







 本文介绍了一种编译器在处理多源代码文件时的依赖关系解析算法。通过构建有向无环图来确定正确的编译顺序,避免循环依赖导致的编译失败。
本文介绍了一种编译器在处理多源代码文件时的依赖关系解析算法。通过构建有向无环图来确定正确的编译顺序,避免循环依赖导致的编译失败。
我们平常所使用的主流编译器,都具有多源代码文件支持.例如把一些类定义在相应的文件中,要使用到这些类时,需要包含定义这个类的文件(如C++),或引用类所在的名字空间(如JAVA),或将这个文件作为单元引用(如Object Pascal)
当我们自己要实现一个支持多源代码文件的编译器时,需要在编译某个源代码文件之前,先编译这个源代码所引用到的文件.例如有一个源文件 a.src,里面定义了一个类,内容如下:
class List
{
public void Add(Object obj)
{
...
}
}
然后有一个源文件b.src,里面用到了List类,内容如下:
using "a.src"
class Test
{
public static main(String argv[])
{
List objs = new List;
List.Add(10, 20); //有语法错误
}
}
在编译b.src时,如果a.src文件未被预先编译,编译器将无法识别List类,也无法判断List类是否具有成员函数Add,以及对Add的调用参数列表是否正确等.这时就需要先分析b.src引用了哪些文件,这些文件又引用到了其它哪些文件,并优先编译处于引用列表顶端的文件,并以此类推.
例如存在下面几个源代码文件A, B, C, D, E. 引用关系如下:
A引用: B, C
B引用: D, E
C引用: B, E
D引用: E
E没引用其它文件,这里需要的编译顺序应该如下:
E D B C A
另外,在文件引用关系中不能出现互相引用,这样会导至无法编译.
在了解了为什么要计算源代码依赖关系后,就可以开始实现具体的算法了,可以把这一步放在词法分析之后,语法分析之前来做. 因为词法分析之后,可以很容易的分析出一个源文件引用了哪些其它源文件,如果把这一步放在预处理中专门来做的话,同样需要做去注释,拆词等工作,产生了不必要的重复.
计算源代码依赖关系的算法比较简单,可以先把所有源代码文件看成一个个的顶点,一个顶点(源代码文件)如果引用了另一个顶点,就增加一条从当前顶点到被引用顶点的出边,当增加完所有顶点的出边后,正常情况下这些顶点就形成了一个有向无环图如下图:(如果出现了环,说明源代码文件中产生了错误的循环引用)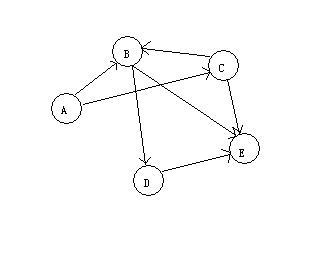
此时采用图的无后继顶点优先拓扑排序方法即可,无后继是指出度为0(即没有出边),即每次删除图中出度为0的顶点和顶点的入边,一直删到没有出度为0的顶点为止,如果删除的顶点数小于图中所有的顶点数,则此图有环,并报错.算法描述如下:
//G为图
void FirstTopSort(G)
{
while(G中有出度为0的顶点)
{
从G中找一个出度为0的顶点v且输出v;
从G中删去v及v的所有入边
}
if(输出的顶点数目 < G的顶点数)
printf("源代码文件存在循环引用!");
}
示意图如下:
先删除第一个出度为0的顶点E和E的入边,并记录E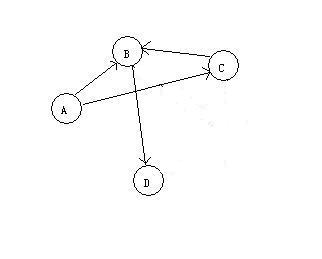
此时D出边为0,删除D和D的入边,并记录D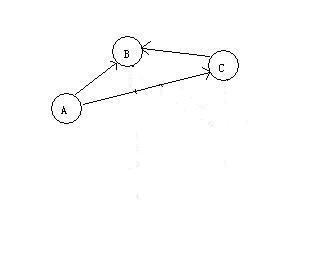
再删除和记录B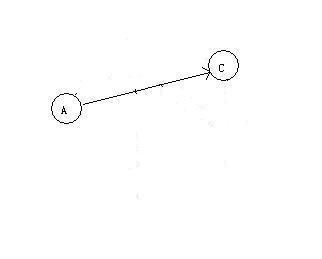
再删除和记录C,最后是A
记录的顺序即是结果 E D B C A

















09-20
 1448
1448
1448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









