







版权声明:本文为博主原创文章,未经博主允许不得转载
很早之前写的个人笔记,主要是对这个工程不理解的地方的注释“from rigid templates to grammars : object detection with structured models“。不是一篇介绍性的文章。论文作者的工程在http://people.cs.uchicago.edu/~rbg/latent/
1. 语法
1.1 bag grammar

1.2 更正式的定义

1.3 位置
加上位置后,对于物体检测,一幅图片的位置可以用(x,y,l)来表示,x代表横坐标,y代表纵坐标,l代表图像金字塔的层数

1.4 物体分解
根据以上的定义,我们可以讲一个物体分解成以下形式,其中subtype举个例子来说就是人有站着,坐着,躺着各个不同的模型,Y是代表不同的parts,人可以分解成脸,躯干,手脚等。其中人就是一个non-teminla symbol,脸也是,因为可以分解成了眼睛等,手脚可以当成一个Terminal symbols.

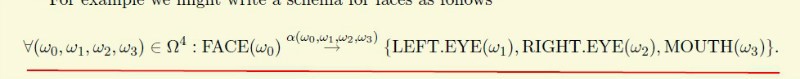
1.5 滤波器
评价一个Terminal symbols,我们可以用一个滤波器,A是teminal symbol.
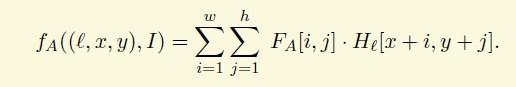
所以对评价一个普通语法,只要把所有的Terminal symbols的分数相加。alpha是一个bias,可以理解成先验,这条规则的代价
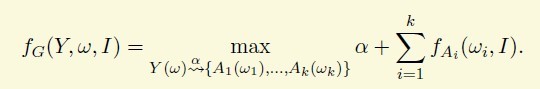
1.6 变形语法 isolated deformation grammars.
打个比方,每个人眼睛相对于脸的位置大概位置是差不多,但毕竟都不是一样。当我们的partfilter找到眼睛,但是连脸比较远,我们就得给一个惩罚,否则就会有falsepostive.
首先定义一个操作
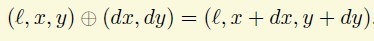
上面的语法第一条就是structural rule,下面的就是一个deformation rule
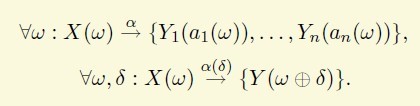
一个derivation tree 实例

1.7 detection with grammar models[5]
int(T)代表树的中间节点,leaf代表叶子节点,score就是对应滤波器的分
z不是特别懂,可以理解成各个T,NT的的位置信息的变量
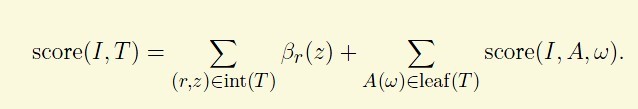
beta的含义,omega程序中取的是[0.01 0 0.01 0]

这个问题可以用动态规划来计算。
① 先对数的NT进行后序遍历
② 从前面的节点也就是从数的最小面的NT计算分。迭代算到root node就完事。
计算以上的一般把变形限制在4个HOG cell中(cascade程序中有更快的算法)
2 物体检测的HOG特征
2.1 Hog 参数
为了训练滤波器,采用HOG[6]特征,cell 为8*8,一个block 4个cell
2.2 直方图统计
对于每个cell,360°(20°一个区间,总共10个区间)统计之内的每个像素梯度的幅值,方向。每个像素的幅值对所处的周围4个CELL双线性插值,程序中的block代表cell

2.3 归一化
采用4个block同时归一化
一个cell带有32维的向量 前18个对应归一化的18个方向,接着9个是把对角的方向直接相加再归一化,然后4个是18个方向全部相加分别用其中的一个block归一。最后一维是备用的,为了处理image boundarytruncation features 还没理解透,以后再写


有一部分用到非极大值抑制,但没边缘检测那么烦,其实就是取最大值,而忽略其他的边缘检测非极大值抑制http://bbs.csdn.net/topics/370004267
3 SVM-LSVM-WLSVM
3.1 普通的SVM
网上有很多介绍,比如http://blog.csdn.net/v_july_v/article/details/7624837
3.2 SSVM
3.2.1 问题描述[1]

3.2.2问题转化
通过经验损失函数来度量[2]

加入松弛因子

由于我们的损失误差典型的都是非凸,不连续的函数,再次转换[3]

3.3 LSVM
直接给结论了,具体的推导忘了的话再看论文[3]

3.4 WLSVM[5]
定义如下。Lmargin程序中采的值样本正确就为0,否则为1.Loutput的检测框与实际框重叠率大于0.7则为0,否则为无穷。重叠率定义为(A∩B)/(A∪B)。它的意义论文讨论了一些,但不是很理解,最不能理解的是Loutput的位置为什么在那。怎么从平均风险推到这个式子,等以后基础再好点再来推推.

4 训练
(4.1) 检测框大小选择
由用户指定model的个数n,人有站着,躺着,训练数据库中是把一幅图片中的人用框画出来,所以对于不同的模型他们的长宽比有 区别的 。所以按照比例的大小排列分成n份。对其中的每一份训练一个filter.为了滤波器与训练集的框重叠率比较高,选的是从小到20%处的大小。
(4.2)数据准备等
(4.2.1)读入数据
为每个正样本创建一个左右翻转的图片。如果正样本有232,则加上翻转的464
(4.2.2)正样本扣图
假设滤波器大小为fsize7*11,则将图像中正样本的图扣出,并用双先线性插值缩放为(fsize+2)*sbin.(sbin 默认为8*8,一个cell的大小)。+2是求HOG特征归一化所要用的 warpos.m
(4.2.3) 对扣的图求HOG特征 feature.cc
(4.2.4)左右视图聚类 Kmeans聚类,每次只处理一个样本。lrspilt.m
处理完后为了防止局部最优解进行一个内循环,交换一个视图和相应的翻转图看是否目标值降低
(4.2.5) 训练前准备 内存准备,模型准备等。train.m及fv_cache中的c++文件
一个rootfilter现在包括7*11*32+1+3维的元素,其中的1是offset也就是bias,3是location(x,y,l).但是location是不用学习,所以学习的参数是2464+1。C是0.001
(4.2.6) 正样本包装-train.m->poswarp 把太小的正样本剔除,并加入一个不可信的entry。特征值为空.两者组成一个正样本。关键的标签是。loss就是los_margin.
很重要的一点,以前没注意到的就是在这里把bias加入到了feature中,
feat = [model.features.bias;feat(:)];%train.m 480行初始值为10
第一个
is_belief = 1;
is_mined = 0;
loss = 0;
第二个
loss = 1;
is_mined = 0;
is_belief = 0;
(4.2.7)负样本挖掘 train.m->negrandom
按照内存的限制和样本个数的数据,在没有图片中取负样本。同上,需要加入一个空项。由于我们的目标对于负样本w*f应该是越低越好,所有空项是可信的
带特征的:
is_belief = 0;
is_mined = 1;
loss = 1;
空特征的
loss = 0;
is_mined = 1;
is_belief = 1;
(4.2.8) CCCP转化为slave problem
(4.2.9) LBFGS拟牛顿法求解slave problem minConf_TMP.m
梯度法收敛速度慢,又由于变量非常多,所以使用
步骤为先求目标函数的梯度,然后利用LBFGS求方向,最后利用线性搜索确定步距,完成一次迭代。具体参考lbfgsUpdate.m,lbfgs.m, http://en.wikipedia.org/wiki/L-BFGS
(4.2.10) 上一步求解slave problem还有一个比较重要的问题就是w的归一化。在迭代期间怎么使其训练出来的w*f具有可比性,就需要归一化。实验表明采用softmax(公式有点类似于逻辑回归)效果比较好。在obj.cc gradient函数中
(4.2.11) 设置这个样本的阈值。w训练好后,可以求每个正样本的score,取从小到大5%处的值为阈值modle_thresh.
(4.2.12) 由于在初始化root_filter不做hard_negtive mining,先不介绍。
(4.2.13) 由于存在左右视图,加入一个flipped root_filter.
4.3 为root_filter进行全局训练。
外循环
—这次训练有一些不同。除了CCCP的最后一步每次迭代的负样本采用很少的200.每次跌代(默认4次)
※1 求正样本的损失
pos_vals = info.scores(F);
hinge = max(0, 1-pos_vals);
pos_loss(t,1) = C*sum(hinge);
※2增加新的正样本train.m->poslatent
(1)剔除小的样本
(2)把带有正样本整个读入
(3)扣图,但这次是将图中带框的正样本作为一个整体取出,并pad一个比较大的边界(所有框最大的长的一半和最大宽的一半,不一定是同一个框的)
(4)为gdetect_pos.m做一些事先的处理在gdetect_pos_prepare.m
(4.1)特征金字塔
分为两个部分,前5层和后五层。1-5层的图片的大小为原来的大小2^[(i-1)/5]。每层的特征在对变小的图片取HOG特征,Cell变成原来的一半。6-10层与1-5层相应的图片大小一直,但HOG的CELL大小与原来的8保持一致。并在这里利用了HOG预留的第32维的信息,为特征加了一个检测框大小边界,如果是边界并在32标识了1,让机器去自动学习参数
td =model.features.truncation_dim;%32
for i = 1:pyra.num_levels
% wide border around thefeature map
pyra.feat{i} =padarray(pyra.feat{i}, [pady+1 padx+1 0], 0);
% write boundary occlusionfeature
pyra.feat{i}(1:pady+1, :, td) =1;
pyra.feat{i}(end-pady:end, :,td) = 1;
pyra.feat{i}(:, 1:padx+1, td) =1;
pyra.feat{i}(:, end-padx:end,td) = 1;
end(4.2)为了方便计算先判断每一层上是否有与检测框overlap大于0.7的位置。因为对于WLLSVM问题损失函数Loutput不大于0.7则为无穷,所以达不到这个要求的肯定就不是一个候选解
(4.3)计算动态规划表。如果在第二步中的其中一层达不到上述要求就可以直接跳过了。gdetect_dp.m
a 先计算特征金字塔在当前两个root_filter下的所处不同位置下的值(卷积)fconvsse.cc.这样我们就得到两个二维表对应于两个root_filter在相应位置所得到的分数,当然,两个表要设置成同样大小
b 后续遍历推导树的NT节点。从底层算到根节点。对于一个NT有structural_rule和deformation rule.它的分数包括rule的分数,它字节点NT的分数,还有它子节点T关联的滤波器的分数。
c 变形规则,rootfilter无效,只对partfilter有效,先提下,后面在patrfilter就直接套用这个了。 插一个知识点。为了检测小物体,虽然HOG做了归一化,对于不同大小的cell的分数有一定的可比性,但实验表示小物体的整体分数整体偏低。所以加入一个locationfeature function ,参看博士论文2.3.3
score{i} = score{i} + bias +loc_scores(i);
为了减少计算量,我们把变形限定在特征图像中的正负4个CELL中,也就是9*9个CELL范围。bounded_dt.cc.对应于每一层score表,每一个位置存的是当前点如果变形,那么在9*9范围内评分最高的分,并用X,Y维当前点对应最高点的位置信息。变形的损失是[0.01 0 0.01 0】*[x’^2 x’ y’^2 y’].x’,y’表示最高分点与当前点的距离。 至此,我们得到一个变形的score表
d 结构规则 (对于下取样还没怎么懂在gdetect_dp.m70行),右边的score包括structuralrule 右边所有节点的分
score{i} = score{i} + bias +loc_scores(i);
e 因此我们就可以自底向上得到所有NT的score表
f 为了是overlaps表与score保持一直,再计算一次overlap compute_overlaps.m
(4.4)Compute belief and loss adjusted detections for a foreground example gdetect_pos.m
a 将语法起点的所有规则的score表中,只要当前位置overlap<0.7,则分数设为负无穷apply_l_output,并把起点的第一条规则的分数取成所有规则的最高分。
b gdetect_parse.m Compute the set of detections from the dynamic programming tables stored
从所有层中选择一个最大的(为了提高计算速度,先可以用一个低的阈值滤到大多数的负无穷点),然后解析语法树get_detection_trees.cc(Compute detection windows, filter bounding boxes, and derivation trees.找到最高分rule,并找到变形的各个滤波器位置ds存放的是NT的x1,y1,x2,y2,rule,节点的score。bs是全局的位置和变形物体的位置,rule,score
(4.5)内循环迭代3次 hardnegtive
除了最后一次,在200幅图片中检测负样本中阈值>-1的hardnegtive用当前的正样本和负样本使用LBFGS求解w。收敛或者超出迭代推出
(4.6)备注:每次外迭代都会将之前的正样本清空,负样本使用的都是都是前面的200幅图像,外循环3次,内循环4次
4.4 模型合并
将上一步训练的躺着的模型,站的这模型合并成一个模型。参看model_merge.m.像上面一样外循环1次,内循环5次,但这个不再是局限与200张负图片,而是面向所有的max张负图片
4.5 partfilter训练
初始化 一个partfilet是6*6个cell大小的滤波器,并带有位置信息(x,y,scale).由于已经得到了root_filter.因此在root_filter中找n个(默认是6个parfilter)能量最高的地放,初始化滤波器。更新就是将他的参数合并到root_filter的滤波器的参数中,并重新训练。partfilter由于是个NT,它带有一个变形语法。同上面用动态规划训练。
5检测
其实原理和训练的部分相同。看懂了训练,也就知道了检测
参考
[1] Structured Support VectorMachines Sebastian Nowozin andChristoph H. Lampert
[2]http://bubblexc.com/y2011/503/
[3] learing structural SVMswith Latent Varialbles
[4] object detection grammars
[5] from rigd templates togrammars:object detection with structured models.
[6] histograms of orientedgradients for human detection














 3709
3709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









