







目前 Spark 编译脚本已经将Maven 集成进来了,以方便编译以及部署。这个脚本将会在它本地 build/ 编译目录自动下载和安装所有编译过程中所必需的( Maven,Scala 和 Zinc )。可以手动修改dev/make-distribution.sh脚本,使其选择自己安装好的Maven,如果不修改这个脚本会自动安装所需要的编译环境。确保编译的机器能正常访问外网,建议在测试环境编译,生产上对网络做各种限制,即便开通了代理也还会报各种诡异在错误。
参考官方文档:http://spark.apache.org/docs/latest/building-spark.html
一、 Spark-2.1.0 编译环境准备
1、 安装并配置好Maven(本次编译使用apache maven 3.5.0)
2、 安装并配置JDK(本次编译使用jdk1.8.0_77)
3、 安装并配置Scala(本次使用scala-2.11.8)
下载spark源码 spark-2.1.0.tgz-->http://spark.apache.org/downloads.html
二、编译过程
1、编译:mvn -Pyarn -Dhadoop.version=2.6.0-cdh5.7.0 -Phive -Phive-thriftserver -DskipTests clean package
(1)在/home/hadoop/spark-2.1.0/pom.xml文件添加编译所需的cloudera软件包依赖
<repository>
<id>cloudera-repo</id>
<name>Cloudera Repository</name>
<url>https://repository.cloudera.com/artifactory/cloudera-repos</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<profile>
<id>cdh5.7.0</id>
<properties>
<hadoop.version>2.6.0-cdh5.7.0</hadoop.version>
<hbase.version>1.2.4-cdh5.7.0</hbase.version>
<zookeeper.version>3.4.5-cdh5.7.0</zookeeper.version>
</properties>
</profile>(2) 设置MAVEN的JVM参数,根据实际情况调整:exportMAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"
(3)开始编译:mvn -Pyarn -Dhadoop.version=2.6.0-cdh5.7.0 -Phive -Phive-thriftserver -DskipTests clean package
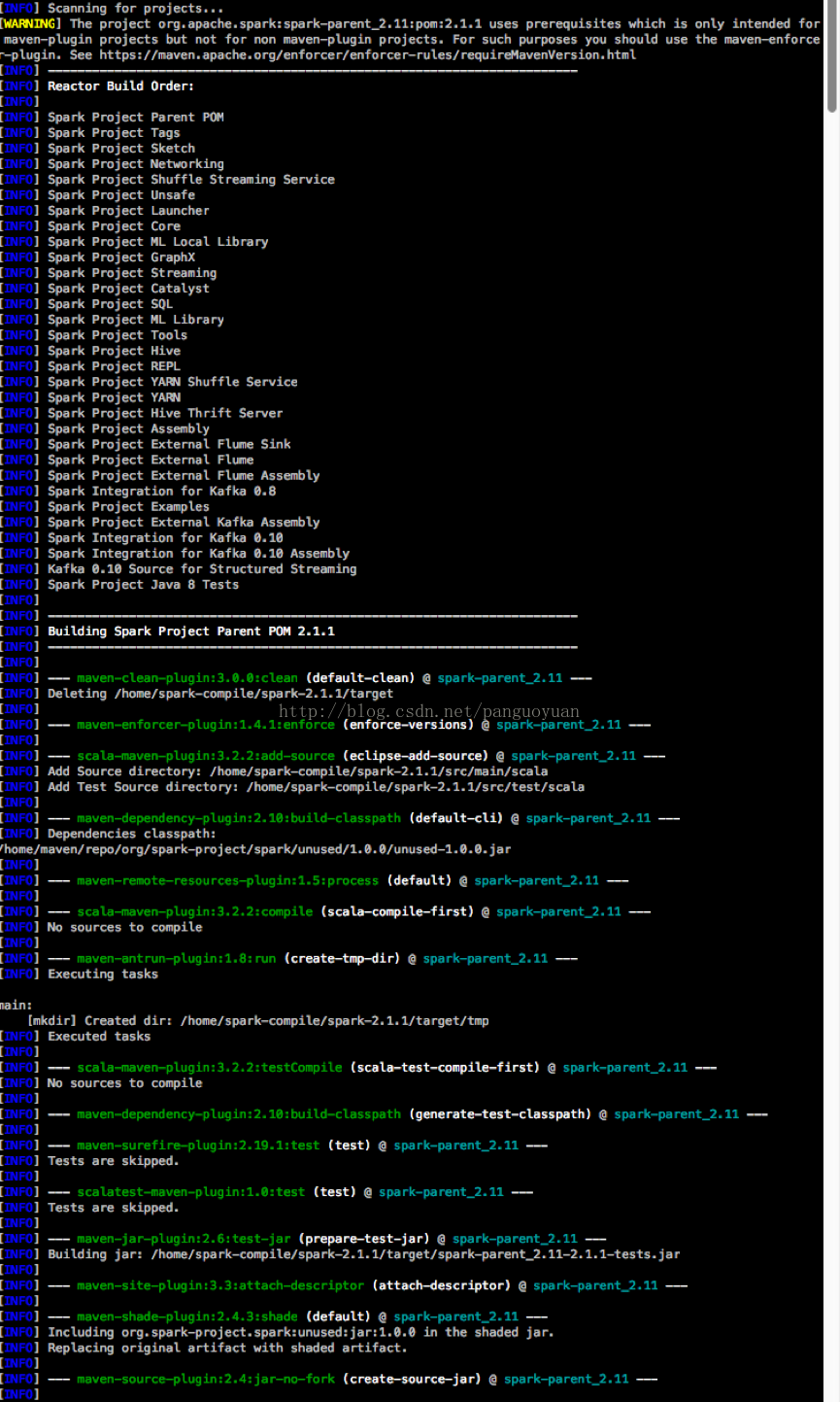
可能报的错误1.
[ERROR] Failed to execute goalnet.alchim31.maven:scala-maven-plugin:3.2.2:compile (scala-compile-first) onproject spark-core_2.11: Execution scala-compile-first of goalnet.alchim31.maven:scala-maven-plugin:3.2.2:compile failed. CompileFailed ->[Help 1]
org.apache.maven.lifecycle.LifecycleExecutionException: Failedto execute goal net.alchim31.maven:scala-maven-plugin:3.2.2:compile(scala-compile-first) on project spark-core_2.11: Execution scala-compile-firstof goal net.alchim31.maven:scala-maven-plugin:3.2.2:compile failed.
解决:查看一下是否还有sbt或zinc在运行,有的话kill掉再继续
可能遇到的错误2
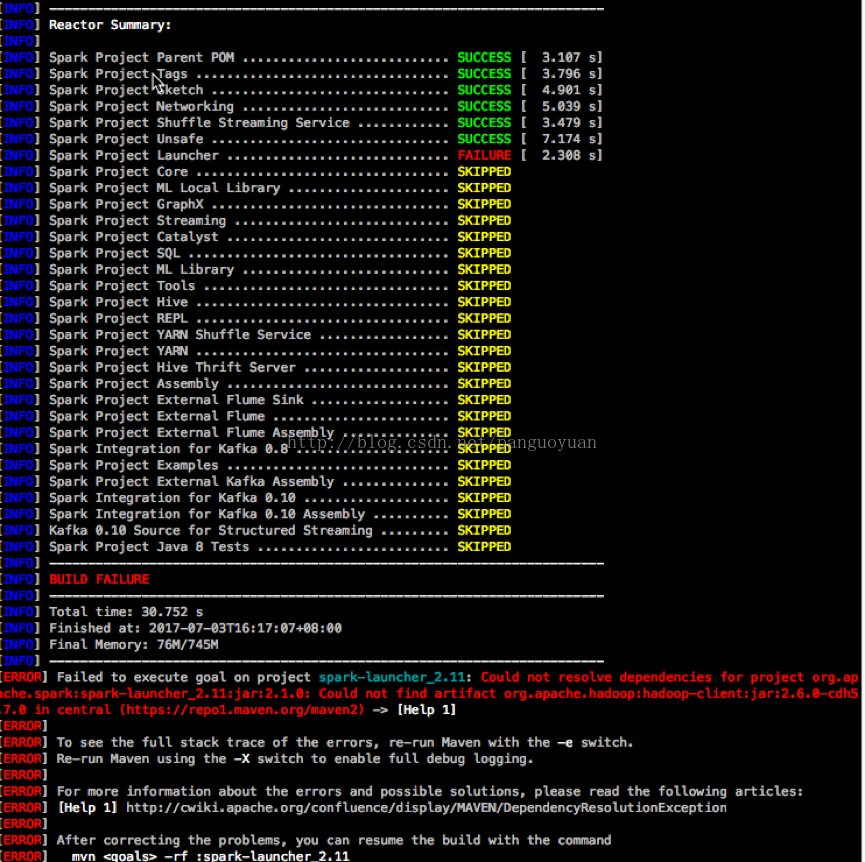
解决办法:检查pom.xml—> repository配置cloudera-repo的位置是否正确
可能遇到的错误3…,在这就不一一列举了,环境不一样,错误也不一样
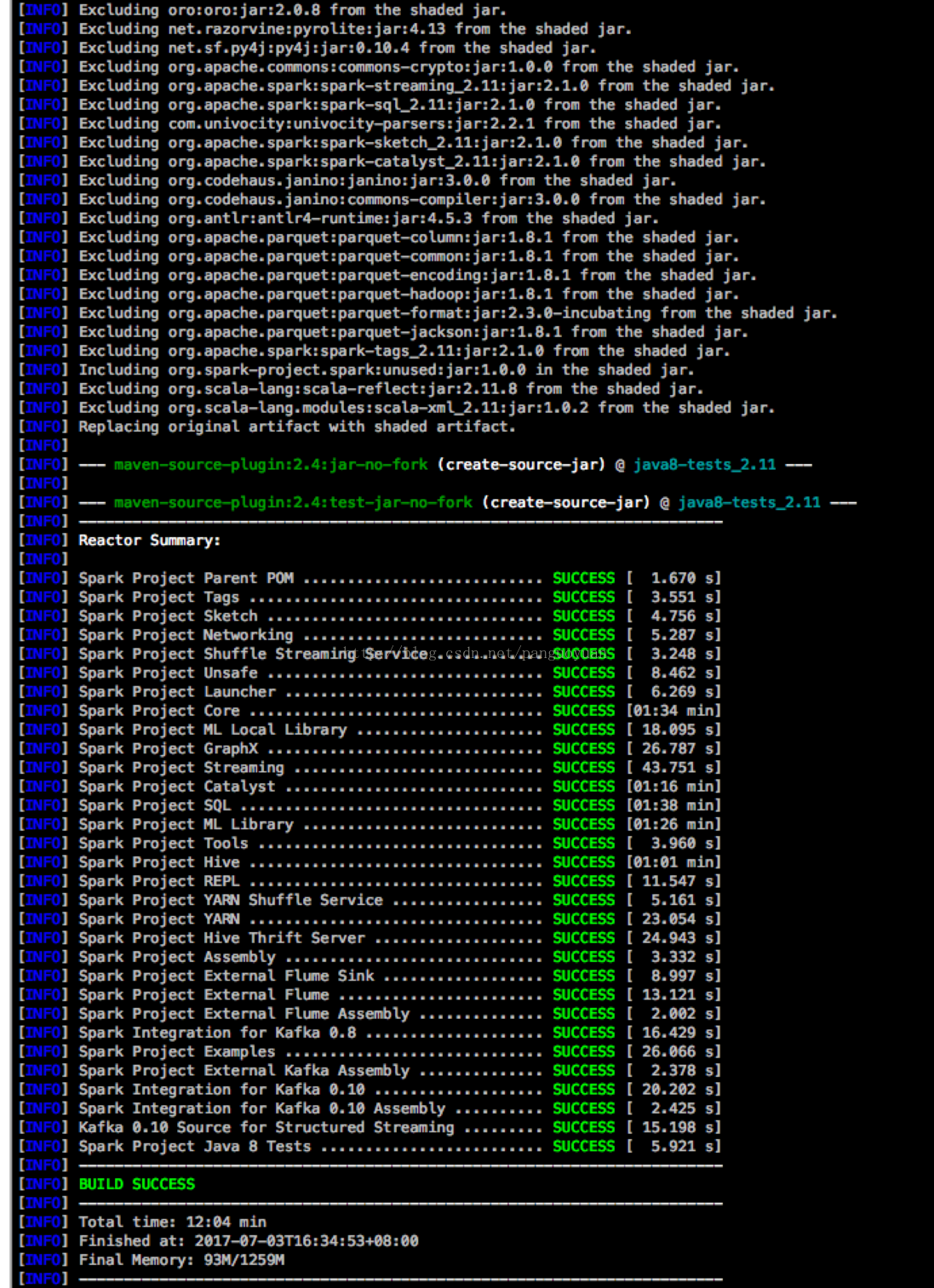
到此为止spark源码编译结束!!!
2、生成可运行的软件包
(1)阅读make-distribution.sh脚本,了解每一步的执行过程;在dev/make-distribution.sh文件里注释掉"${BUILD_COMMAND[@]}",把MAVEN_HOME改成自己之前安装的MAVEN,如果不改的话这个脚本还会去下载再装一遍,可能很慢也可能出现各种错,然后开始构建:dev/make-distribution.sh --name hadoop-2.6.0-cdh5.7.0 --tgz -Psparkr-Phadoop-2.6 -Pyarn -Dhadoop.version=hadoop-2.6.0-cdh5.7.0
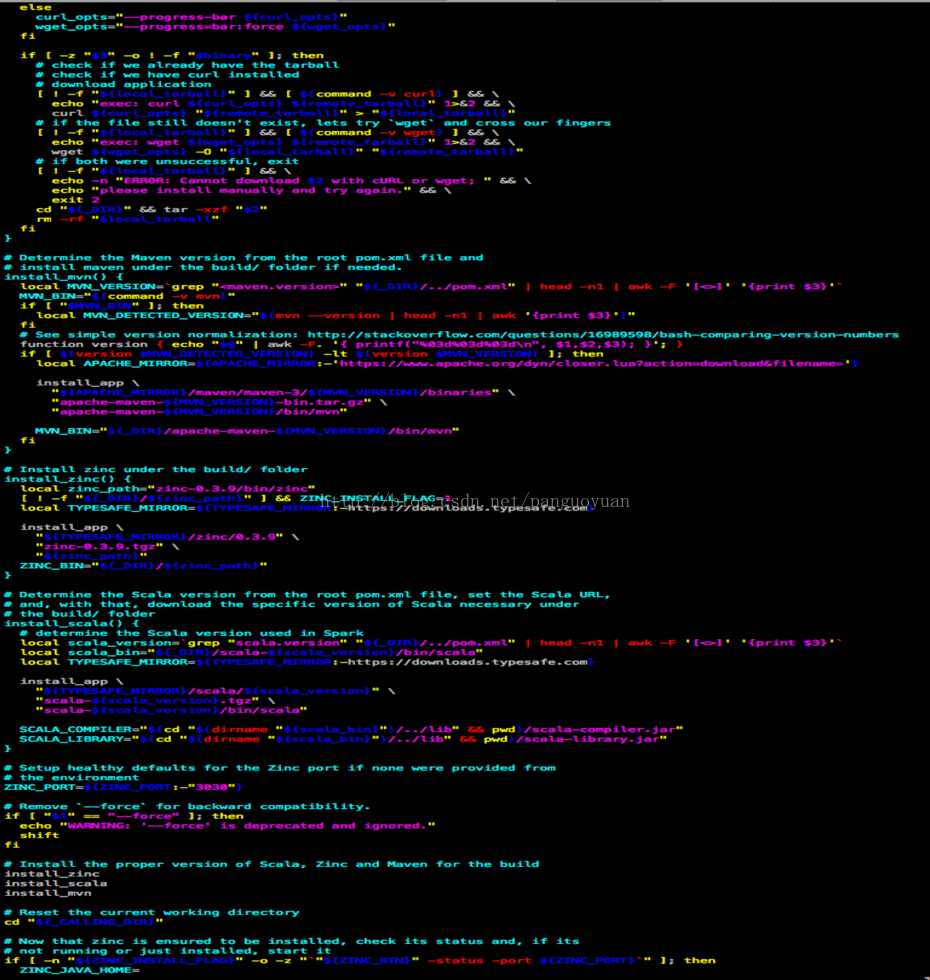
在build/mvn脚本里可以看到有install_zinc、install_scala、install_mvn
(1) 在dev/make-distribution.sh文件里注释掉"${BUILD_COMMAND[@]}",在make-distribution.sh文件里把MAVEN_HOME改成自己之前安装的MAVEN,如果不改的话这个脚本还会去下载再装一遍,可能很慢也可能出现各种错,然后开始构建:dev/make-distribution.sh --name hadoop-2.6.0-cdh5.7.0 --tgz -Psparkr -Phadoop-2.6 -Pyarn -Dhadoop.version=hadoop-2.6.0-cdh5.7.0
(2) 执行完构建打包完之后会在根目录下生成spark-2.1.0-bin-hadoop-2.6.0-cdh5.7.0.tgz文件

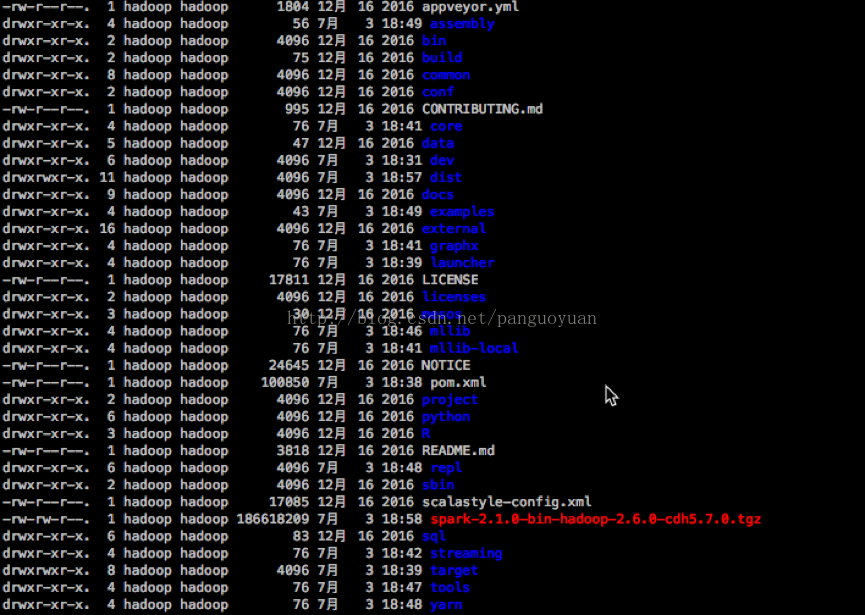
到此打包结束!!!
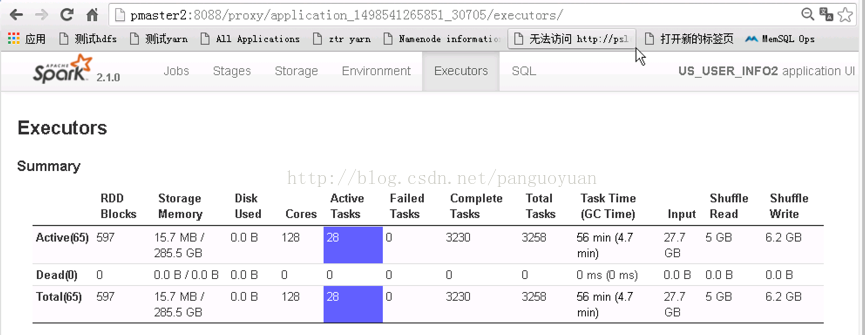
从上图看出spark-sql运行正常














 623
623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









