制做过分析,大家都基本了解了MessageQueue、Handler、Looper之间相互之间怎么协同工作,但是具体到消息是如何传递,取出,如何处理的过程并不是那么清晰,本人曾经也是如此。为了拿下这个城池,特此写下此文深入分析其中的每一处是如何工作。
一、概述
Android的应用程序是通过消息机制来驱动的,深入理解Android应用程序的消息机制就显得尤为重要,这个消息处理机制主要是围绕消息队列来实现的。
在Android应用程序中,可以在一个线程启动时在内部创建一个消息队列,然后再进入到一个无限循环的模式之中,不断地检查这个消息队列是否有新的消息需要进行处理。如果需要处理,那么该线程就会从这个消息队列中取出消息从而进行处理,如果没有消息需要处理,则线程处于等待状态。
在整个消息机制处理过程中会涉及到几个类,如ThreadLocal、Looper、Message、MessageQueue、Handler。
二、相关类的原理分析
在分析消息机制的实现原理之前先熟悉一下相关类的原理。
(1)ThreadLocal实现原理
为了在一个线程中都有自己的共享变量,JDK中提供了ThreadLocal这个类。ThreadLocal是一个线程内部存储数据的泛型类,可以类比喻全局存放数据的盒子,盒子里可以存储每个线程的私有数据。
使用场景:
1、变量的作用域只限定在线程中。
2、在一些复杂逻辑的情况下需要传递对象,例如监听器的传递。
首先以一个例程来说明使用ThreadLocal,线程之间存储的数据的作用域只限定在线程以内。
public class ThreadLocalTest {
private static ThreadLocal<Boolean> mThreadLocal = new ThreadLocal<>();
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
mThreadLocal.set(false);
System.out.println(Thread.currentThread().getName() + " value: " + mThreadLocal.get());
}
}, "Thread--1").start();
new Thread(new Runnable() {
@Override
public void run() {
mThreadLocal.set(true);
System.out.println(Thread.currentThread().getName() + " value: " + mThreadLocal.get());
}
}, "Thread--2").start();
new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " value: " + mThreadLocal.get());
}
}, "Thread--3").start();
}
}运行的结果是:
Thread–1 value: false
Thread–2 value: true
Thread–3 value: null
由结果可以说明各线程之间存储的值是相互不影响,下面深入ThreadLocal源代码来分析ThreadLocal内部是如何实现的。
先关注一下set()方法
public void set(T value) {
Thread currentThread = Thread.currentThread();
Values values = values(currentThread);
if (values == null) {
values = initializeValues(currentThread);
}
values.put(this, value);
}在set()方法中,首先获取调用该方法的线程对象,而values()方法主要是获取Thread中的localValues对象值,如果这个对象为null,则使用initializeValues()方法来初始化Thread中的localValues值。初始化values值之后,将value值保存到该线程中的localValues值中(values.put(this, value)方法)。在此处已经很明了,每一个线程保存的值其实都是保存到对应线程内部的Values中,即localValues对象中。
而Values又是什么鬼?调用put()方法又是如何保存对象数据的呢?
Values是ThreadLocal中的一个静态内部类,ThreadLocal的值主要是存储到Values中的table数组中。
在创建Values对象时,构造函数会初始化table数组的大小,源代码中的长度大小为16,因为是需要存储键值对,因为初始化的时候扩展了其大小为32,所以这里的长度大小必须为偶数。
下面看下put()方法:
void put(ThreadLocal<?> key, Object value) {
cleanUp();
// Keep track of first tombstone. That's where we want to go back
// and add an entry if necessary.
int firstTombstone = -1;
for (int index = key.hash & mask;; index = next(index)) {
Object k = table[index];
if (k == key.reference) {
// Replace existing entry.
table[index + 1] = value;
return;
}
if (k == null) {
if (firstTombstone == -1) {
// Fill in null slot.
table[index] = key.reference;
table[index + 1] = value;
size++;
return;
}
// Go back and replace first tombstone.
table[firstTombstone] = key.reference;
table[firstTombstone + 1] = value;
tombstones--;
size++;
return;
}
// Remember first tombstone.
if (firstTombstone == -1 && k == TOMBSTONE) {
firstTombstone = index;
}
}
}存储过程中将ThreadLocal值存储在table[index]下,而对应的value值存储在下一个table[index + 1]值中,这样就形成了键值键值…的存储规律。
分析完set()方法后,我们再来看ThreadLocal的get()方法是如何实现的?
public T get() {
// Optimized for the fast path.
Thread currentThread = Thread.currentThread();
Values values = values(currentThread);
if (values != null) {
Object[] table = values.table;
int index = hash & values.mask;
if (this.reference == table[index]) {
return (T) table[index + 1];
}
} else {
values = initializeValues(currentThread);
}
return (T) values.getAfterMiss(this);
}获取当前线程的localValues值(即为values),如果values值不为null,取出Values之中的table数组,在数组中找出ThreadLocal对应存储的数据,返回其类型转换后的值;如果values值为null,则初始化values值,之后调用 (T) values.getAfterMiss(this);在此不详细介绍该方法,主要是返回null。这也对应了之前例程第三个线程没有对ThreadLocal设值后打印出来的值是null不谋而合了。
以上的set()和get()方法中所操作的对象都是当前线程对象中的localValues数组,而数组中保存了ThreadLocal对象以及存储的数据。
(2)Looper实现原理
Looper在Android消息机制里的作用就要是创建消息队列,并不断的从消息队列中查看是否有消息需要处理,有消息则取出给Handler来处理,没有消息则一直处于阻塞状态。在Looper中有两个特别重要的静态方法,一个是prepare(),另一个是loop()。
1、先看prepare()方法,这个方法主要是创建Looper对象。
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}前面分析过ThreadLocal,sThreadLocal就是一个存储Looper的ThreadLocal对象,如果在sThreadLocal中没有取到Looper对象,那么就会新创建一个Looper对象,并且会将这个对象存储到sThreadLocal对象中去。
下面看下Looper的构造函数是怎样实现的。
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}在构造函数中,创建了一个新的消息队列mQueue,并且获取了当前线程的对象。
pepare()是一般线程所使用的方法,而在Android英语程序的主线程(UI线程)中要创建Looper对象,则会使用prepareMainLooper()方法。
public static void prepareMainLooper() {
prepare(false);
synchronized (Looper.class) {
if (sMainLooper != null) {
throw new IllegalStateException("The main Looper has already been prepared.");
}
sMainLooper = myLooper();
}
}因为这个线程一直存在,那么整个消息处理机制(其中的消息队列不能退出)都需要伴随整个线程周期,那么在初始化的时候prepare()方法中传入的参数是false。在初始化Looper对象后,再对Looper对象中的属性sMainLooper赋值,这里是从sThreadLocal中取出的值。
2、创建Looper对象之后,接着就是需要对所创建的消息队列进行循环,那么就需要启动循环操作,调用Looper.loop()方法就能启动消息循环了。下面分析loop()方法的实现原:
public static void loop() {
final Looper me = myLooper();
if (me == null) {
throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread.");
}
final MessageQueue queue = me.mQueue;
// Make sure the identity of this thread is that of the local process,
// and keep track of what that identity token actually is.
Binder.clearCallingIdentity();
final long ident = Binder.clearCallingIdentity();
for (;;) {
Message msg = queue.next(); // might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
// This must be in a local variable, in case a UI event sets the logger
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
// Make sure that during the course of dispatching the
// identity of the thread wasn't corrupted.
final long newIdent = Binder.clearCallingIdentity();
if (ident != newIdent) {
Log.wtf(TAG, "Thread identity changed from 0x"+ Long.toHexString(ident) + " to 0x" + Long.toHexString(newIdent) + " while dispatching to " + msg.target.getClass().getName() + " " + msg.callback + " what=" + msg.what);
}
msg.recycleUnchecked();
}
}首先获取Looper对象,这里是从sThreadLocal获取的,对应的线程存放了自己内部的Looper对象。如果获取的Looper对象为null,则不会执行后续消息循环操作,如果不为空,则可以获取到looper对象中的消息队列,之前已经说明消息队列是在Looper的构造函数中初始化的,那么在此就可以获取到了mQueue。for是一个无限循环的操作,在调用MessageQueue的next方法,其作用是从消息队列中取出消息,在源码中有注释在此处可能会阻住,具体实现原理将在下一节中说明。如果消息队列中没有消息则退出循环操作。此循环中的核心代码msg.target.dispatchMessage(msg),target是一个Handler对象,这个对象就是发送消息的那个Handler对象,handler对象分发消息,在handler的dispatchMessage方法中会执行内部的处理消息的方法handleMessage()。消息分发完之后recycleUnchecked()执行消息的回收工作,将消息存入回收的消息池当中。
整个消息的循环,处理分析过程也在此告一段落。
Google团队在设计Looper的时候还考虑到了如果不使用Looper时,可以选择退出的方法,这里有两种方式:一种是直接调用quite()方法退出;另一种是调用quiteSafely()方法等待消息处理完成后安全退出。
为什么这样设计,因为刚才我们在分析循环那一部分时,在消息队列中取消息时会一直会处于阻住(该线程就会一直处于等待状态)。这里都是调用了消息队列中的方法,在后续分析MessageQueue的章节中会详细分析其实现原理。
(3)Message实现原理
Android应用程序是事件驱动的,每个事件都会转化成一个可以序列化的系统消息。而这个消息(Message)中包含了两个额外的整型数据字段和一个额外的对象字段。Message是一个可序列化的对象,what是Message的标识,如果需要存储的数据是int型的,那么可以存储到arg1,arg2,而需要存储序列化的对象时,可将数据存储到一个Bundle对象(data)中。
在创建一个Message对象时,有两种方式:一种是new Message(),另外一种是Message.obtain()方法。虽然消息的构造函数是公共的,但最好的方法是调用Message.obtain()或Handler.obtainMessage()方法,从对象池中获取。
下面主要分析第二种创建Message对象的方式:
obtain()方法采用了享元模式,这样便于更少的创建Message对象,减少内存的开销。
public static Message obtain() {
synchronized (sPoolSync) {
if (sPool != null) {
Message m = sPool;
sPool = m.next;
m.next = null;
m.flags = 0; // clear in-use flag
sPoolSize--;
return m;
}
}
return new Message();
}sPoolSync是一个同步对象锁,进入同步方法后,sPool是一个共享对象池,如果sPool为null,则会直接创建一个Message对象。如果sPool不为null,则会从回收的对象池中获取消息对象,而对象池重新赋值为m.next。如果之前对象池的next不为null,则为为对应的值,否则为null,如果为null,则对象池的值就为null。而当前消息对象的next为赋值为null,并将当前消息对象标志flag为未使用,消息池中的长度减少1。其实这里的整个过程就是从对象池中将一个Message中取出,脱离对象池。
Message链表如下图所示:

下面分析如果从对象池中获取一个Message对象,上图是一个消息池,将m赋值为sPool,之后将消息池重新赋值为m.next,此时的消息池为下图所示。
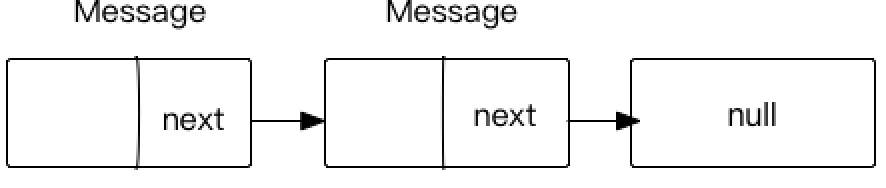
那么第一个Message就脱离sPool了,但是它的next值是一个链表,从而后面继续对m.next赋值为null,这样就将Message对象从对象池中完全取出来了,而消息池sPool的长度确实减少了一个长度值。
其他的obtain方法,只是将传入的参数赋值到Message对象所对应的属性对象。
下面分析recycle()方法。
public void recycle() {
if (isInUse()) {
if (gCheckRecycle) {
throw new IllegalStateException("This message cannot be recycled because it " + "is still in use.");
}
return;
}
recycleUnchecked();
}当Message调用回收的方法时,首先会判断该Message是否在使用,
/*package*/ boolean isInUse() {
return ((flags & FLAG_IN_USE) == FLAG_IN_USE);
}当flag值为1,就表示该消息在使用中,那么不会执行回收的后续操作。否则就执行recycleUnchecked方法。
void recycleUnchecked() {
// Mark the message as in use while it remains in the recycled object pool.
// Clear out all other details.
flags = FLAG_IN_USE;
what = 0;
arg1 = 0;
arg2 = 0;
obj = null;
replyTo = null;
sendingUid = -1;
when = 0;
target = null;
callback = null;
data = null;
synchronized (sPoolSync) {
if (sPoolSize < MAX_POOL_SIZE) {
next = sPool;
sPool = this;
sPoolSize++;
}
}
}在回收过程中,依然认为该message在使用,所以flag标志为1,但是其它的属性值都赋值为初始值。在同步方法锁内的代码块,如果当前消息池的长度小于池的最大长度时,则可以将该回收的消息存到消息池中。next 赋值为之前的消息池,而现在的消息池对象指向当前消息,从而将当前消息链接到消息链表的首部中。
关于Message中的序列化的方法,以及toString方法就不一一介绍了。
(4)MessageQueue实现原理
Android应用程序的消息机制都是围绕着消息队列来展开工作的,那么掌握好MessageQueue的实现原理就显得尤为重要了。MessageQueue内部的消息存储的数据结构是采用的单链表形式,而不是队列。因为添加消息时,处理消息可以设定相应的时间,那么就需要对添加的消息进行排序,而单链表的插入和删除的开销时间为线性关系,也比较适合这个场景。在MessageQueue中比较重要的两个方法是,enqueueMessage()插入消息,next()取出消息并在消息队列中删除。
之前我们在分析Looper时已经知道在调用Looper.prepare()方法时创建了消息队列,在MessageQueue构造方法里,初始化了是否允许消息队列退出的标志,另外还初始化了一个C++层的NativeMessageQueue对象,并且mPtr值就是该对象的地址值。
在NativeMessageQueue中源代码的构造函数如下
NativeMessageQueue::NativeMessageQueue() :
mPollEnv(NULL), mPollObj(NULL), mExceptionObj(NULL) {
mLooper = Looper::getForThread();
if (mLooper == NULL) {
mLooper = new Looper(false);
Looper::setForThread(mLooper);
}
}在初始化NativeMessageQueue时会创建C++层的mLooper对象,getForThread()判断当前线程是否创建mLooper的对象,如果没有创建则会创建mLooper对象,创建后的对象会通过setForThread()方法来关联当前线程,后续实现通过管道来处理,我们这不再进一步分析,这个可参考《Android源代码情景分析》一书。
下面分析插入和取出(删除)消息的方法。
1、插入操作
boolean enqueueMessage(Message msg, long when) {
if (msg.target == null) {
throw new IllegalArgumentException("Message must have a target.");
}
if (msg.isInUse()) {
throw new IllegalStateException(msg + " This message is already in use.");
}
synchronized (this) {
if (mQuitting) {
IllegalStateException e = new IllegalStateException(
msg.target + " sending message to a Handler on a dead thread");
Log.w(TAG, e.getMessage(), e);
msg.recycle();
return false;
}
msg.markInUse();
msg.when = when;
Message p = mMessages;
boolean needWake;
if (p == null || when == 0 || when < p.when) {
// New head, wake up the event queue if blocked.
msg.next = p;
mMessages = msg;
needWake = mBlocked;
} else {
// Inserted within the middle of the queue. Usually we don't have to wake
// up the event queue unless there is a barrier at the head of the queue
// and the message is the earliest asynchronous message in the queue.
needWake = mBlocked && p.target == null && msg.isAsynchronous();
Message prev;
for (;;) {
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
if (needWake && p.isAsynchronous()) {
needWake = false;
}
}
msg.next = p; // invariant: p == prev.next
prev.next = msg;
}
// We can assume mPtr != 0 because mQuitting is false.
if (needWake) {
nativeWake(mPtr);
}
}
return true;
}在Handler所有发送消息的方法最终都会调用enqueueMessage()方法,而在调用消息队列的enqueueMessage()之前会先对Message的target赋值为当前发送消息的Handler对象。在插入的消息中没有携带Handler对象的,则不会插入到消息队列中。如果这个消息正在使用中,那么也不会重复插入到该消息队列中。
MessageQueue中有一个比较重要的成员变量mMessages,这个变量表示当前线程需要处理的消息。将mMessages赋值给变量p,条件p == null || when == 0 || when < p.when表达了三种情况,第一种:当前消息队列没有需要处理的消息;第二种:插入处理消息的时间为0;第三种:插入的消息处理的时间小于当前需要处理消息的处理时间。这三种情况都是需要优先将该插入的消息插入到单链表的首部。该插入的消息的next值为当前需要处理的消息,next值可能为null,不为null的时候则是一个单链表,插入的消息会加入到该链表中去。第四种情况:插入的消息的处理时间大于等于当前需要处理的消息的处理时间,那么插入的消息还没那么快需要处理,因而需要插入到链表中的合适位置,这个链表是按照处理时间从小到大的顺序来排列的。后续else中代码主要是将插入的消息插入到指定位置的算法处理,关于消息的插入实现原理基本就是这样。
2、取出消息
Message next() {
// Return here if the message loop has already quit and been disposed.
// This can happen if the application tries to restart a looper after quit
// which is not supported.
final long ptr = mPtr;
if (ptr == 0) {
return null;
}
int pendingIdleHandlerCount = -1; // -1 only during first iteration
int nextPollTimeoutMillis = 0;
for (;;) {
if (nextPollTimeoutMillis != 0)
Binder.flushPendingCommands();
}
nativePollOnce(ptr, nextPollTimeoutMillis);
synchronized (this) {
// Try to retrieve the next message. Return if found.
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
Message msg = mMessages;
if (msg != null && msg.target == null) {
// Stalled by a barrier. Find the next asynchronous message in the queue.
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
if (msg != null) {
if (now < msg.when) {
// Next message is not ready. Set a timeout to wake up when it is ready.
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
// Got a message.
mBlocked = false;
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
if (DEBUG) Log.v(TAG, "Returning message: " + msg);
msg.markInUse();
return msg;
}
} else {
// No more messages.
nextPollTimeoutMillis = -1;
}
// Process the quit message now that all pending messages have been handled.
if (mQuitting) {
dispose();
return null;
}
// If first time idle, then get the number of idlers to run.
// Idle handles only run if the queue is empty or if the first message
// in the queue (possibly a barrier) is due to be handled in the future.
if (pendingIdleHandlerCount < 0 && (mMessages == null || now < mMessages.when)) {
pendingIdleHandlerCount = mIdleHandlers.size();
}
if (pendingIdleHandlerCount <= 0) {
// No idle handlers to run. Loop and wait some more.
mBlocked = true;
continue;
}
if (mPendingIdleHandlers == null) {
mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)];
}
mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers);
}
// Run the idle handlers.
// We only ever reach this code block during the first iteration.
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null; // release the reference to the handler
boolean keep = false;
try {
keep = idler.queueIdle();
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
// Reset the idle handler count to 0 so we do not run them again.
pendingIdleHandlerCount = 0;
// While calling an idle handler, a new message could have been delivered
// so go back and look again for a pending message without waiting.
nextPollTimeoutMillis = 0;
}
}在Looper中的loop()方法中会循环消息队列中的消息,那么就会调用next()方法从消息队列中取出消息来处理。在next()中的同步代码块中主要是对消息队列的处理,将符合条件的消息取出,这里考虑到了消息可能未携带Handler的情况,也有消息处理的时间还没到的情况就会计算取出消息的时间,前置消息为null和不为null的情况,这些情况都会将消息取出。
之前在loop()方法中说到会阻住,那是什么时候开始阻住的,这里在同步代码块中又一个参数pendingIdleHandlerCount,当它的值小于等于0时就会标志mBlocked为true,这里会执行continue操作,会继续下一次循环操作,如果依然没有消息需要处理则重复这样的操作,从而达到阻住的效果。
(5)Handler实现原理
Handler的工作主要是发送消息和处理消息,前面已经简要说明了消息是如何发送的。这里再详细分析一下,Handler发送消息的方式有很多种,但是最终都是通过调用sendMessageAtTime()方法来实现的。
public boolean sendMessageAtTime(Message msg, long uptimeMillis) {
MessageQueue queue = mQueue;
if (queue == null) {
RuntimeException e = new RuntimeException(this + " sendMessageAtTime() called with no mQueue");
Log.w("Looper", e.getMessage(), e);
return false;
}
return enqueueMessage(queue, msg, uptimeMillis);
}queue的值为在创建Handler对象时创建的消息队列mQueue,如果queue为null,则发送消息失败,当不为null时,则会调用enqueueMessage()方法。
private boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) {
msg.target = this;
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis);
}msg.target = this是将Handler对象与message关联起来,再调用Looper创建的消息队列中的queue.enqueueMessage()方法,则会将消息插入到消息队列。
当消息发送到消息队列,消息队列中有需要处理的消息,则Looper通过loop()方法从消息队列中取出需要处理的消息。之前分析了处理消息时,与消息关联的Handler对象调用dispatchMessage()方法,将消息分发给Handler来处理。
public void dispatchMessage(Message msg) {
if (msg.callback != null) {
handleCallback(msg);
} else {
if (mCallback != null) {
if (mCallback.handleMessage(msg)) {
return;
}
}
handleMessage(msg);
}
}此处的分发处理方式受创建Handler对象和插入消息方式的影响。
如果使用的是post系列方法发送消息,那么会传入一个Runable对象,该对象会通过getPostMessage()方法与Message关联,那么在分发消息时就会执行handleCallback()方法,
private static void handleCallback(Message message) {
message.callback.run();
}从而执行Runable对象中的run()方法。
如果使用的是在创建Handler对象时传入了CallBack回调,那么会执行mCallback.handleMessage()方法。
如果不是以上两种情况,则直接使用Handler中的handleMessage()方法来处理消息。而以上处理消息的业务逻辑就是程序员自己需要实现的。
三、原理分析
上节独立分析了涉及到的每一个类的工作原理,这节将整体分析一下消息机制的工作原理。
Android的消息处理机制主要是围绕消息队列来实现的,在一个线程中通过调用Looper.prepare()方法来创建消息队列和Looper对象,在该线程中创建能发送和处理消息的Handler对象,而Handler通过Looper对象来关联消息队列。Handler发送消息到与之关联的消息队列(MessageQueue对象),通过MessageQueue对象的enqueueMessage的方法将消息插入到消息队列当中。而在发送的消息中,又将Handler与消息建立对应关系,每一个消息中的target就是发送消息的Handler对象。而Looper对象又通过loop方法不断的循环消息,取出需要处理的消息,通过消息中关联的Handler对象分发消息(dispatchMessage)给对应的Handler来处理消息。
四、运用场景
消息处理机制在Android应用程序中是比较重要的一个知识点,也是运用比较广泛的一个知识点,在Android源码中主要由分个场景来使用,第一个是应用程序主线程的应用;第二个是与UI有关的子线程的应用;第三个是与UI无关的子线程的应用。
(1)应用程序主线程的应用
Android应用程序的主线程是以ActivityThread静态函数main()为入口。
public static void main(String[] args) {
...
Looper.prepareMainLooper();
ActivityThread thread = new ActivityThread();
thread.attach(false);
if (sMainThreadHandler == null) {
sMainThreadHandler = thread.getHandler();
}
if (false) {
Looper.myLooper().setMessageLogging(new LogPrinter(Log.DEBUG, "ActivityThread"));
}
// End of event ActivityThreadMain.
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
Looper.loop();
throw new RuntimeException("Main thread loop unexpectedly exited");
}这里调用Looper中的prepareMainLooper()方法来创建Looper和MessageQueue,而主线程中的Handler对象是ActivityThread中的H,这里主要是处理四大组件相关的处理消息。
(2)与UI有关的子线程的应用
在Android应用程序开发中使用过AsyncTask,其中就使用了消息机制,在内部创建了一个InternalHandler(Handler)对象,而调用的Looper是UI主线的Looper,代码如下:
private static class InternalHandler extends Handler {
public InternalHandler() {
super(Looper.getMainLooper());
}
@SuppressWarnings({"unchecked", "RawUseOfParameterizedType"})
@Override
public void handleMessage(Message msg) {
AsyncTaskResult<?> result = (AsyncTaskResult<?>) msg.obj;
switch (msg.what) {
case MESSAGE_POST_RESULT:
// There is only one result
result.mTask.finish(result.mData[0]);
break;
case MESSAGE_POST_PROGRESS:
result.mTask.onProgressUpdate(result.mData);
break;
}
}
}当在子线程处理完耗时任务之后,通过InternalHandler发送消息到主线程中的消息队列当中,当主线程中的Looper进入循环取出该消息则把消息分发给InternalHandler来处理,从而达到刷新UI的作用。
(3)与UI无关的子线程的应用
在Android应用程序框架层设计了一个HandlerThread类,在run方法中执行了Looper的prepare()和loop()方法。
下面介绍一下如何在这种场景下使用。
首先创建HandlerThread对象,
HandlerThread handlerThread = new HandlerThread(“yishon test”);
为了在handlerThread中创建Looper和MessageQueue对象,则需启动该线程。
handlerThread.start();
我们可以利用Handler的post方法来发送一个消息,那么
Handler handler = new Handler(handlerThread.getLooper());
handler.post(new Runable {
public void run() {
//需要实现的业务操作
}
});五、相关结论
(1)不能在同一个线程中多次调用prepare()方法,否则会出现运行时异常。
(2)在同一个线程中可以初始化多个Handler对象,这些对象都可以发送消息将消息插入到同一个消息队列中。
(3)如果Handler发送两个消息需要处理的时间是相同的,则先发送者先处理。















 5570
5570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











