







摘要
这些模式描述如何把业务对象映射到非面向对象的数据库中。面向对象和非面向对象这两种技术存在着阻抗不匹配(impedance mismatch),因为对象由数据和行为组成,而一个关系型数据库则是由表和它们之间的关系组成的。虽然不可能完全消除这个阻抗不匹配,你可以遵循适当的模式使之最小化。适当的模式可以向开发人员隐藏持久化细节,而让他们专注于理解域问题而不是如何将对象持久化。
简介
使用关系数据库的面向对象系统开发人员通常要花费大量的时间来将对象持久化,这是因为在两种技术间存在一个基本的阻抗不匹配。对象由数据和行为组成,通常可以继承,而关系数据库包括表、关系和基本的谓词计算函数,这个函数用以返回想要的值。
为避免对象和关系之间的阻抗不匹配,一种方法是使用一个面向对象的数据。然而,系统通常需要将对象存入一个关系型数据库,有的因为一个系统需要关系型理论或关系型数据库的成熟性,有的因为公司策略就是使用关系型数据库而非面向对象数据库。无论是什么原因,一个将对象存入关系型数据库的系统需要提供一个减少这个阻抗不匹配的设计。
本文只描述了将对象映射到关系上的部分模式语言,但是它描述了我们认为在其他地方没有描述充分的模式。全部模式的概要可以参见[Keller 98-2],其中阐述得较好的模式是关于关系型数据库设计和优化的[Brown 96][Keller 97-1,97-2,98-1]。Serializer模式[Riehle et al. 1998]描述了如何串行化对象,让它们可以向不同后端存储和获取,例如文本文件、关系数据库和RPC缓冲。
我们曾使用或研究过若干持久对象系统(GemStone[GemStone 96], TopLink[TopLink 97-1,07-2]和ObjectLens[OS 95])。另外,我们用VisaulAge for Smalltalk为Illinois Department of Public Health(IDPH)实现了一个简单得持久化框架,这里介绍的模式存在于所有这些系统中。商业系统在这些模式上的使用通常比我们的框架更加彻底,我们曾更想购买一个持久化框架,但是我们的预算无法负担它们。我们这些需要使用持久框架的应用系统很简单,涉及到几十个数据表,每个应用管理一个病人的病历信息,所有应用共享病人统计信息,例如病人姓名、地址和医院、医生的信息,而每个应用各自负责某个领域,例如病人的免疫、血液检查等。虽然一个应用能够管理一个病人的大量信息,在某个时刻,它将只检查一个病人。本文的示例将向您展示在为IDPH开发的应用中,如何协同使用这些模式,解决持久化Name和Address对象的问题。
这些模式串在一起,手拉手地工作,来解决上面提到的阻抗不匹配问题。一个持久层将开发人员和实现持久化的细节隔离开,并保护开发人员不为变更所困。持久层是构建一个层的特例,保护您远离应用程序和数据库的变更。实现持久层的方式之一是通过一个PersistentObject,另一个方法是通过一个中间人(Broker)[BMRSS 96]。
向数据库读取和写入需要基本的创建、读取、更新和删除操作,虽然每个对象能够有它们自己的访问数据库接口,但是如果您的系统向持久层提供一组共通操作,那么所有的对象都可以使用,这样的系统就会更易使用和维护。不管您采取哪种实现持久层的方式,都需要支持CRUD(创建、读取、更新和删除)操作。
CRUD操作最终会使用SQL代码访问数据库,有某种SQL代码描述来构建实际的数据库SQL调用是很重要的。
当从数据库取出值或者将值存回数据库,系统必须进行属性映射来映射数据库字段值和存储在对象属性中的值。阻抗不匹配的一部分就是关系型和对象系统有着不同类型的数据,映射对象和数据库的值需要转换两种技术中值的类型。
当对象属性发生改变后,将它们存入数据库是很重要的,因此,任何持久对象系统都应该使用某种变更管理器来跟踪哪些对象发生了变化,使得系统能够跟踪到哪些对象已经被改变,以确保根据需要保存。变更管理器同时也有助于减少数据库访问,因为它只为改变过的对象创建事务并保存。
因为在面向对象系统中每个对象都是唯一的,通过一个OID管理器为每个新对象创建一个唯一标识就很重要。同时,支持事务也是非常重要的,它确保改变一个对象是一个原子操作,可以通过一个事务管理器回滚该操作。任何访问一个RDBMS的系统将通过某种联接管理器提供对目标数据库的联接。通过一个表管理器处理数据库表名、字段名也是非常有益的。
表1中的模式目录概括了本文中讨论的模式,它列出了每个模式的名称,以及它所解决问题的简要描述。
| 模式名称 | 描述 |
| 持久层 | 提供一个层,将您的对象映射到关系数据库或其他数据库上 |
| CRUD | 所有持久对象至少需要的创建、读取、更新和删除操作。 |
| SQL代码描述 | 定义实际的SQL代码,从关系数据库和其他数据库中取得值,被对象所用,反之亦然。它被用来生成执行CRUD操作的SQL代码。 |
| 属性映射方法 | 映射数据库值和对象属性值,这个模式也处理复杂对象的映射,根据数据库表的一条数据行产生对象。 |
| 类型转换 | 和属性映射方法一起使用,在数据库类型和对象类型之间转换,确保数据完整性。 |
| 变更管理器 | 为维护数据完整性,跟踪对象值的变化情况,由它决定是否需要写入到数据库中。 |
| OID管理器 | 在插入时为对象产生唯一的对象ID。 |
| 事务管理器 | 当保存对象时提供事务处理机制。 |
| 联接管理器 | 得到并维护数据库联接。 |
| 表管理器 | 管理一个对象和数据库表、字段的映射 |
表1 - 模式目录
持久层
别名:
关系数据库访问层
动机:
如果您构建一个大型的面向对象业务系统,而将对象保存到关系型数据库中,您可能要花很多时间去处理如何使对象持久化。如果您不够仔细,开发系统的每个程序员都不得不了解SQL代码以及访问库的代码,从而被数据库所约束。将您的系统从Microsoft Access转到DB2上会有大量的工作,乃至为一个对象添加很多变量。所以您需要将您的领域知识从对象是如何存储的知识中分离开,保护开发人员不会为这些变化所困。
问题:
如何将对象保存到一个非面向对象的存储机制中?例如关系型数据库,而开发人员不必知道实际的实现方式。
特定约束:
? 对熟悉数据库的开发人员来说,写SQL语句很容易;
? 设计一个优秀的持久化机制需要花费时间,但是它不直接给用户提供什么功能;
? 数据库访问代价不菲,通常需要优化;
? 开发人员应该可以不必担心如何在数据库中存取而专注于解决应用系统的业务域问题;
? 有一个使用模板方法的共通接口,使代码更易重用;
? 使用一个单一的接口将强制所有的类拥有最低程度的共同性;
? 在应用系统的生命周期中,持久存储类型有可能会改变;
? 在应用系统的生命周期中,业务模型有可能经常会变;
解决方案:
提供一个持久层,可以从一个数据存储源中生成对象,并可以把数据保存到数据存储源中去。这一层向开发人员隐藏了对象存储的细节,这实际上是构建一个层(Layer)[BMRSS96]的特殊情况,使您自己免于变化之苦。所有持久对象都使用持久层的标准接口,如果数据存储机制改变了,只有持久层需要改变。例如,公司主管在项目开始使用Oracle,到项目中期又转到DB2上。
系统需要知道如何存储和装载每个对象,有时候一个对象存储在多个媒介上的多个数据库中。一个对象作为另一个更复杂对象的部分,需要跟踪它是哪个对象的一部分,这叫做所有者对象。这个所有者对象的概念使编写复杂查询变的很容易,因此,持久层为每个对象和它的父对象提供唯一标识是很重要的,这个唯一标识符和父标识符在实现Proxy模式时非常有用,可以作为部件对象的占位符。
总结一下模型名称的使用,持久层提供必要的方法,通过构造SQL代码提供CRUD操作,提供属性映射方法,为对象数据值进行类型转化,访问表管理器,提供对事务管理器的访问,通过联接管理器联接到数据库。同时持久层也有助于提供适当的变更管理,并和OID管理器协作提供唯一的对象标识。
有很多方法可以实现一个持久层,这儿列举一二。
1. 使用一个对象层[Keller 98]。每个域对象从一个抽象的PersisentObject类继承,知道如何执行必要的CRUD操作。本文示例使用的就是这种方式,它的主要好处是易于实现。虽然它在每个域类中都要写一些数据库相关的代码,不过这些代码是分开的,易于查找和修改,它可以在必要时进行优化,尽管一个过于优化的系统难以理解。
2. 使用一个中间人,它可以从数据库读取域对象或将对象写入数据库,中间人必须知道每个域对象的格式,生成SQL语句去读写。这种方式将数据库代码和域对象类分离开来,是一种最具伸缩性的解决方案,不过需要很多基础部件。
3. 用一组数据对象组成一个域对象,这些数据对象和数据库表具有一对一关系。这样,一旦一个域对象改变了,改变相应的数据对象,并且在域对象保存时,他们也将被保存。例如,一个Patient的值可以映射到Name和Address数据表,Patient对象将拥有映射到Name和Address的数据对象。VisualWorks中,ObjectShare的ObjectLens就是采用这种方式构造数据库对象。持久层通过这些数据对象管理起来,它很容易实现并易于理解,尽管有些慢,并且开发人员必须要维护数据库表的一一映射关系。
注:主要的决策依据应该看对灵活性、伸缩性和可维护性的要求。
实现举例:
现在很多关于正确描述构建中间人[BMRSS96]的细节工作已经完成,而且我们拥有更多实现层对象的经验,因此,我们的例子将主要关注于这个模式的实现。其他在实现中间人中描述的模式在我们讨论中也将简短提到。我们所有的示例代码都将描述基于PersistentObject的实现。
图1是一个UML类图,表示一个持久层将域对象映射到关系数据库的实现。请注意在这个例子中,需要被持久化的域对象是PersistentObject的子类,PersistentObject为持久层提供接口。PersistentObject和表管理器交互,可以为SQL代码提供物理表名,在SQL代码生成时,PersistentObject和联接管理器交互以提供必要的数据库联接。如果需要,当需要一个新的唯一标识时,向OID管理器请求。这样,PersistentObject作为一个中间的集线器,为域对象提供需要而它本身没有的任何信息。PersistentObject为持久层提供标准的接口,通过和其他模式一起合作,一旦SQL代码准备好了,SQL语句将被数据库部件触发,在IBM VisualAge for Smalltalk中,这些就是AbtDBM*应用系统。
PersistentObject的属性如下:
? objectIdentifier - 对象唯一的标识符,可以是数据库键值。
? isChanged - 标志对象是否被修改过,告诉持久层这个对象是否要写入数据库中。
? isPersisted - 标志对象是否曾写入到数据库中。
? owningObject - 标识父对象,在数据库中作为一个外键使用。注意这个外键在本对象而不是父对象中。
PersistentObject的公共方法如下:
? save - 将对象数据写入到数据库中,它将更新或插入行;
? delete - 从数据库中删除一个对象的数据;
? load - 从数据库中返回一个类的单一实例及它的数据;
? loadAll - 从数据库返回一个类的实例集合,包含所有数据,这对为选择列表返回数据非常有用;
? loadAllLike - 从数据库返回一个类的实例集合,包含部分数据;
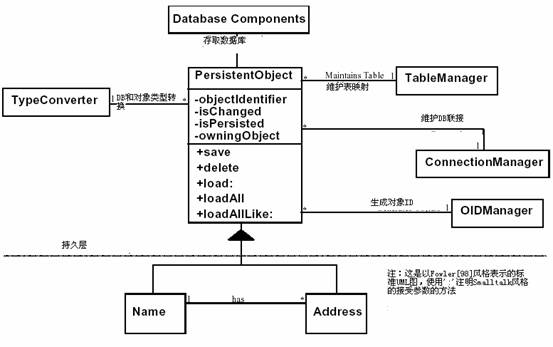
图1 - 持久类类图
数据库记录可以以三种方式读取:
? 读取一行(PersistentObject>>load:);
? 读取所有记录(PersistentObject>>loadAll);
? 读取所有符合条件的记录(PersistentObject>>loadAllLike)
指定一个特定条件,创建一个对象的新实例并为它装载对应的属性集,这个功能可以通过PersistentObject>>load:和PersistentObject>>loadAllLike:方法实现。而当您想产生一个选择列表或是下拉列表时,PersistentObject>>loadAll方法是非常有用的。
下面的示例代码描述了上面所说的PersistentObject,它们是公共的接口方法,支持事务管理(后文详述)。read:和saveAsTransaction方法将在CRUD模式中详述。
Protocol for Public Interface PersistentObject (instance)
load
“得到匹配它自己的PersistentObject子类的单一实例”
| oc |
oc := self loadAllLike.
^oc isEmpty ifTrue: [nil] ifFalse: [oc first]
loadAllLike
“得到匹配它自己的PersistentObject子类的实例集合,selectionClause方法为PersistentObject的read方法准备Where子句”
^self calss read: ( self selectionClause )
save
“保存他自己到数据库中,包含在一个事务当中。”
self class beginTrasacction.
self saveAsTransaction.
self class endTransaction.
delete
“从数据库中删除他自己,包含在一个事务当中。”
self class beginTrasaction.
self deleteAsTransaction.
self class endTransaction.
Protocol for Public Interface PersistentObject (class)
loadAll
“从数据库返回我的所有实例”
^self read: nil.
下面是Name类的示例代码,Name有Address,因此它将有一个部件,需要被存储,这个方法被任何需要被存储而拥有持久化部件的域对象重载。
Protocol for Private Interface Name (instance)
saveComponentIfDirty
“验证address对象的存在,并验证proxy模式没有占据这个位置,address所有者对象被设为当前对象,并且address对象的保存也是当前事务中的一部分。”
(self address isNil or: [self address isKindOf:
PPLAbstractProxy])
ifTrue: [^nil].
self address owningObject: self objectIdentitier.
self address saveAsTransaction
结论:
? 把应用开发人员从对象存储细节中隔离开来的另一个好处是易于实现域对象,因此,域模型变更的工作就变少了。总之通过封装对象持久机制的功能,可以有效地对开发人员隐藏对象存储的细节。
? 可以改变数据库技术,而不影响您的应用程序代码。
? 使改变对象存储到数据库的方式变的很容易,因为我们已将需要改变的地方隔离起来了。
? 用户只需要调用同样的接口去持久化对象,开发人员无需检测一条记录是否已经存在于数据库中。
? 用SQL代码实现起来很简单的事情,用持久层可能使它变的复杂而且有时候难以操作。
? 持久层的优化很困难。程序员应实现对不同方式做评测来决定哪一个更适合他的实现。
相关或交互的模式:
? 关系数据库访问层是一个很相似的模式,它描述了一个需要持久化的对象交互的层。
? 分层架构[Shaw 96]描述了必要的模式,将体系架构分层,以便在开发中隔离变更。
? 信息系统的分层架构讨论了开发分层系统的实现细节。
? 层[BMRSS 96]描述了分层系统架构和设计时,需要考虑的细节。
已知应用:
? GemStone OODBMS使用持久层隐藏一个值是一个持久对象的事实。在实际需要时使用代理为持久层获取值,在这个例子中,存储系统不是关系型数据库。
? Caterpillar/NCSA金融模型框架[Yoder 97]使用持久层,所有的值都通过一个Query对象存储。这个例子中,应用程序在数据库中不存储任意域对象,只是获取事务。然而,持久层仍隐藏了数据库和关系型数据库技术的细节。
? ObjectShare VisualWorks Smalltalk ObjectLens[OS 95]使用持久层映射数据对象和数据库表。
? VisualAge for Smalltalk也使用持久层和它们的AbtDbm*应用。VisualAge提供图形化联接的GUI构建器,形成一个持久机制。
? Illinois Department of Public Health’s TOTS和NewBorn Screening项目使用一个和本节例子非常相似的实现方法。
? TopLink、MicroDoc、Sparky和Object Extencer[MicroDoc 98, Sparky 98, OE 98]都提供一个持久层来将对象映射到关系型数据库中。
? PLoP登记系统实现了一个持久层,将Java对象存到PostGress数据库中[JOE PUT THE REF HERE]。
CRUD
别名:
创建、读取、更新和删除
基本持久操作
动机:
试想你有一个Patient类,有Name和Address部件,当你读取一个Patient,必须同时读取Name和Address。写入一个Patient到数据库中将有可能写入一个Name和Address对象。他们是否有同样的接口去读取和写入呢?也许有些对象需要不同的接口?我们能否给出完全同样的接口,如果可以,是什么?
任何被持久化的对象都要对数据库进行读取和写入,对新创建的对象,它的值也会被持久化,另外,对象也可以从持久存储中删除,因此,如果一个对象需要持久化,至少要提供最小的操作集合,他们是创建、读取、更新、删除。
问题:
一个持久对象最小的操作集合是什么?
特定约束:
? 保存在数据库中所有的对象需要一个装载自己、保存自己的机制;
? 在一个地方放置读取和写入的代码有助于对象的演进和维护;
? 如果类只实现同样且小的接口,可以很容易将他们组成嵌套的类。
解决方案:
为持久对象提供基本的CRUD(创建、读取、更新和删除)操作。其他需要的操作如loadAllLike:或loadAll。重要的是要提供足够多的信息能够从数据库实例化对象,并保存新建的或改变了的对象。
如果所有域对象都有一个共同的PersistentObject超类,那么这个超类可以定义CRUD操作,而所有的域对象能够从它继承,如有必要,子类可以重载他们以提高性能。
如果持久层是使用中间人实现的,那么CRUD操作也由中间人实现,不论什么情况,持久层必须生成SQL代码来读取和写入域对象。这样,每个域对象必须能够获得必要SQL代码的描述,来访问CRUD操作的数据库。CRUD和SQL代码描述紧密合作,确保这些操作能有效持久化域对象。
示例实现:
前面阐述的PersistentObject提供了标准接口,一组基本的操作来映射对象到数据库,保存、装载等。这些方法从PersistentObject继承,访问CRUD操作。有些CRUD方法需要在域对象中重写。AbtDBM*数据库部件提供了executeSql: 方法,让数据库执行SQL语句并返回值。updateRowSql和insertRowSql将在下面SQL代码描述模式中详述。
Protocol for CRUD PersistentObject (class)
这个方法指定一个WHERE子句作为中介,并返回一组和WHERE条件相匹配的对象集合。
read: aSearchString
“从数据库返回一个对象实例集合。”
| aCollection |
aCollection := OrderedCollection new.
(self resultSet : aSearchString)
do: [:aRow | aCollection add:(self new initialize: aRow)].
^aCollection
Protocol for Persistence Layer PersistentObject (instance)
这些方法对数据库保存或删除对象,这些方法要基于对象的值判断执行什么SQL语句(insert、update或delete),一旦决定,SQL语句将在数据中执行。
saveAsTransaction
“保存自己到数据库中。”
self isPersisted ifTrue: [self update] isFalse: [self create].
self makeClean
update
“更新聚合类,然后在数据库中更新他自己”
self saveComponentIfDirty.
self basicUpdate
create
“插入聚合类,然后在数据库中插入自己”
self saveComponentIfDirty.
self basicCreate
basicCreate
“在数据库中触发插入SQL语句”
self class executeSql: self insertRowSql.
isPersisted := true
basicUpdate
“在数据库中触发更新SQL语句”
(self isKindOf: AbstractProxy) ifTrue: [^nil].
isChanged ifTrue: [self class executeSql: self updateRowSql]
deleteAsTransaction
“从数据库中删除自己”
self isPersisted ifTrue: [self basicDelete].
^nil
basicDelete
“在数据库中触发删除SQL语句”
self class
executeSql:( ‘DELETE FROM ‘,self class table, ‘ WHERE ID_OBJ=’,
(self objectIdentifier printString)).
结论:
? 一旦你的对象模型和数据模型分析完毕,分析结果可以用CRUD实现,提供一个性能优化的方案,使开发人员从性能优化的考虑中隔离开来。注:如果你的对象模型和数据模型分析完毕,你能够为你的数据库提供优化的性能方案来实现CRUD操作,以向应用开发者隐藏实现细节。
? 基于多少行或何种类型数据(动态、静态或介于两者之间)来获取数据的灵活性是有必要的;
? 简单的实现数据保存到数据库,应用开发人员无需决定是插入还是更新对象;
? 如果对象模型和数据模型没有很好的分析,CRUD将引起子优化性能的问题。这将使开发者的工作变困难,不得不尝试其他的方法。
相关或交互模式:
? 事务管理器为这些操作提供事务支持;
? CRUD和SQL代码协作,生成必要的数据库调用。
已知应用:
? Illinois Department of Public Health TOTS 和NewBorn Screening 项目
? ObjectShare的VisualWorks Smalltalk ObjectLens[OS 95]使用一个CRUD,以定义如何操纵简单数据对象。VisualAge Smalltalk[VA 98]也在他们的AbtDbm*应用系统中使用CRUD。
SQL代码描述
别名:
查询、更新、插入和删除代码定义
对象查询语言(OQL)描述
通用查询语言(CQL)描述
结构查询语言(SQL)描述
动机:
有的地方,不得不编写从数据库中读取、更新、插入和删除值的SQL代码以保持对象值和持久存储值的一致性。再一次看看一个拥有Name和Address部件的Patient类,SQL代码需要读取和写入Patient的值,同时也必须存储Name和Address的SQL。一方面,你可以硬编码SQL,来读取和写入数据库,另外你也可以在一个共同的地方存储值,开发一个存放对象到数据库的映射的结构映射,并在运行期动态生成SQL。
问题:
在什么地方存储用来生成CRUD操作所需的必要SQL语句的实际描述?
特定约束:
? 当访问一个关系型数据库,对数据库访问的SQL代码必定在某处出现;
? 当域模型增加时,SQL代码的数量也随之增加;
? 编写有效的SQL代码需要你对数据模型和数据库有很深的了解;
? 域模型有可能在一个应用的生命周期内频繁变动;
? SQL代码可以放置在数据库访问需要的任何地方;
? 重复的相似SQL代码可能引起维护的问题;
? 从元数据生成SQL代码能够隐藏一个对象访问开发者框架的细节,但是有一个性能和维护之间的平衡。
解决方案:
提供一个开发者描述SQL代码的地方,以维护对象和持久存储之间的一致性。至少域对象需要知道如何执行CRUD操作(创建、读取、更新和删除)。必要的处理CRUD操作的SQL代码需要在某个地方定义。
维护对象值和持久存储值的一致性非常重要,同时,提供一个手段,让饱受煎熬的程序员尽可能不会在修改完一个域对象后忘了提交一个Update语句也是同样重要的。
这个模式可以以多种方式实现,但要点是SQL语句是封装起来的并且要很容易和持久对象关联起来。SQL代码和域对象紧密关联,那么开发者修改了一个域对象而忘了更新SQL语句的可能性就不大了。
实现二者紧密关联的一个方式就是实实在在地为每个操作编写完全的SQL代码,然后让持久层从域对象读取SQL代码,创建数据库联接并执行数据库调用,中间人和对象都能够从域对象生成SQL代码。另一个方式是提供一个对象查询语言(OQL),它是对CRUD所需必要操作的描述,OQL将被翻译成对数据库必要的调用。另外,还可以使用元数据(Metadata)[Foote&Yoder 1998]来描述CRUD操作,一个CRUD操作翻译元数据来构建适当的SQL,大多数商业性框架都使用这种方式,他们通过某种Schema Map[Foote&Yoder 1998]构建这个结构,这些商业性框架大多提供一种可视化语言来构建和操纵这些查询。使用元数据和Schema Maps构建的实现和维护会变的复杂些,并且会产生一些非优化的查询,但是他们能使开发者易于描述域对象和数据库之间的映射,特别是当有可视化语言辅助这一工作时。
如果你正实现一个更大规模的系统,你拥有上千行的SQL代码和动态的SQL,他们不够快,你也许想替代他们或修改他们,例如调用存储过程、预编译的SQL、实现推拉技术或是高速缓存技术,这叫做优化查询模式[Keller 97-2]。
示例实现:
当你使用一个数据库,你必须编写一些SQL语句来获取、插入、更新和删除记录,例如最简单的形式,如下:
SELECT * FROM table_name.
INSERT INTO table_name (column_name) VALUES (values)
UPDATE table_name SET column_name = xyz WHERE key_value
DELETE FROM table_name
这看起来很简单,但是如何从一个对象得到值放置到这些语句中呢?
你能够使用一个字符流来放置语句中固定部分和对象的属性,或者,那样可以定义你想获取的列。
aStream nextPutAll: ‘SELECT’;
nextPutAll: column_names;
nextPutAll: ‘FROM ‘;
nextPutAll: table_name.
或者
aStream nextPutAll: ‘INSERT INTO ‘;
nextPutAll: table_name;
nextPutAll: (column_names);
nextPutAll: ‘VALUES ‘;
nextPutAll: (values).
下面是一Name类实例方法的例子,Name类在我们的例子中是一个域对象,名称和地址是管理类应用系统中大多都有的。这是用一个非常小的复杂对象演示持久层的简单例子,如上所述,SQL语句并不非得硬编码不可,如果你的数据库和你的对象模型非常相似,那么,可以从一个数据库schema来生成这些语句。
Protocol for SQLCODE (instance)
这些方法为持久层提供实际的SQL语句,他们将被送到数据库中执行,这个SQL语句构成一个字符流并传入到持久层执行。这个例子演示了类型转换器和表管理器的使用,他们将在本文的后面章节详述。
这些方法构建实际被送到数据库的SQL语句,为了性能考虑,使用了写入字符流而不是字符拼接。
insertRowSql
“返回一个插入SQL语句,语句中包含了从对象得来的值。”
| aStream |
aStream := WriteStream on:(String new).
aStream nextPutAll: 'INSERT INTO ';
nextPutAll: self class table;
nextPutAll:' (ID_OBJ,
ID_OBJ_OWN,
NAM_FST,
NAM_LST,
NAM_MID,
EML_ADR,
ORG_NAM,
NUM_PHO)
VALUES (';
nextPutAll: (self typeConverter prepForSql:
(objectIdentifier:= (self getKeyValue)));
nextPut: $,;
nextPutAll: (self typeConverter prepForSql:
self owningObject);
nextPut: $,;
nextPutAll: (self typeConverter prepForSql:
(self first asUppercase));
nextPut: $,;
nextPutAll: (self typeConverter prepForSql:
(self last asUppercase));
nextPut: $,;
nextPutAll: (self typeConverter prepForSql:
(self middle asUppercase));
nextPut: $,;
nextPutAll: (self typeConverter prepForSql:(self email));
nextPut: $,;
nextPutAll: (self typeConverter prepForSql:
(self organization));
nextPut: $,;
nextPutAll: (self typeConverter prepForSql:(self phone));
nextPutAll: ')'.
^aStream contents.
updateRowSql
“返回一个更新SQL语句,语句中包含从对象得来的值”
| aStream |
aStream := WriteStream on:(String new).
aStream nextPutAll: 'UPDATE ';
nextPutAll: self class table;
nextPutAll: ' SET NAM_FST=';
nextPutAll: (self typeConverter prepForSql:
(self first asUppercase));
nextPutAll: ', NAM_LST=';
nextPutAll: (self typeConverter prepForSql:
(self last asUppercase));
nextPutAll: ', NAM_MID=';
nextPutAll: (self typeConverter prepForSql:
(self middle asUppercase));
nextPutAll: ', EML_ADR=';
nextPutAll: (self typeConverter prepForSql:(self email));
nextPutAll: ', ORG_NAM=';
nextPutAll: (self typeConverter prepForSql:
(self organization));
nextPutAll: ', NUM_PHO=';
nextPutAll: (self typeConverter prepForSql:(self phone));
nextPutAll: ' WHERE ID_OBJ=';
nextPutAll: (self typeConverter prepForSql:
self objectIdentifier).
^aStream contents.
这个方法为SQL的select语句提供where子句,每个类都有这个方法来决定select语句中where子句可以使用什么。
selectionClause
“得到一个where子句的字符串表示”
| aStream app|
aStream:= WriteStream on:(String new).
( self objectIdentifier isNil )
ifFalse: [ aStream nextPutAll: 'ID_OBJ=';
nextPutAll: (self class typeConverter prepForSql:
self objectIdentifier).
^aStream contents ].
( self owningObject isNil )
ifFalse: [ aStream nextPutAll: 'ID_OBJ_OWN= ';
nextPutAll: (self typeConverter prepForSql: self owningObject)].
^aStream contents.
Protocol for SQLCODE (class)
这些方法为上面的方法提供表名,并定义在上面产生的where子句中,哪些列将从数据库返回。
table
“从表管理器返回表名。”
^TableManager gettable: ‘EXAMPLE’
buildSqlStatement: aString
“为对象返回读取的SQL语句。”
| aStream |
aStream := WriteStream on:(String new).
aStream nextPutAll: 'SELECT
ID_OBJ,
ID_OBJ_OWN,
NAM_FST,
NAM_LST,
NAM_MID,
EML_ADR,
ORG_NAM,
NUM_PHO FROM ';
nextPutAll: self table.
((aString isNil) or:[ aString trimBlanks isEmpty])
ifFalse:[aStream setToEnd;
nextPutAll: ' WHERE ';
nextPutAll: aString].
^aStream contents.
Protocol for SQL Code PersistentObject (instance)
每个对象需要向持久层提供SQL代码描述,如果对象不需要部分SQL代码,它应该返回“shouldNotImplement”。
insertRowSql
^self subclassResponsibility
selectionClause
^self subclassResponsibility
updateRowSql
^self subclassResponsibility
结论:
? 灵活性,只返回需要的集合,同时,SQL语句可以被替换成其他的形式,如存储过程或预编译查询等;
? SQL语句的性能可以很容易使用数据库工具来判断。
相关或交互模式:
? SQL代码描述使用翻译器模式[GHJV 95]生成数据库语句;
? SQL代码描述使用构建器模式[GHJV 95]为不同的对象提供相同过程;
? SQL代码描述能够使用元数据[Foote&Yoder 98]来生成SQL语句;
? SQL代码描述需要知道Schema[Foote&Yoder 98]以生成正确的语句;
? SQL代码描述为持久层的CRUD操作生成代码;
? SQL代码描述使用从属性映射方法得来的值生成。
已知应用:
? Illinois Department of Public Health TOTS和NewBorn Screening项目;
? ObjectShare的VisualWorks Smalltalk[OS 95]使用SQL代码描述,用来定义如何为简单数据对象执行CRUD操作。VisualAge Smalltalk也在他们的AbtDbm*应用程序使用SQL代码描述;
? 在GemStone GemConnect[GemConn 98],使用SQL代码描述,向一个关系数据库读取和写入对象值。
属性映射方法
别名:
映射数据库到对象
映射对象到数据库
动机:
当从数据库中得到一行记录,每个列的值必须映射到对象的一个属性或一组属性上,同样,当将值存入到数据库中,一个对象的属性必须以某种方式映射到数据库的字段上。试想一下病人的例子,一个Patient对象有病人的姓名和性别相关联,它们可以从数据库的病人表中读取,同时Patient对象还有一个地址关联者,这个值也许有一个外键,参照另一个对象例如Address对象,这样,当读取一个Patient对象,属性映射必须分别将数据库中放置姓名、性别值的字段映射到Patient对象的name和sex属性上,同时,需要创建一个Address对象,并映射到Patient对象的address属性。
问题:
开发者在哪儿、如何描述数据库值和对象属性之间的映射?
特定约束:
? 对象在属性变量中存放值,而数据库在字段中存放值;
? 一个对象的属性到数据库表字段的映射并不总是一对一的;
? 有些对象需要从多个数据库、多个数据库表中得到值,它们是复杂对象;
? 非面向对象数据并不能很好地表示层次结构和对象类型;
解决方案:
对每个需要持久化的对象,编写一个映射数据库值到对象属性的方法和一个映射对象属性到数据库值的方法。持久层将使用第一个方法把从数据库返回的值存储到相应的对象属性中。同样,当PersistentObject存储时,持久层将使用第二个方法把对象的值送到数据库中。当PersistentObject生成SQL代码时,它将映射这些数据。
这些方法从数据库返回一行并填入到相应对象属性中,有时若干字段会映射到一个属性上,这些方法必须也能得到一个对象的属性值,通过一个数据库写入例程映射到数据库字段上,通常情况下,一个属性映射到一个或多个数据库字段,但有时也会是多个属性映射到一个数据库字段上。还有些情况,属性值可能从不同平台的不同数据库产生,对这种情况,聚合类将从别的数据库装载,返回对象赋予给当前的属性。
通常至少有两组属性映射方法,一个用来从数据库读取值,一是将值写回到数据库。当值已被映射到数据库上,属性映射方法需要提供对类型转换的调用。
元数据可以用来定义属性映射,可以和Schema一起使用,也可以不用它。在这种情况下,翻译器将用来生成属性映射。可视化语言也可以用来描述映射,但这种方法通常很难实现和维护,然而一旦实现了,开发者很容易映射一个对象的属性。
当一个属性被映射到另一个域对象,通常使用代理来延迟初始化,例如上面提到的Patient例子,因为很少需要一个病人的地址信息,一个代理可以用来初始化address属性,以后,无论何时需要访问病人的地址,病人的地址信息将从数据库读出来并创建Address对象,在这个例子中,address属性也被更新成指向新创建的Address对象。
实例实现:
一旦数据从数据库取出,他们将从返回的行移到对象属性中去,返回行(VisualAge中)是一个字典结构,可以按下面方式访问:
aRow at: keyValue.
接着,你要将值赋予给属性:
attribute := (aRow at: keyValue).
或者,如果属性要包含一个其他类实例:
attribute := ((Class new) owningObject:
objectIdentifier; youself) load.
将从数据库装载一个Address类的实例并赋予给属性,如果数据库包含的地址信息在不同平台的不同数据库中,Address类将从其他数据库装载。
下面是Name类的属性映射方法,展示了如何映射数据库行到对象的以及应用类型转换的过程。SQL代码描述模式展示了如何将对象映射回数据库中。
Protocol for Map Attributes (instance)
这些方法从PersistentObject>>read:方法接受一行aRow(一条记录),数据表的每行被传入到一个新的实例(被PersistentObject初始化),行中的每个元素在赋给属性前,进行必要的类型转换,对于复杂对象的情况,属性值通过发送一个PersistentObject>>load:(如果是集合的话,发送PersistentObject>>loadAllLike:)到属性类类型,这个方法使用一个带条件语句SQL代码描述实例。例如,在Name类中,你将发送loadAllLike:消息到Address类,并以objectIdentifier作为参数,这将装载所有的owningObject为同一个Name的地址。
initialize: aRow (Name class)
“从一个数据行初始化一个对象实例。”
objectIdentifier := self typeConverter convertToNumber:
(aRow at: ‘ID_OBJ’).
owningObject := aRow at: ‘ID_OBJ_OWN’.
isPersisted := true.
first := self typeConverter convertToUpperString:
(aRow at: ‘NAM_FST’).
middle := self typeConverter convertToUpperString:
(aRow at: ‘NAM_MID’).
last := self typeConverter convertToUpperString:
(aRow at: ‘NAM_LST’).
email := self typeConverter convertToString:
(aRow at: ‘EML_ADR’).
organization := self typeConverter convertToUpperString:
(aRow at: ‘ORG_NAM’).
phone := self typConverter convertToNumber:
(aRow at: ‘NUM_PHO’).
address := (( Address New)owningObject:
objectIdentifier;yourself) load
结论:
? 当数据库结构改变了,只要改变一个地方;
? 属性名和数据库表字段名无需一致;
? 新进入项目的开发人员很容易对应库表字段名和属性名;
? 随着数据库和域对象演进,属性映射方法需要维护。
相关或交互模式:
? 在映射值到数据库和从数据库映射值都需要进行类型转换;
? 当向持久层请求一个调用来读取和写入数据库时,要生成属性映射方法所需的SQL代码;
? 元数据能够和一个Schema一起,用来定义属性映射,或者有可能使用一个翻译器来生成实际的映射。
已知应用:
? Illinois Department of Public Health TOTS和NewBorn Screening 项目;
? ParcPlace的VisualWorks Smalltalk[OS 95]使用属性映射方法,用以定义如何处理属性和数据对象之间的映射。VisualAge Smalltalk[VA 98]也在他们的AbtDbm*应用系统中使用属性映射方法。
? JDBC中的ResultSet类是一条数据行,他的方法如getInt(), getString(),getDate()为属性映射工作,同时也是读取器的类型转换。在JDBC中映射回数据库,PerparedStatement类构造SQL语句,并以问号‘?’作为参数的占位符,并有一组setInt(), setString(), setDate()等等。
? GemStone GemConnect将数据库字段映射到对象属性中。
类型转换
别名:
数据转换
类型翻译
动机:
数据库值类型并不总是和对象类型直接对应,例如,一个布尔值也许在数据库存成T或者F,在Patient例子中,性别可以是一个属性,以一个名为Sex的类存储,男性实例的某些行为,而女性实例有另外不同的行为,在数据库中也许他们的值是M和F,当从数据库读取这个值,M需要转换成一个Sex类的男性实例,F需要转换成Sex类的女性实例。类型转换允许对象值和数据库值之间的转换。
问题:
如何将一个没有对应数据库类型的对象映射到一个数据库类型,并反之亦然?
特定约束:
? 数据库中的值也许不能映射到指定的对象类型上;
? 对象类型和数据库类型之间存在着阻抗不匹配;
? 应用程序中的值可以被其他应用程序在数据库中编辑和存储;
? 对象属性和数据库字段值能够都存成字符串和数字,这样就减小了阻抗不匹配;
解决方案:
通过一个类型转换器对象把所有值转换成各自的类型,这个对象知道如何处理空值以及其他对象值和数据库值之间的映射。当一个对象从大型多应用数据库被持久化,数据格式会多种多样,这个模式确保了从数据库中获取的数据能适合于对象。
确保从数据库中读取的数据能够为对象工作是很重要的,同时从对象写入数据库的数据遵从数据库规则和维护数据的一致性也是非常重要的。
每个对象属性通过适当的类型转换器传递,为特有的应用系统和DBM应用必要的数据规则,在域级别应用的数据规则比在接口级别中应用的要高效得多,这通常是由于所有的域对象都使用一组共同的类型转换。
想象一下有些旧的数据库没有空值(NULL)的概念,它们为“无数据”的情况实际上存储一个空字符串,当读出这个值,返回一个对应用程序表示“空白数据”的空字符串,他依赖于数据库和该应用程序的规则定义。
这个类型转换可以在映射代码中直接完成,数据类型将被转换成适当的对象类型,或者反之亦然,通常,一组共通的转换可以抽象出来。例如,一个Boolean对象可以映射数据库中的T或F,Timestamps能够映射到String上,一个NULL可以映射到一个空字符串。当你有了这些共通的转换,就可以调用适当的例程为转换预处理类型,这些转换例程形成了策略(Strategy) [GHJV95]的一部分。
根据你的需要,实现是多种多样的,下面的例子中,将所有的转换方法放置在一个对象中,这使方法都存在于一处,如果有必要,允许动态地切换转换对象。这样,也能够用一个策略,为不同数据库应用不同转换算法,如果余下的应用中,转换器不再需要,将是一个更清洁的方式。
另一个选择将扩充每个受影响或被使用的基类,每个对象将知道如何将他们转换成数据库必须的格式,假设你使用了多个数据库,那么每个方法都需要适应这个格式之间的差异。
还有一个方式,将你所有的转换例程放在PersistentObject中,如果你需要映射到一个新的数据库或是转换改变了,就隔离出不得不修改代码的地方。这个方法存在于任何从PersistentObject继承而来的对象,类似前面一种选择,当你有多个数据库时,情形是相似的。
所有提到的这些方法都可以独立于所选的持久机制而工作。
实例实现:
当你从一个数据库中字典结构的一行值产生属性时,可以简单地使用:
attribute := (aRow at: key).
这可以完成任务,然而,如果数据库值不能保证符合对象所需,那么你使用该属性的代码将失败,当你应用了类型转换,如:
attribute := self typeConverter convertToUpperString:
(aRow at: key).
这个属性值将是应用程序所需的,这会先得到负责转换的类,然后把数据库值传递到一个方法中,确保产生一个大写字符串的属性值。
把准备对象的属性值存储到一个数据库的情形是相似的,你可以简单地将属性值放入一个字符流。
nextPutAll: (attribute) printString.
这也可以完成任务,然而,如果碰巧一个对象不知道printString,那么这个代码将会失败。should the database … a conditional statement. 当你应用类型转换,如:
nextPutAll: (self typeConverter prepForSql:
(attribtute asUppercase)).
属性将被转换成适当的格式,如上所述,负责转换的类被得到并且属性将被转换。
类型转换方法通过PersistentObject访问,既可以准备存入数据库的值,也可以将数据库返回的行映射成对象属性。initialize:和insertRowSql:方法(在每个域对象中)展示了类型转换的例子。
Protocol for Type Conversion PersistentObject (instance)
这个方法决定哪一个类负责为表类型和对象类型转换类型,这个方法可以延伸为,在运行期决定使用哪个数据库或使用哪个类来转换类型。
typeConverter
“返回负责类型转换的类”
^TypeConverter
Protocol for Type Conversion TypeConverter (class)
这些方法为PersistentObject提供一致的格式化的数据值,当从对象向数据库转换时(TypeConverter>>prepForSql:),根据数据库需要来决定和格式化类型;当从数据库向对象转换时,数据库的类型也许不是对象/应用程序所要的,在属性映射方法中,每个属性经过类型转换以确保数据值是正确的。在有些情况下,当数据库不包含数据时,提供一个缺省值。当若干个不同实现的应用程序使用同一个数据库时,数据规则在数据库级别并不需要强制遵从。
convertToBooleanFalse: aString
“从一个字符串返回一个布尔值,非值为默认值。”
^’t’ = aString asString trimBlanks asLowercase
convertToString: aString
“从一个数据库字符串或字符返回一个字符串,缺省值是一个新字符串。”
^aString asString trimBlanks
convertToNumber: aNumber
“从一个数据库数字返回一个数字,缺省值是0。”
^aNumber isNumber ifTrue: [aNumber asInteger] ifFalse: [0]
这个方法把一个对象转换成正确的数据库格式,放在一个字符流中,对象被测定为什么类型后返回适当的格式,形成SQL代码放置在字符流中。这为持久层数据类型提供了一个共通的格式。本例中缺省的日期格式假设为(本地当前时间:’%m%d%Y’)。如果你不想使用一个完全日期格式,日期的格式应该根据你的数据库修改。注:这些格式类型被IBM DB2 UDB V5.0支持。
prepForSql: anObject
“以字符流的形式返回具有适当格式的对象。”
anObject isNil ifTrue: [^’NULL’].
anObject isString
ifTrue:
[anObject isEmpty
ifTrue: [^’NULL’]
ifFalse: [^anObject trimBlanks printString]].
anObject isNumber ifTrue: [^anObject printString].
anObject abtCanBeDate ifTrue:
[^anObject printString printString].
anObject abtCanBeBoolean ifTrue:
[anObject ifTrue: [^’T’ printString]
ifFalse: [^’F’ printString]].
anObject abtCanBeTime
ifTrue: [^self databaseConnection databaseMgr
SQLStringForTime: anObject].
(anObject isKindOf: PPLPersistentObject)
ifTrue: [anObject objectIdentifier isNil
ifTrue: [^’NULL’]
ifFalse: [^anObject objectIdentifier printString]]
结论:
? 能帮助确保数据一致性;
? 对象类型可以有很多种,和数据库类型无关;
? 可以替从数据库读出的空值赋缺省值;
? 阻止“不理解未定义对象(Undefined object does not understand)”的错误;
? 为应用程序提供增强的RMA(可靠性、可维护性和可访问性);
? 转换类型需要花费时间,特别是从数据库读取大量的值时;
相关或交互模式:
? 策略[GHJV 95]可以用来实现这个模式;
? 当构造SQL代码时,属性映射方法调用类型转换;
? SQL代码描述可能嵌入类型转换的调用。
已知应用:
? Illinois Department of Public Health TOTS和NewBorn Screening 项目;
? ObjectShare的VisualWorks Smalltalk[OS 95]使用类型转换来在数据库类型和对象类型之间转换。VisualAge for Smalltalk也在他们的AbtDbm*应用程序中使用类型转换。
? GemStone GemConnect在数据库类型和对象类型之间转换;
? TopLink也提供类型转换。
变更管理
别名:
HasChanged
IsDirty
Laundry List
对象管理器
动机:
通常使用一个病人管理系统的方法是为病人调出他的记录和为最近拜访的病人增加一条记录。但是有时候病人的地址已改变了,如果发生了实际改变,系统应该只写回病人的地址。
实现这个情况的方式之一是提供一个单独的改变地址的画面,一个单独的更新按钮用来将地址写回数据库,但这很笨拙并需要维护大量代码;更好的方法是,让病人管理系统的用户在必要时编辑地址,并让系统只写回地址对象的变化和其他用户决定要写回的值。
总的来说,一个持久层应跟踪所有PersistentObject的变更状态,并应确保他们都要写回数据库中。
问题:
如何判断一个对象改变了,且需要保存入数据库?防止对数据库不必要的访问,确保用户知道什么时候一些值被改变了并在退出程序前没有被保存是很重要的。
特定约束:
? 大多数对象读出来以后从没修改过;
? 保存没有改变的对象是浪费时间;
? 开发人员经常忘记保存一个修改过的对象,而用户更糟;
? 如果对象的每一个修改都写入数据库的,那么,为了取消用户的请求,就需要另一个写入或回滚操作;
? 复杂对象也许只有一个部件修改了,那无需将它所有的值都写入数据库;
? 将没有被修改的对象写入数据库,将难以稽核到底是谁最后修改了这个对象;
解决方案:
设置一个变更管理器,来跟踪任何PersistentObject修改了某个持久属性,无论何时,请求保存对象都需要这个变更管理器。
实现它的方式之一是从PersistentObject继承一个类,它有一个脏位,一旦一个映射到数据库中的属性值发生改变就被置位。这个脏位通常是一个布尔值实例变量,表明一个对象是否改变。当这个布尔值设定了,一个保存操作调用时,PersistentObject将保存新值到数据库中,否则,PersistentObject将忽略写入数据库。
洗衣列表(laundry list)也是一个用来保存数据的模式,它通过将变更存储在一个洗衣篮中工作,然后你能够控制对它们做什么,另外它还跟踪哪些属性被改变了,从而只保存脏属性。这样,如果一个应用程序改变了一个表的若干字段,而另一个应用改变了其他字段,你能确保只更新你所改变的字段,他也能够有助于应用程序并发的修改数据库表。
根据类体系的不同,实现方案有很多种。一种方案是修改属性设置(setter)方法,可以在对象值修改时设定一个标志,也可以把这个对象加入到已变更对象的洗衣列表,这非常简单却很有效。另一个方案可以使用类似于方法包装(method wrapper)[Brant, Foote, Johnson, &Roberts 1998],在属性设置方法中做同样的事情。还有一种方案,初始化持久属性成为一种依赖性机制,一旦一个属性值被修改了,可以设置脏位也可将对象加入洗衣列表,并删除依赖性;一脏永脏。另外一种实现方法是使用元数据来描述所有的持久属性,无论何时改变了对象的状态,都能够使用元数据来决定对象是否变脏了,方法包装能够使用这个元数据提供类似的服务。
数据访问一般非常昂贵,应该节约使用,通过标志一个对象是否需要写入数据库将显著提供性能。除了性能的考虑,也有助用户界面在退出前提示用户保存,这个功能使用户更容易接受你的应用系统,这能让他们知道自己忘记保存了已变更信息,而系统会提示他们保存。用户将形成一个结论,如果他们不得不重复输入同样的数据,这个系统便很快没有价值了。
变更管理器的另一个特性是提供对象的初始状态或改变状态的记忆功能,这可以通过Memento[GHJV95]来实现,如果你系统的用户需要回到初始状态,变更管理器能够保留初始值,通过调用一个撤销操作完成。同时,你也还可以为你的系统提供多步撤销操作。
如果你有一个对象,它的某个属性是其他对象的一个有序集合,(在本例中,Name的属性地址可以是Address类的OrderedCollection),当你删除一个Address的实例,数据库如何得到删除数据库行的消息?一种方法是将该实例的键值设为nil,然后,域对象提供一个isValid方法,判定删除特定行,这个方法可以实现,但是应用系统程序员不得不用特定的代码处理所有nil实例。一个更好的方式是使用一个删除管理器(Deletion Manager),当用户按下删除按钮(或其他机制),应用系统程序员把删除的实例放置其中,因为每个对象知道如何删除它自己,该实例会从集合中和数据库中被删除。删除管理器是一个Singleton[GHJV95]对象,它保留被删除的实例,直到用户发出保存或取消操作。
实例实现:
本例将展示一个存取器(accessor)方法如何为Name类的首名属性在修改值时设置脏位,这个访问者方法在VisualAge中缺省生成了附加的makeDirty调用,它将将继承的isChanged属性设置为真值。
first: aString
“保存首名值。”
self makeDirty
first := aString
self signalEvent: #first
with: aString
Protocol for Change Manager PersistentObject (instance)
这些方法为持久层提供改变脏标志的功能,这避免了持久层不得不向数据库写入没有改变的数据,同时也向GUI程序员提供一个测试对象的方法,以便向用户提供是否保存数据的提示信息。
makeDirty
“表明一个对象需要保存入数据库,如前面的例子中,这个方法可以在setter方法中调用。”
isChanged := true.
makeClean
“表明一个对象不需要保存入数据库或者对象没有被改变过。”
isChanged := false.
结论:
? 用户会更乐意接受这个应用系统;
? 不写入没有被改变的数据到数据库,可以保证数据库有更好的性能;
? 当在数据库间融合数据,可以设定该标志,这样这个记录在必要时将插入新的数据库中;
? 相关或交互的模式:
相关或交互模式:
? 状态(State)[GHJV 95]是一个使用布尔值标志的替代方法;
? Memento可以被变更管理器用来支持撤销操作;
? 洗衣列表能够跟踪所有改变了的对象;
? 可以使用删除管理器辅助删除复杂对象的一部分;
? 对象管理器[Keller 98-2]是一个非常相似的模式。
已知应用:
? 操作系统为虚拟内存使用脏位;
? 大多数DBMS在高速缓存中使用脏位[Keller 98-1];
? 高速缓存一般都使用脏位;
? Illinois Department of Public Health TOTS和NewBorn Screening项目;
? 在GemStone OODBMS中,使用一个变更管理器来跟踪一个对象何时被改变了,因此可以知道一个对象何时需要保存到服务器。
? ObjectShare的VisualWorks Smalltalk[OS 95]使用变更管理器指明一个对象值是否被改变过。VisualAge Smalltalk也在他们的AbtDbm*应用系统中使用变更管理器。VisualAge为GUI构建者提供图形化联接,以提供一个持久机制。
OID管理器
别名:
唯一键值生成器
动机:
只要一个对象被持久化,对象的唯一性是很重要的。在一个面向对象系统中,所有对象都是唯一的,所以给定每个对象一个唯一的标识是非常重要的,它通常称作OID。OID管理器确保为所有对象生成唯一的键值并存储到数据库中。
问题:
我们如何确保把每个对象唯一保存在数据库中,而不管是否和其他对象共享相似的状态?
特定约束:
? 您不会希望在一个数据库中改变键值和重复键值,数据库管理员认为这是非常糟糕的事;
? 增加id有时是人工劳动(artificial),通常需要在表中增加附加的字段;
? 为分布式数据库创建一个唯一键值;
? 为SQL代码明确地标识一条记录而创建一个唯一键值。
解决方案:
提供一个OID管理器,为所有需要存入数据库的对象创建唯一键值,确保所有新创建并需持久化的对象都能得到一个唯一的键值。当一个新对象需要持久化,它将被写入数据库并且有一个唯一的标识生成,这个生成过程要求非常快速且要求确保标识的唯一性。
一种方案是生成随机数,一旦生成一个数,必须检查它是否已经使用。不过当在多个数据库运行时,无法从本地获知,所需时间增加,而且当从多个数据库融合数据时,键值重复的可能性更大了。
另一个方案是在本地表中存放最后使用的数字,并和一个本地且唯一的键值合并起来,这需要每个键值都读取、写入键值表。
一个更好的方法(本例中使用的)是前面一种方法的变种,可以减少将每个键值都写入表的需要[Ambler 97]。当需要一个键值,向一个singleton实例请求,如果这个实例中没有任何数字(例如第一次写入),就从一个表读出一个数字段。一旦返回这个数字,它将立即增加一个特定数(应用程序指定),并写回数据库,给下次其他用户访问用。这个数返回给调用对象并增加1,存储在内存中直到下次需要一个键值。当这个段的数字都用完了,将重新读入一段并重复上面的过程。
可以使用一个键值生成策略来创建这些键,一个数据库或站点可以使用一种算法,而另一个可以使用其他算法,重要的是键值在表中是唯一的,最好在整个数据库或多个数据库中是唯一的。
有些数据库有生成唯一键值的方法,需要强调的是如果你有多个服务器,生成算法不能冲突。你也可以使用一个TCP/IP地址和/或硬盘序列号,跟上其他数字,以确保对象标识的唯一性。同时,有些数据库有生成一序列数字的方法,可以用来作为OID,不管您使用什么算法,确保线程安全是非常重要的。
注:将这个和Kellers和Browns模式语言中的Unique Key模式联系起来。
示例实现:
OID管理器为持久层提供域对象的唯一标识,这个标识可以作为数据库的键值。OID管理器维护一张表,表中有一个数,当它不能向持久层返回一个合法键值时,OID管理器增加这个数并写回表中。本例中,当它没有一个合法数字时,从表中获取一段数字维护,直到数字超过写回表的数。本例中段的大小为10(见下面的increment方法)。
Protocol for Accessors OIDManager (instance)
这个方法返回一个值,这个值是当需要一段新数字时,从数据库获取的数字段的大小。它可以被应用系统在启动和不想再设为10的时候设置。不懂
increment
“返回增加的值。”
(increment isNil)
ifTrue:[increment:=10].
^increment
Protocol for Key Generation OIDManager (instance)
这是本模式的核心方法,从表中读出一个字段值,所有用户访问数据库都使用它。当读取一个值,它立即加上increment属性中存放的值,这个值缺省为10,新数值接着被写回到表中以被下一次使用和下一个用户获取。这个值初始读出并存放在属性中,必要时进行操纵以提供唯一数值,这个数将附加上站点(或数据库)的键值,以创建一个唯一的14或15位数字的数。
readKey
“生成一个唯一键值,使对象存放入数据库中”
| newKey aQuerySpec aResultSet aMaxKey prep |
PersistenceObject beginTransaction.
aQuerySpec := AbtQuerySpec new
statement: ‘ SELECT NUM_SEQ FROM SEQUENCE ‘.
aResultSet := PersistenceObject databaseConnection
resultTableFromQuerySpec: aQuerySpec.
aMaxKey := aResultSet first at: ‘NUM_SEQ’.
newKey := aMaxKey + self increment.
PersistenceObject
executeSql: ‘UPDATE SEQUENCE SET NUM_SEQ = ‘, newKey printString.
PersistenceObject endTransaction.
prep := self class siteKey * self keySize.
self lowKey: prep +aMaxKey.
self highKey: prep + (newKey -1).
^nil
Protocol for Key Retriever OIDManager (instance)
这是获取一个键值的方法,检查这个属性,看是否需要通过上面的方法读出一个数,或是仅仅为这个单一实例增加1并返回它的值。
getKey
“这是获取一个键值的方法。”
self currentKey =0 ifTrue: [self readKey].
self currentKey = self highKey
ifTrue:
[self readKey.
^self currentKey].
self currentKey: self currentKey + 1.
^self currentKey
结论:
? 当写回数据库表时总是增加数字将浪费数字值;
? 当写回数据库表时,如果数字增加不足,将会消耗时间;
? 唯一的单一字段键值可以提高性能,并使SQL编码更简单、更易抽象。
相关或交互模式:
? 一个OID管理器是一个单一实例,所有的持久对象在一个共同的地方生成他们的键值;
? 可以使用一个策略来生成键值。
已知应用:
? Illinois Department of Public Health TOTS 和NewBorn Screening项目;
? 所有OODBMS都使用一个键值生成算法来为保存的对象创建唯一键值;
? PLoP Registraion使用Microsoft Access序列数据库命令来生成唯一键值;
? 在DCOM中,每个接口在运行期通过他们的接口标识(IID)来识别。IID是DCOM为接口生成的一个全局唯一标识(GUID)。GUID有128位,由DCOM API函数CoCreateGuid生成,这个API调用依照由OSF DCE指定的算法,它使用当前日期和时间、网卡ID和一个高频度计数器。基本上,你可以使用工具(例如Microsoft Developer Studio)来获得这些GUID并将他们放入你的DCOM IDL。
? CORBA2.0拥有联合的接口仓库――在多个ORB之间操作的仓库。为避免命名冲突,仓库为全局接口和操作分配唯一的ID(CORBA中称作仓库ID)。一个仓库ID是一个字符串,有三个层次组成,CORBA2.0定义了两个格式:
i) IDL名称有一个唯一的前缀,它的部件组成是:一个IDL字符串,跟着一个由’/’分隔的标识符列表和一个主辅版本号。通过’:’分隔的第一个标识符是一个唯一前缀――java使用同样的方式。例如:
IDL:JoeYoder/Foo/Bar/:1.0
JoeYoder是唯一前缀
Foo是一个模块
Bar是一个接口
ii) DCE通用唯一标识符(UUID),它使用DCE提供的UUID生成器生成――例如DCOM。它的部件通过’:’分隔,第一个部件是DCE字符串,第二个是UUID,第三个是一个版本号(没有辅版本号)。例如:
DCE:100ab200-0123-4567-89ab:1
事务管理器
别名:
工作单元
事务对象
动机:
保存对象的过程中,允许对象在某些值不能正常保存时,能以某种方式保存是非常重要的,先前存储对象能够被回滚。在病人例子中,你不仅只存储Patient对象的属性,还要存储它包含的变化过的address对象,如果试图保存任何一个病人的地址对象失败了,你想回滚保存该病人信息时所有的写入数据库操作。一个事务管理器提供开始事务、提交事务和回滚事务的支持。
问题:
如何向数据库写入一组对象,当任何写入失败时,将没有任何对象写入。
特定约束:
? 对象之间通常以某种方式联系起来,如果一个对象没有正常保存,那您就不想保存相关的对象;
? 知道哪些消息是事务,哪些不存在阻抗不匹配;
? 每个向数据库的写入操作都可以设定为一个单一事务;
? 复杂对象能够构造一个复杂的SQL语句,它包含事务处理,可以看作一个工作单元。
解决方案:
构建一个和其他事务管理器类似的事务管理器,这个管理器允许开始事务、结束事务、提交事务和回滚事务。事务管理器通常映射到RDBMS的事务管理器,如果它提供的话,所有流行数据库都内嵌了事务管理器,最好是使用它们提供的。
为了性能的原因,也许最好缓冲数据,这种情况,事务管理器有提交和回滚缓冲值的功能是非常重要的。如果你映射的数据库不支持事务管理器,那么你有必要在开始事务时保存对象的初始状态,这样当请求回滚时,初始值能够写回数据存储。
示例实现:
没有事务管理,你将使用如下形式:
anObject save.
这将提交每条发送到数据库的SQL语句,如果在保存anObject过程中发生了某种错误,你将在数据库中留下部分anObject,特别当anObject是一个复杂对象时。
当你使用事务管理,基本上你将anObject构建的所有SQL语句包装起来,告诉数据库,要不保存所有,要不什么都不干,这看起来如下所示:
beginTransaction
anObject save
anotherObject save
endTransaction
这确保在向数据库提交改变前,所有的保存命令都能成功执行。当你的对象是复杂对象,它知道如何保存他的聚合对象,确保将完整的对象写入数据库中。
下面的代码是从PersistentObject摘录,它们展示了实现事务管理的包装结果,代码(self class beginTransaction)告诉数据库开始和停止一个事务,它依赖于你所使用的数据库和你所用的开发语言。你也许需要扩展事务以处理你特殊的实现,同时,如果你保存的数据库(可能只是一个文本文件)不支持事务,你将不得不开发一个完整的事务管理器以支持用户的需要。本例中将所有保存和删除对象操作包装在一个beginTransaction和一个endTransaction之中。类方法进行数据库联接类的调用,这是VisualAge为它支持的数据库提供提交和回滚事务的地方。
Protocol for Public Interface PersistentObject (instance)
save
self class beginTransaction.
self saveAsTransaction.
self class endTransaction.
delete
self class beginTransaction.
self deleteAsTransaction.
self class endTransaction.
Protocol for Public Interface PersistentObject (class)
beginTransaction
self databaseConnection beginUnitOfWorkIfError:
[self databaseConnection rollbackUnitOfWork]
endTransaction
self databaseConnection commitUnitOfWork
rollbackTransaction
self databaseConnection rollbackUnitOfWork
结论:
? 复杂对象要不完全保存,要不什么都不保存;
? 半个对象不能维护引用一致性;
? 所有其他写入数据库的应用系统不得不使用事务管理器,你也许不得不增加检查,看在你保存时,是否有其他什么人曾修改过数据库;
? 除非数据库中内嵌了事务管理的支持,写一个完整的事务管理器非常困难。
相关或交互模式:
? 事务管理器和事务对象[Keller 98-2]非常相似,事务对象通过在外面构建对象封装事务,这些事务对象提供开始、提交和回滚事务操作。
已知应用:
? 大多数数据库类应用系统提供类似的功能或时工作单元的定义;
? Illinois Department of Public Health TOTS和NewBorn Screening项目;
? VisualWorks在他们的ObjectLens中提供事务管理器;
? VisualAge也在ABTDbm*类中提供事务支持;
? GemStone GemConnect为数据库对象提供事务管理。
联接管理器
别名:
当前联接
数据库会话
动机:
只要一个持久对象被读出或是写入数据库,必须建立一个和数据库的联接。一个数据库事务需要的典型信息是数据库名、用户名和用户口令,这些信息可以在每次访问时向用户获取,这将导致失败的用户验证,因为大多用户不会知道数据库名或别名。你也可以在启动时获取用户名和口令,并在以后的代码中使用,建立联接信息,这导致在不需要的时候传递了大量多余信息。最好的方式是构造一个联接管理器,存放这些全局信息,并在任何需要访问数据库时使用。
问题:
持久管理器如何跟踪当前联接的数据库和联接用户?
特定约束:
? 所有数据库联接需要访问某个建立联接的地方;
? 引用全局变量可以保持代码简洁明了;
? 维护当前数据库会话,而不是为每个事务创建新会话将更有效且更易调试;
? 在一个地方提供必要的联接信息和操作可以使代码易于理解和维护。
解决方案:
创建一个联接管理器对象,存放用户数据库联接所需的所有数据值,共同的值通常是数据库会话、登录到系统的当前用户和其他用于稽核、事务和其他类似的全局信息。
当一个应用系统需要为某些信息只提供一份拷贝,可以使用Singleton模式[GHJV 95]或者使用一个单一活动实例和一个Session[Yoder &Barcalow 97],这个单一活动实例在Design Pattern Smalltalk Companion[MORE HERE 98]中有描述。Singleton通常存放在一个单一全局的地方,例如作为一个类变量或是类本身。不幸的是,这个模式在一个多线程、多用户或分布式的应用时,有时会被破坏。某些情况,需要一个真正的Singleton,而有的情况,每个线程或每个分布的进程可以看作一个独立的应用,它们每个都有自己的Singleton,但是当应用共享一个共同的全局环境时,这个单一全局区域不能被共享,这需要一个机制允许多重Singleton,每个应用一个。因此,联接管理器是管理任何和所用数据库会话的Singleton。
联接管理器和持久层交互,以让后者得到当前所需的数据库联接。联接管理器也和表管理器交互,为任何建立的联接提供所需的数据库表名。这样,可以再一次使用策略[GHJV 95]模式来选择适当的数据库和表映射。想象一下你可能将你的值保存到五个数据库中,为了速度的考虑,你将选择一个负荷最小的,再用一个批处理过程以一个主数据库同步所有库。这个分布式的数据库系统通过一个策略模式方法,确保用户能够得到一个理想的性能。
示例实现:
基于从表管理器得到的信息,联接管理器建立和数据库的联接。当持久层请求一个联接,联接管理器利用数据库部件通过ODBC、CLI或其他可能的方式向数据库提供一个接口。一旦当时不能得到联接,或中途中断了,联接管理器提供错误块来进行错误处理,并提供错误收集以记录错误,如有可能就进行恢复。
简单的说,当一个域对象说:
self databaseConnection
就从联接管理器返回联接,联接类型和哪个联接(如果使用了多个联接)由联接管理器决定。
在我们的例子中,既选择了本地的,也选择了远程的数据库。我们展示了您将如何从VisualAge和ABTDbm*类交互,以得到本地数据库的联接。
Protocol for Public Interface ConnectionManager (class)
databaseConnection
“检查局部变量,看建立什么联接,或者看返回什么联接。”
^self getLocal
ifTrue: [self localConnection]
ifFalse: [self remoteConnection]
localConnection
“返回一个联接给PPLPersistentObject,检查别名看是否已经打开了一个联接,如果没有,创建一个,并提供错误处理,处理联接和联接打开时的错误。”
| connection |
(connection :=
AbtDbmSystem activeDatabaseConnectionWithAlias:‘Example’) isNil
ifTrue:
[connection :=
((AbtDatabaseConnectionSpec
forDbmClass: #AbtOdbcDatabaseManager
databaseName: ‘Example’)
promptEnalbled: false;
connectUsingAlias: ‘Example’
logonSpec: (AbtDatabaseLogonSpec
id: ‘’
password: ‘’
server: ‘’)
ifError:[:error|PPLErrorCollector dbConnectionError])
autoCommit: false;
yourself].
“如果开发环境没有使用错误块,需要提供调试器,在运行期错误块设定为调用错误收集器,它为管理器处理所有dbm类错误,上面的错误块是特定于联接的。”
connection databaseMgr
errorBlock: (System startUpClass isRuntime
ifTrue: [[:error | PPLErrorCollector dbmError:error]]
ifFalse:[nil]).
^connection
结论:
? 联接管理器为所有持久对象提供联接信息;
? 当联接信息改变时,只需在一个地方修改;
? 它提供一个支持多联接的方式,可以用于从数据库装载一个对象,或平衡数据库的负荷。
相关或交互模式:
? 在多线程、多用户或分布环境中,联接管理器是Singleton的替代方法;
? 联接管理器和会话相似,它维护和数据库的会话以及和数据库联接相关的全局信息。
? 联接管理器可以使用一个策略来选择当前联接;
已知应用:
? 对VisualWorks,Lens Oracle框架和GemStone的GemBuiler分别有OracleSession和GbsSession,他们都存放事务状态和数据库联接的信息,这个联接管理器在同样的数据库环境中被任何对象引用;
? Caterpillar/NCSA Financial Model Framework有一个FMState类[Yoder 97],当作一个Session并维护联接管理器;
? VisualAge有AbtDbmSystem,维护活动联接的轨迹,联接管理器调用VA类,依次控制物理联接。
? Illinois Department of Public Health TOTS和NewBorn Screening项目。
表管理器
别名:
数据字典
表映射
动机:
随着时间发展,对象对应的持久存储也许会发生变化,或者对象有多个存储。一个表管理器描述了数据库中表和字段的结构,让开发人员远离这些细节,从而做到改变数据库的命名结构却不影响应用开发人员。
问题:
一个对象如何知道使用什么表、什么字段,特别是对象需要存入到多个表中时。当使用多个数据库时,又会多出一个数量级的问题。
特定约束:
? 将对象映射到关系型数据库,最终需要将对象值映射到数据库表中;
? 当应用系统扩大和修改时,开发人员希望能够快速修改表名;
? 将对象在不同地方,以不同名称映射到同一个表;
? 很容易地从一个数据库切换到另一个;
? 在描述SQL代码的地方直接硬编码表名和字段名非常直接明了。
解决方案:
提供一个地方,让对象获取必要的表、字段名以存储自身。当一个对象被存储,在表管理器中查找他的表名。通过只在一个地方定义名称字符串,更改和测试修改变的非常迅速和高效。
这个模式使用一个Sigleton[GHJV 95],将所需的表或字段名称返回给域对象。这个单一实例包含字典结构存放名称,当一个对象发出请求名称的消息,该实例的方法就通过联接管理器检查,决定使用那个字典,使对象可以发送相同的消息,而不管它必须访问那个数据库。
当从多个数据源获取数据,这个模式提供动态改变所访问数据库或表的能力。它灵活地减轻了为多个数据库的相同表一遍一遍编写相同的SQL代码描述的工作,而且仍然可以访问它们。
表管理器在某种意义上,为表映射存放元数据,这个元数据应用于任何一个需要表名的时候,它可以用来动态生成数据库查询。基本上,一个Schema描述了这个映射,每当访问数据库时都需要使用它。
示例实现:
表管理器在字典结构中存放表名,在被请求时提供给SQL代码,当表管理器初始化时,字典结构用表名初始化,然后,根据联接管理器,访问适当的字典并返回表名。
当一个域对象说:
self class table,
TableManager将为类返回表的名称。
结论:
? 使用表管理器的一个好处是,当一个表名修改后,代码中只有一个地方需要修改;
? 另一个好处是,可以用不同的名字访问不同数据库的相同表或视图;
? 编写一个表管理器包括要有一种方式解释表和字段的映射,这并不是很容易开发或维护的。
相关或交互模式:
? 只要有访问数据库的需要,持久层和联接管理器将调用表管理器;
? SQL代码描述将使用表管理器,以将开发者和数据库的变更隔离开;
? 表管理器是一个Singleton。
? 表管理器实际上只是一个用元数据描述数据库结构的方式;
? 表管理器能够为复杂映射使用一个翻译器或是为动态系统使用元数据。
已知应用:
? Illinois Department of Public Health TOTS和NewBorn Screening项目;
? 很多数据库系统都使用数据字典;
? VisualWorks ObjectLens使用一个Spec[Foote & Yoder 98],结合Schema来提供表映射。
综合讨论:
现在你已经看到所有的模式,你也许会问,“我如何综合起来用他们?”。所有这些模式一起协作提供一个持久对象映射到数据库中的机制。图2展示了模式之间是如何交互的。持久层为所需持久化域对象的CRUD(创建、读取、更新和删除)操作提供标准接口,持久层使用域对象提供的SQL代码描述构建数据库调用,在生成SQL代码时,持久层和表管理器交互以获取正确的数据库表名和字段名。当已经从数据库返回数据值或是将数据写回数据库时,属性值必须映射到数据库字段名,反之亦然,这由属性映射方法完成。属性映射方法在SQL代码生成中进行某些类型转换。属性映射和类型映射在持久层实例化一个新对象时也会发生。持久层将一个对象发生变化的值通过联接管理器保存到指定的数据库中,这个变化的值由变更管理器管理;联接管理器能够和表管理器交互,决定使用哪个数据库。持久层在需要进行事务处理时提供对事务管理器的访问。
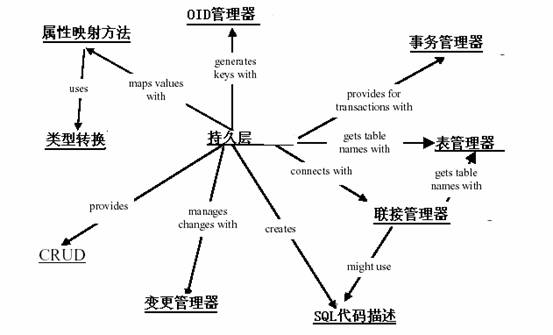
图2 - 模式交互图
一个类场景图(见图3)展示在我们例子中,当从数据库装载值时,对象是如何交互的。一个Name类可以请求load,这个消息将被转发到它的超类PersistentObject。它将从ConnectionManager得到一个联接,接着PersistentObject将生成SQL,为完成这个,他需要向Name请求这个SQL,并从TableManager得到一些表名映射,一旦生成SQL,一个Database Component调用将返回结果集,接着,对每条从数据库返回的行,创建一个新的Name对象,并将这个行的每个字段分配到特定的对象属性中,在映射数据库值到对象属性过程中,数据库类型将被转换到对应的对象类型。一旦完成,PersistentObject将返回一个已创建的Name对象集合。
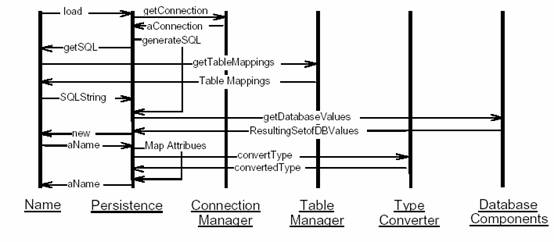
图3 - 类交互图
参考
| [Ambler 97] | Scott W. Ambler. Mapping Object to Relational Databases. URL: http:// www.AmbySoft.com/mappingObjects.pdf |
| [Beck 97] | Kent Beck. SMALLTALK Best Practice Patterns, Prentice Hall PTR, Upper Saddle River , NJ , 1997. |
| [Brant & Yoder 96] | John Brant and Joseph Yoder. "Reports," Collected papers from the PLoP '96 and EuroPLoP '96 Conference, Technical Report #wucs-97-07, Dept. of Computer Science , Washington University Department of Computer Science, February 1997. URL: http://www.cs.wustl.edu/~schmidt/PLoP-96/yoder.ps.gz. |
| [BMRSS 96] | Frank Buschmann, Regine Meunier, Hans Rohnert, Peter Sommerlad, Michael Stal. Pattern-Oriented Software Architecture: A System of Patterns, John Wiley and Sons Ltd., Chichester , UK , 1996. |
| [Foote & Yoder 96] | Brian Foote & Joseph Yoder. “Evolution, Architecture, and Metamorphosis,” Pattern Languages of Program Design 2, John M. Vlissides, James O. Coplien, and Norman L. Kerth, eds., Addison-Wesley, Reading, MA., 1996. |
| [Brown & Whitenack 96] | Kyle Brown & Bruce Whitenack. “Crossing Chasms: A Pattern Language for Object-RDBMS Integration,” Pattern Languages of Program Design 2, John M. Vlissides,James O. Coplien, and Norman L. Kerth, eds., Addison-Wesley, Reading, MA., 1996. |
| [Foote & Yoder 98] | Brian Foote & Joseph Yoder. “Metadata,” Submitted to PLoP ’98. URL: http://wwwcat.ncsa.uiuc.edu/~yoder/Research/metadata. |
| [Fowler 97-1] | Martin Fowler. Analysis Patterns: Reusable Object Models, Addison Wesley, 1997. |
| [Fowler 97-2] | Martin Fowler. Dealing with Roles, Proceedings of PLoP ’97, Monticello , IL, October 1997. URL: http://www.aw.com/cp/roles2-1.html. |
| [GHJV 95] | Eric Gamma, Richard Helm, Ralph Johnson, John Vlissides. Design Patterns:Elements of Reusable Object-Oriented Software, Addison-Wesley, Reading , MA , 1995. |
| [GemStone 96] | Gemstone Systems, Inc. GemBuilder for VisualWorks, Version 5. July 1996. URL: http://www.gemstone.com/Products/gbs.htm. |
| [GemConn 96] | Gemstone Systems, Inc. GemConnect for VisualWorks, Version 5. July 1996. URL: http://www.gemstone.com/Products/gbs.htm. |
| [Keller 97-1] | Wolfgang Keller: Mapping Objects to Tables: A Pattern Language, in “Proceedings of the 1997 European Pattern Languages of Programming Conference,” Irrsee , Germany , Siemens Technical Report 120/SW1/FB 1997. |
| [Keller 97-2] | Wolfgang Keller, Jens Coldewey: Relational Database Access Layers: A Pattern Language, in “Collected Papers from the PLoP’96 and EuroPLoP’96 Conferences” Washington University , Department of Computer Science, Technical Report WUCS 97- 07, February 1997. |
| [Keller 98-1] | Wolfgang Keller, Jens Coldewey: Accessing Relational Databases: A Pattern Language, in Robert Martin, Dirk Riehle, Frank Buschmann (Eds.): Pattern Languages of Program Design 3. Addison-Wesley 1998.
|
| [Keller 98-2] | Wolfgang Keller. “Object/Relational Access Layers - A Roadmap, Missing Links and More Patterns,” Submitted to EPLoP ’98. |
| [OE 98] | IBM, Corporation. Object Extender for VisualAge. 1998. URL: http://www.software.ibm.com/ad/smalltalk/about/persfact.html. |
| [Orfali & Harkey 98] | Robert Orfali & Dan Harkey. Client/Server Programming with Java and {CORBA}, 2nd Edition, John Wiley & Sons, 1998. |
| [OS 95] | ObjectShare, Inc. VisualWorks User’s Guide. 1998. URL: http://www.objectshare.com/vw30abt.htm. |
| [RSBMZ 98] | Dirk Riehle, Wolf Siberski, Dirk Baeumer, Daniel Megert, & Heinz Zuellighoven.Serializer, in Robert Martin, Dirk Riehle, Frank Buschmann (Eds.): Pattern Languages of Program Design 3. Addison-Wesley 1998. |
| [TopLink 97-1] | The Object People Inc.: TOPLink Version 4.0 - A White Paper, 1997. URL: http://www.objectpeople.com/. |
| [TopLink 97-2] | The Object People Inc.: TOPLink Version 4.0 - User Manual, 1997. |
| [VA 98] | IBM, Corporation. VisualAge Smalltalk. 1998. URL: http://www.software.ibm.com/ad/smalltalk. |
| [Yoder & Barcalow 97] | Joseph Yoder & Jeffrey Barcalow. "Security," Fourth Conference on Patterns Languages of Programs (PLoP '97) Monticello , Illinois , September 1997. Technical report #wucs-97-34, Dept. of Computer Science, Washington University Department of Computer Science, September 1997.URL: http://www-cat.ncsa.uiuc.edu/~yoder/papers/patterns/#YoderBarcalow1997. |
| [Yoder 97] | Joseph Yoder. A Framework to Build Financial Models. URL: http://www-cat.ncsa.uiuc.edu/~yoder/financial_framework. |
| [Yoder & Wilson 98] | Joseph Yoder & Quince Wilson. A Framework for Persisting Objects to Relational Databases. URL: http://www-cat.ncsa.uiuc.edu/~yoder/Research/objectmappings. |
| [You+ 95] | Joseph Yoder & Quince Wilson. Mainstream Objects, An Analyusis. URL: http://www-cat.ncsa.uiuc.edu/~yoder/Research/objectmappings. |














 1861
1861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









