







核心内容
1、spark的概念
2、spark与mapreduce的比较
3、spark中RDD的相关概念
4、spark shell的使用
一、Spark的相关概念
Spark的概念:Spark是分布式的、主要基于内存的、特别适合于迭代计算的大数据计算框架。
接下来从3个方面去理解Spark的概念:
分布式:所谓分布式就是有很多台机器在运行,每个机器运行任务中的一部分,提高了任务运行的效率。
主要基于内存: Spark在计算的过程中会优先将数据放在内存中,如果内存容量不足的话,Spark也会将数据放在磁盘上或者部分数据放在磁盘上进行计算,即Spark不仅可以计算内存中放的下的数据,一定也可以计算内存中放不下的数据,Spark适合各种规模的分布式数据的计算。
注意:在整个数据的计算过程中,我们肯定是希望数据是在内存中的,我们甚至不希望数据是在本地磁盘上的,当然也不希望数据是通过网络从其他机器上抓取过来的,本质上Spark优先考虑将数据放在内存中,
实际上是对计算机物理资源的最大化利用。所以对于Spark的运行会耗费内存的观点肯定是错误的。
Hadoop每次计算数据的时候都要读写磁盘,而Spark优先考虑基于内存,也就是说每次Spark计算的结果优先考虑放在内存中,下一次计算直接基于上次内存中计算的结果,这是Spark可以高速运行的主要原因之一
迭代式计算:迭代式计算是Spark真正的精髓所在。
Hadoop的MapReduce与Spark最大的不同在于迭代模型,Spark在处理完一个阶段之后,处理的结果可以继续在其他节点上进行下一个阶段的计算,还可以有很多的阶段,不仅仅只有map和reduce两个阶段,
由于这种迭代式的特点,导致Spark更加灵活,也更加强大。
接下来讲一下Spark处理数据的来源与数据输出之后的去向:
处理数据来源:HDFS、Hbase、Hive、DB
处理数据输出:HDFS、HBase、Hive、DB,S3,HANA、Cassandra或直接将结果返还给客户端。
谈一下Spark处理数据的3个优势:
Spark是对于海量数据的快速通用引擎。它的优势如下:
(1) 快
Spark运行快的原因一是因为运行过程中将中间结果存入内存,二是因为Spark运行前会将运行过程生成一张DAG图(有向无环图),当处理的源数据在文件中时,比Hadoop快10倍,当处理的源数据在内存中时,
比Hadoop快100倍。
(2) 通用
可以使用Core/SQL/Streaming/Graphx/MLib/R/StructStreaming(2.0)等进行Spark计算。
处理的数据通用:可以处理HDFS/Hive/HBase/ES、JSON/JDBC等数据
Spark运行模式:Spark可以运行在本地模式、集群模式,集群模式时,可以运行在YARN上、Mesos上、Standalone集群上、云端
(3) 使用简单
可以使用Python、Scala、Java等开发。
Spark和Hadoop的比较

三、Spark中RDD的相关概念
1、 定义
RDD是弹性分布式数据集(Resilient Distributed Dataset)的简称,其实就是分布式元素集合。在Spark中,对数据的所有操作不外乎创建RDD、转化已有的RDD、调用RDD操作进行求值。
RDD是Spark提出的最重要的核心抽象,Spark整个的编程、任务调度、容错和性能优化等等都是基于RDD之上的。
RDD是弹性分布式数据集,同理向Spark一样,我们也从3个方面去介绍RDD:
弹性:RDD的弹性体现在4个方面:
①:RDD会自动的进行内存和磁盘中数据的存储的切换;
②:基于Lineage的高效容错(例如如果第n个步骤出错,RDD会从第n-1个步骤恢复,血统容错),提高了错误恢复的步骤,不需要一切从头开始;
③:Task如果失败会自动进行特定次数的重试(默认4次);
④:Stage(计算阶段)如果失败会自动进行特定次数的重试(可以只运行计算失败的阶段),只计算失败的数据分片,默认3次。
分布式:
所谓分布式就是RDD本身代表一系列的数据分片,这些分片会被放在Spark集群中的不同机器的计算节点上。然而RDD对于用户来说是透明的,也就是说用户根本就不用关心RDD对应的一些列的数据分片究竟放在哪里,用户只要对RDD进行计算处理就可以了。
数据集:
RDD本身代表要处理的数据集,一个RDD其本身在逻辑上抽象的代表了底层的一个文件或文件夹。
2、操作类型
RDD有两种类型的操作:Transformation操作、Action操作,Transformation操作和Action操作区别在于Spark计算RDD的方式不同。
1、Transformation操作会由一个RDD生成另一个新的RDD,生成的新的RDD是惰性求值的,只有在Action操作时才会被计算。
2、Action操作会对RDD计算出一个结果,并把结果返回到驱动器程序中,或者是把结果存储到外部存储系统中。
3、RDD会做缓存的几个情况:(如果都做缓存和Hadoop就没有什么区别了)
①、计算步骤特别耗时
②、计算链条很长
③、Shuffle之后,Shuffle需要从其他机器上面抓取数据
④、CheckPoint之前
最后在补充几句,RDD是通过Spark Context的形式进行创建的,Spark Context是集群的唯一接口,即我们做的一切工作都基于Spark context的;我们的RDD在逻辑上代表了HDFS上面具体的文件,但是实际上RDD底层是不同的分片,这些分片散落在集群中不同的机器上面;Spark中的一个分区的大小默认和一个block的大小的是相同的;NODE_LOCAL是本地磁盘上面,Process_Local是在内存中。
四、Spark中shell的使用
先谈一下Spark处理数据的三个步骤:
1、读取数据:
读取数据一般是从HDFS上读取数,如sc.textfile(‘/user/input’)
对于Spark Core来说,将数据变为RDD;对于Spark Sql来说,是将数据变为DataFrame;对于Streaming来说,将数据变为DStream。
2、处理数据:
对于Spark Core来说,调用RDD的一系列方法;对于Spark Sql来说,是调用df的一系列方法;对于Streaming来说,是调用dstream一系列方法。这些方法大部分是高阶函数,使用各种方法来在内存中处理数据。
3、输出数据:输出数据也大部分是存入硬盘,
sc.SaveAsTextFile()
resultDF.write.jdbc()
resultDStream.foreach(Redis\HBase)。
接下来我们以WordCount程序为例进行具体说明:
[root@SZB-L0032014 bin]# ./spark-shell --master spark://SZB-L0032014:7077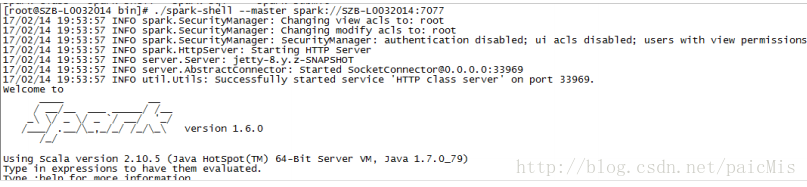
val data = sc.textFile("/word/wordcount") val flatted = data.flatMap(_.split(" ")) val mapped = flatted.map(word => (word,1)) val reduced = mapped.reduceByKey(_+_) reduced.saveAsTextFile("/word/output")接下来我们查一下运行结果:
[root@SZB-L0032017 ~]# hadoop fs -cat /word/wordcount
hello you
spark hadoop
java scala
java hello
[root@SZB-L0032017 ~]# hadoop fs -lsr /word/output
lsr: DEPRECATED: Please use 'ls -R' instead.
-rw-r--r-- 3 root root 0 2017-02-14 20:02 /word/output/_SUCCESS
-rw-r--r-- 3 root root 29 2017-02-14 20:02 /word/output/part-00000
-rw-r--r-- 3 root root 29 2017-02-14 20:02 /word/output/part-00001
You have new mail in /var/spool/mail/root
[root@SZB-L0032017 ~]# hadoop fs -cat /word/output/part-00000
(scala,1)
(hello,2)
(java,2)
[root@SZB-L0032017 ~]# hadoop fs -cat /word/output/part-00001
(spark,1)
(you,1)
(hadoop,1)从运行结果上来看结果是正确的。
接下来我们查看一下在程序运行过程中产生的RDD:
scala> data.toDebugString
res4: String =
(2) MapPartitionsRDD[1] at textFile at <console>:27 []
| /word/wordcount HadoopRDD[0] at textFile at <console>:27 []
scala> flatted.toDebugString
res5: String =
(2) MapPartitionsRDD[2] at flatMap at <console>:29 []
| MapPartitionsRDD[1] at textFile at <console>:27 []
| /word/wordcount HadoopRDD[0] at textFile at <console>:27 []
scala> mapped.toDebugString
res6: String =
(2) MapPartitionsRDD[3] at map at <console>:31 []
| MapPartitionsRDD[2] at flatMap at <console>:29 []
| MapPartitionsRDD[1] at textFile at <console>:27 []
| /word/wordcount HadoopRDD[0] at textFile at <console>:27 []
scala> reduced.toDebugString
res7: String =
(2) ShuffledRDD[4] at reduceByKey at <console>:33 []
+-(2) MapPartitionsRDD[3] at map at <console>:31 []
| MapPartitionsRDD[2] at flatMap at <console>:29 []
| MapPartitionsRDD[1] at textFile at <console>:27 []
| /word/wordcount HadoopRDD[0] at textFile at <console>:27 从运行结果可以看出,RDD之间是有依赖关系的。
之前我们讲到RDD本身代表要处理的数据集,但是实际上RDD底层是不同的分片,这些分片散落在集群中不同的机器上面,但是如何证明这些分片分布在不同的机器之上?
我们查看一下程序运行记录:
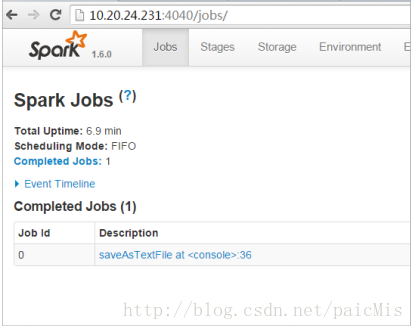
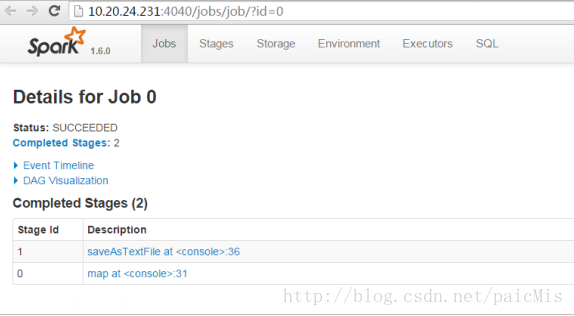
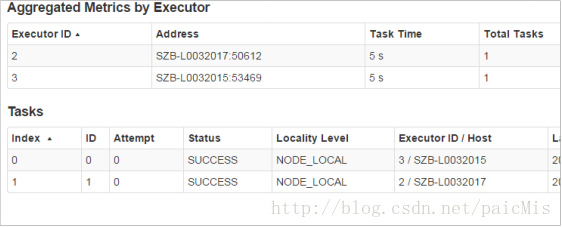














 5812
5812











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









