






软件世界的一个基本安全原则是用户空间的代码(平民阶层,低特权)不可以访问内核空间(管理阶层,高特权),这几天进入公众视野的MELTDOWN漏洞之所以令人恐慌,就是因为它直接颠覆了这个基本原则。利用这个漏洞,黑客可以从用户空间中访问到内核空间中的信息。
下面通过一幅图来解说MELTDOWN漏洞的基本原理。下图左侧的汇编指令来自用于演示MELTDOWN漏洞的POC(proof of concept)程序,这个POC可以从普通用户程序中读取到内核中的linux_proc_banner变量。
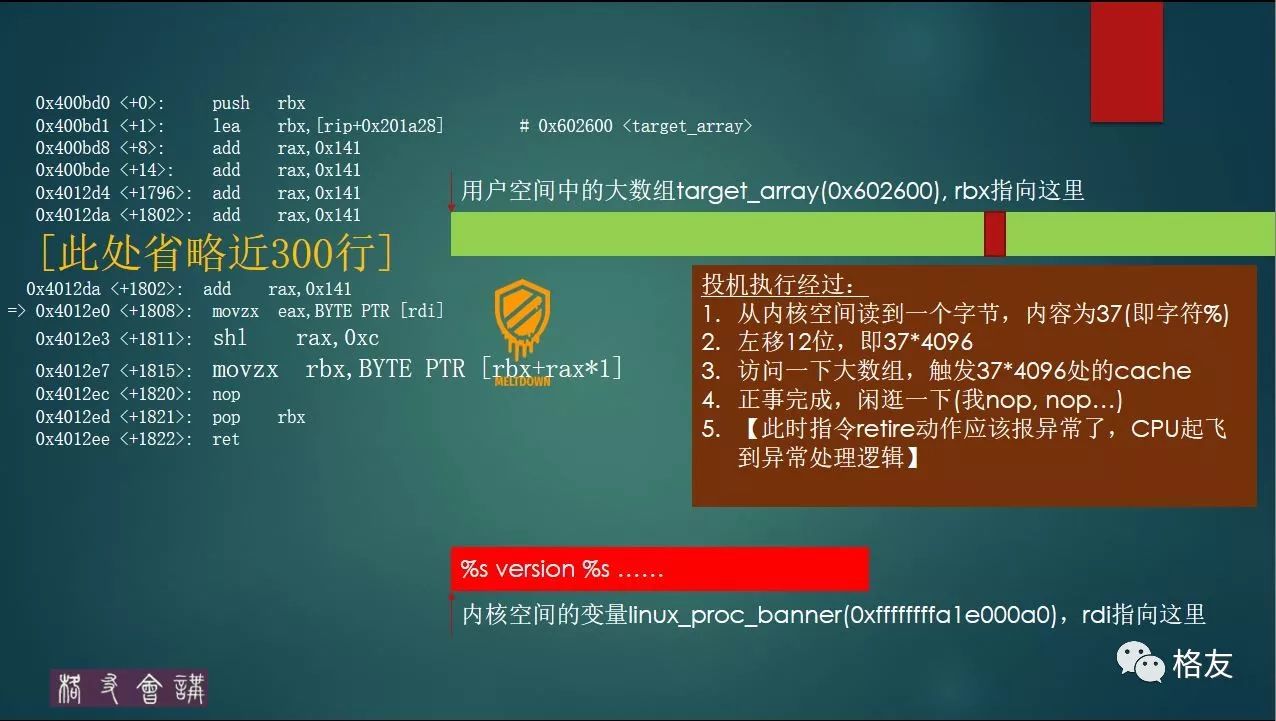
图左这点汇编来自名叫speculate的函数,意思为预测或者推测,其目的是欺骗CPU的乱序执行机制,利用其设计不足来窃取内核数据。
为了提高执行效率,很多现代处理器都采用所谓的预测执行机制,其核心是在处理器内部同时解码和执行多条指令,也就是不仅仅执行当前确定需要执行一条指令,而是尝试执行将来可能需要执行的多条指令。将来的事情谁也说不清,所以提前执行的指令未必有用。正因为此,这种执行方式一般被称为投机执行(speculative execution)。投机之名不太好听,所以最近很多文章使用了各种其它名字,预测执行,推测执行等等。本文仍使用投机执行。
这个speculate函数是攻击MELTDOWN漏洞的关键之关键,所以本文会详细解说每一条指令,条数不多,请大家耐心阅读。
第一条指令(0x400bd0)是函数入口的常规操作,保存函数内部将要使用的寄存器RBX(不区分大小写)。
第二指令是 (0x400bd1) 是把全局变量target_array的地址放到RBX寄存器中,以便后面使用。全局变量target_array是包含256*4096个字节的大数组,这个长度是精心设计的,256是因为一个字节(8 比特)的取值范围为0-255,即一共256个数。4096是x86架构下一个内存页的大小。
第三条指令(0x400bd8)开始的300条指令是一样的,都是一条加法指令,这里放300条,还是500条,差别不大,其目的只是让CPU内的投机执行机制高兴一下,“我的内心无比强大,我的厂房宽广无边,我偷偷的并行跑,一下子把很多条指令推上流水线,哦耶!”
不过,这一次,陷阱就在前头,图左的第8条指令(0x4012e0)是关键,摘录如下:
=> 0x4012e0 <+1808>: movzx eax,BYTE PTR [rdi]
这是x86架构中非常常见的一条指令,从RDI所指向内存读取一个字节,放到EAX寄存器中。但是不寻常的是,此时RDI指向的是高特权的内核地址,黑客挖坑在此。
按照基本纲领,这样的越权访问是公然冒犯内核权威,直接触碰红线,小小毛猴要摸如来佛的下巴,是要被一巴掌拍死的。
比喻是老雷加的,实际上,实现在晶体管中的逻辑是这样的:
1,根据页表项中的标志位(U/S),知道RDI对应的内存页是高特权
2,根据当前运行模式,知道当前代码是低特权
3,低特权代码不可以访问高特权数据,这是违例,要举报,通过异常机制移交给操作系统(最高法院)去定罪和惩戒不法之徒。
现在的问题是,CPU要在指令老化(retirement)过程中做上诉动作。虽然投机执行是乱序和并行的,但是老化过程必须串行,为了保证代码逻辑的正确性。
说时迟,那时快,就在CPU的老化过程还没有来得及报告异常时,并行流水线上已经跑完了这条访问内存的指令,把内核空间中的数据读出来了。读出来的值放入的是内部寄存器(老化阶段才会通过别名机制显现到架构层面的外部寄存器),我们这里不妨使用AX*来表示。有人问,CPU到底错在那里了?简单回答,就错在现在这一步,在投机执行时没有严格检查特权,允许越权访问发生,挖下祸根。
更糟糕的是,高速的并行流水线可能(速度相关,敏感处)还把下面的指令也执行了:
0x4012e3 <+1811>: shl rax,0xc
0x4012e7 <+1815>: movzx rbx,BYTE PTR [rbx+rax*1]
其中,shl是左移位,解码时rax会被重名为内部寄存器,也就是我们刚才说的AX*,正是从内核空间中读到的内容,对于本例,是37,即%的ASCII码,左移12位(0xc),相当于乘以4096,这个计算是为了算出一个数组偏移,为下一条指令做准备。下一条指令就是访问一下我们前面提到过的target_array打数组。在调用speculate函数偷数据前,已经故意冲洗过target_array的cache,即这个代码:
void clflush_target(void)
{
int i;
for (i = 0; i < VARIANTS_READ; i++)
_mm_clflush(&target_array[i * TARGET_SIZE]);
}
现在故意访问一下这个大数组中的一个字节,目的是触发CPU,让其缓存(cache)对应的内容,为后面通过测试cache温度而“显影”窃取到的字节做准备。
这条故意触发cache的指令是MELTDOWN攻击的第二个关键,重复如下:
0x4012e7 <+1815>: movzx rbx,BYTE PTR [rbx+rax*1]
它的作用是把窃取到的内容(AX*中,粗略看,即上面的RAX),以cache温度的形式编码起来。这个做法有个专门的名称,叫flush+reload。简单说,就是先冲洗一段内存区的cache,然后触发CPU“暗自”访问其中的一部分,再通过检查cache温度侦察刚刚CPU暗自访问的是哪个部分。
有人问,这里干嘛不直接把窃取到的字节写到内存变量里呢?因为投机执行的部分在老化阶段如果证明无用就会被抛弃掉。对于本例,按照代码逻辑,老化movzx eax,BYTE PTR [rdi]指令时就抛异常了,后面的所有操作都是会被抛弃的,不会显现出来。而cache温度则不然,这正是CPU设计之不足,此漏洞之关键。
之后,CPU报告页错误,跳转到操作系统的异常处理逻辑,开始处理异常,这也正在“黑客”预料之中,事先已经注册了一个信号处理器,即下面的代码:
void sigsegv(int sig, siginfo_t *siginfo, void *context)
{
ucontext_t *ucontext = context;
#ifdef __x86_64__
ucontext->uc_mcontext.gregs[REG_RIP] = (unsigned long)stopspeculate;
#else
ucontext->uc_mcontext.gregs[REG_EIP] = (unsigned long)stopspeculate;
#endif
return;
}
上面代码举重若轻的直接修改程序指针寄存器,把执行位置恢复到图左的倒数第三条指令,即:
0x4012ec <+1820>: nop
于是CPU又回到speculate函数中,继续跑了,单纯的CPU啊,完全不知道已经被黑客利用了。
随后,‘黑客’通过检查cache温度(访问大数组的速度不同),把前面隐藏的信息显影出来。
void check(void)
{
int i, time, mix_i;
volatile char *addr;
for (i = 0; i < VARIANTS_READ; i++) {
mix_i = ((i * 167) + 13) & 255;
addr = &target_array[mix_i * TARGET_SIZE];
time = get_access_time(addr);
if (time <= cache_hit_threshold)
hist[mix_i]++;
}
}
套路就是这样。
计算机系统中的BUG无穷,为什么这个如此吓人呢?因为问题出在CPU硬件之中,难以修正。硬件不好改,只好改软件。因为牵涉到基本的系统机制,软件改起来费劲了,基本的思路是让内核空间使用单独一套页表,这样投机执行时也读不到内核空间中的内容。但是,这样就需要频繁切换页表,TLB的价值大大受损,性能影响难以预估。2018年,IT圈忙甚。如果看官是坐在马桶上读此短文的,那么可能时间差不多了,如果坐地铁可能也快到站了,就此打住。
***********************************************************
正心诚意,格物致知,以人文情怀审视软件,以软件技术改变人生。
欢迎关注格友公众号















 617
617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









