







转自:http://blog.ihuxu.com/prml-study-series-chapter-1-polynomial-fitting/PRML多项式拟合
pattern recognition and machine learning 简称PRML是模式识别人工智能的基础书籍,好好学习学习,打下坚实基础,这里记录学习的点滴,可能会有误解之处,在后续的学习中会及时更正,也希望广大学友们,发现问题,能给我留言,我会及时更正,避免误导他人,共同学习进步。
- 看了多项式拟合(polynomial curve fitting),为什么要做多项式拟合?是因为我们根据现有的数据(输入,输出对),想要预测:给定一个新的数据,其输出是什么。中间的决策箱就是所谓的“训练模型”,决策结果称为:预测。
拟合函数如下:
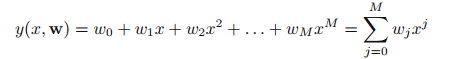
其中x是训练数据向量,W是训练的参数,整体称为模型,M是多项式的阶次。式(1)对x来说y是非线性的 但是对于w系数来说,y是线性的模型。这里x的次幂为M,这个参数表示模型的复杂程度,x的次幂越高,模型越复杂,同样也需要大于这个M的样本,也即是:模型越复杂,求解这些参数,需要的样本量就越大,至少保证M个位置参数,需要M个方程,来求解。
用误差函数(error function)来衡量拟合模型式子(1)是否拟合的好,所谓好,就是训练模型得出的输出y,与观测值Y_hat之间的差小,用平方和表示误差大小(为了避免模型输出与观测值相减后,正负相互抵消,这里一般采用平方和的形式):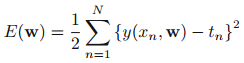
- 这里有两个关键词:欠拟合、过拟合。
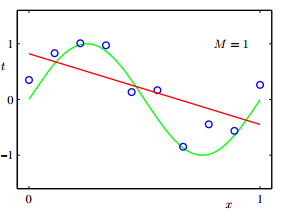
欠拟合:当数据复杂,模型简单(X的阶次低,如图所示,X的阶次M=1),所给出的训练样本(图中蓝色圆点)不足以拟合训练数据,训练出的模型是红色线条,很明显,与绿色原始数据模型,相差甚远。即模型输出结果与观测值差大,误差E较大,此时为欠拟合,如下如所示:
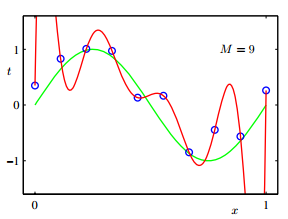
过拟合:则是模型过于复杂,X的阶次较高(如下图所示M=9),对与给出的训练数据,训练误差E很小,但是着对于新来的数据拟合效果很差,跟真实模型也相差甚远,震荡的比较厉害,因为过拟合模型经过经过每一个训练数据,所以受训练数据中噪声点干扰较大。
拟合效果正好:下图中模型适当,M=3,拟合效果还不错。
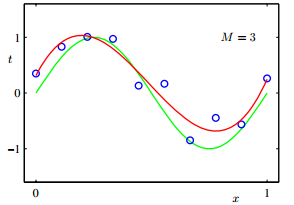
总结一下:
- 在相同样本情况下,不同的模型复杂程度,拟合的效果截然不同。这里,便需要选择合适的模型,那么问题来了,怎么选择合适?为什么这么选择?这设计到了模型选择的一些方法,比如:正则化、交叉验证等,在随后的总结中,我再说,可以先自己思考一下^.^
- 这里有一个重要的点,模型跟训练数据有关。我们都知道,sin(x)的多项式拟合是个高阶函数(即泰勒展开):
很明显是个复杂模型,那么为什么由上图可知,模型越复杂,反而过拟合,不能正确预测数据讷?因为我们忘记了一个前提:sin(x)的高阶拟合是训练数据量接近无穷多的时候,而我们上面所讲的模型训练数据量很少,不能无限逼近高阶,所以才会出现过拟合的现象。
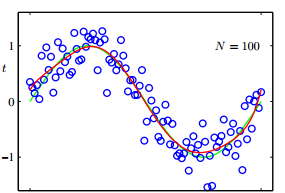
上图是M=9,样本数量N=100 时,的模型拟合,明显可以看出,比上面少量样本拟合效果好。
为了防止过拟合给误差函数加上一个惩罚项,称之为正则化(regularization)。最简单的就是加上系数的平方和,2范数正则化。
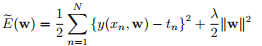
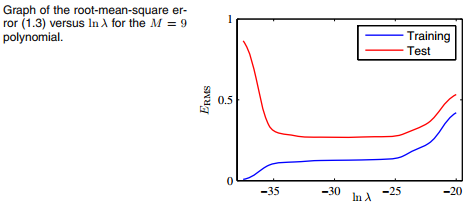
第二项就是正则化项。里面含有一个参数lambda,该值用于掌控在正则化项中平方差的相对重要程度 。实验证明:lambda越大,拟合效果越不好。
模型选择先开个头,下次接着聊。
谢谢模式识别与机器学习的作者们,理解的有不足的地方,大家要留言啊,及时更正。














 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









