






@初识Hadoop
Hadoop
分布式计算框架,可以在大量低成本硬件设备组成的集群上运行应用程序。
@起源与发展(http://baike.baidu.com/item/Hadoop)


名字起源
Hadoop这个名字不是一个缩写,而是一个虚构的名字。该项目的创建者,Doug Cutting解释Hadoop
的得名 :“这个名字是我孩子给一个棕黄色的大象玩具命名的。我的命名标准就是简短,容易发音和
拼写,没有太多的意义,并且不会被用于别处。小孩子恰恰是这方面的高手。”
@什么是Hadoop
第一印象:
1)数据量 可以是PB级别以上
2)上千个节点上的分布式处理方式
3)可靠性:启动和维护多个数据副本 用于确保失败的节点重新分布式处理数据
4)并行的方式处理,因此处理速度很快
5)可伸缩性->用于不同的数据级别
6)依赖于社区服务,费用低
7)开发语言:java(主要)c++(也可以)
8)平台:Linux、windows(cygwin)
进一步了解:
设计目标
1)故障检测与快速恢复
2)大 数据吞吐量,但是反应速度相对慢
3)移动计算:(计算过程 在 数据存储的位置,个人理解)
4)数据一次写入,多次读写
5)超大规模的数据集
6)可移植性强
模型:
Master/Slave
数据的复制与存放
# 统一机架
# 副本就近选择
# 安全模式 (检测数据块[包括副本]的有效性,并根据策略需要删除/复制部分数据块)
通信协议
# HDFS通信协议
# TCP/IP 网络协议

健壮性:
1)磁盘数据错识
NameNode 通过向 DateNode发送心跳信号判断该DateNode是否发生宕(读音:dang [捂脸])机,
若宕机,NameNode将启动复制操作。
2)集群均衡
3)数据完整性
HDFS写入的时候计算出校验和,然后每次读的时候再计算校验和,
DateNode在存储收到的数据前会校验数据的校验和。
访问:
FS Shell(https://hadoop.apache.org/docs/r1.0.4/cn/hdfs_shell.html)
浏览器
存储空间回收:
#删除和恢复功能
#有效减少副本数量
@Hadoop的组成(核心架构)
Hadoop集群搭建官方文档(https://hadoop.apache.org/docs/r1.0.4/cn/cluster_setup.html)
* Hadoop集群中的两大角色
通常,集群里的一台机器被指定为 NameNode,另一台不同的机器被指定为JobTracker。这些机器是masters。
余下的机器即作为DataNode也作为TaskTracker。这些机器是slaves。
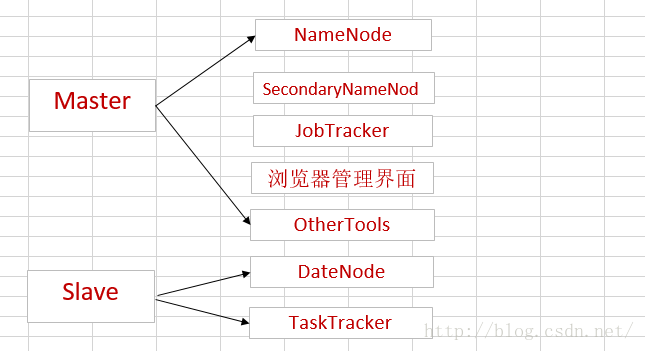
NameNode:
# HDFS的守护程序
# 纪录文件是如何分割成数据块的,还有这些数据块被存储到哪些节点上
# 对内存和I/O进行集中管理
# 是个单点,发生故障将使集群崩溃
SecondaryNameNode:
#监控HDFS状态的辅助后台程序
#与NameNode进行通讯,定期保存HDFS元数据快照
#当NameNode故障可以作为备用NameNode使用
#每个集群都有一个
JobTracker:
#用于处理作业(用户提交代码)的后台程序
#决定有哪些文件参与处理,然后切割task并分配节点
#监控task,重启失败的task(于不同的节点)
#每个集群只有唯一一个JobTracker,位于Master节点
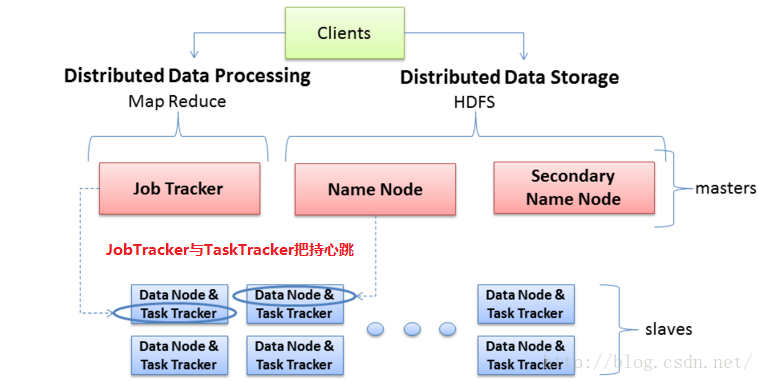
DateNode:
# 每个 从服务器 上运行一个
# 根据客户端或者是NameNode的调度存储和检索数据,并且定期向NameNode发送他们所存储的块(block)的列表。
TaskTracker:
#每个节点只有一个TaskTracker,但一个TaskTracker可以启动多个JVM,用于并行执行Map或Reduce任务
# 位于Slave节点上,与DateNode结合(代码与数据同位置)
#管理各自节点上的Task(由JobtTracker分配)
# 与JobTracker交互
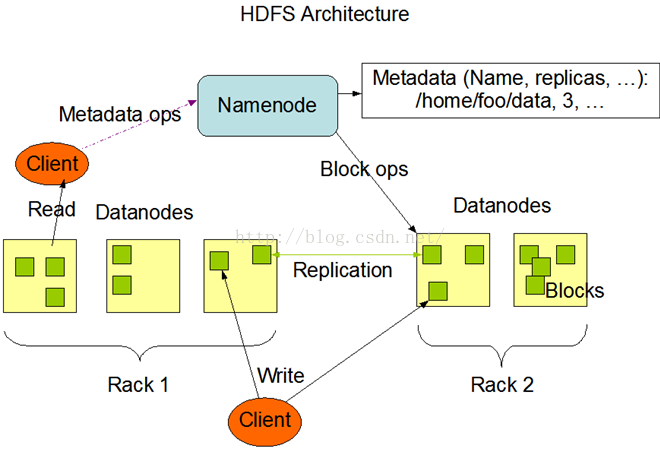
1)HDFS(Hadoop分布式文件存储系统 )
数据块(block):大文件会被分割成多个块进行存储,块(block)大小默认为64MB。
每一块会在多个DateNode上存储多份副本,默认是3份。
NameNode:负责管理文件目录、文件和块(block)的对应关系以及块和DateNode的对应关系。
DateNode:负责存储,大部分容错机制都是在DateNode上实现的。
2)MapReduce(分布式计算框架)
一个Map/Reduce 作业(job) 通常会把输入的数据集切分为若干独立的数据块,
由 Map任务(task)以完全并行的方式处理它们。框架会对Map的输出先进行排序,
然后把结果输入给Reduce任务。
通常作业的输入和输出都会被存储在文件系统(HDFS)中。整个框架负责任务
的调度和监控,以及重新执行已经失败的任务。
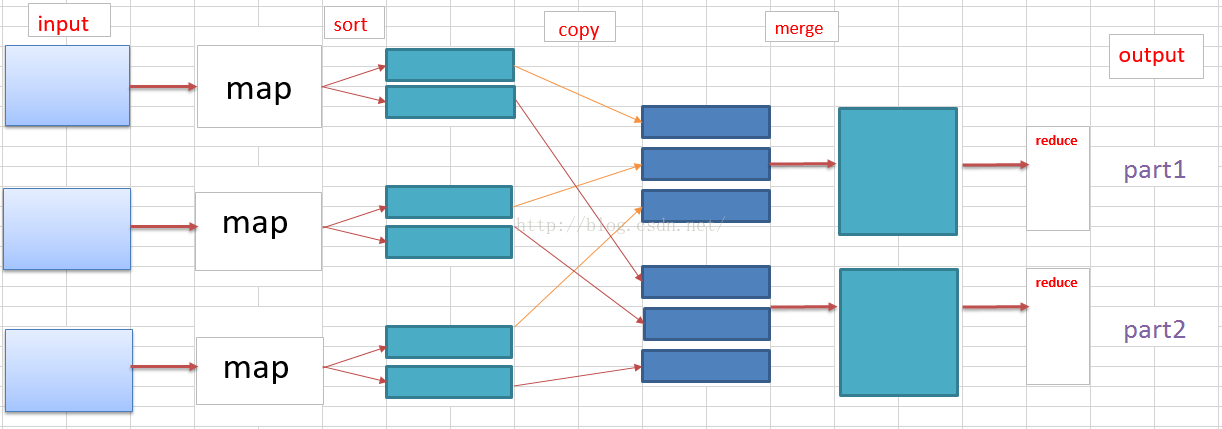
在运行一个MapReduce计算任务时候,任务过程被分为两个阶段:map阶段和reduce阶段,
每个阶段都是用键值对(key/value)作为输入(input)和输出(output)。而程序员要做
的就是定义好这两个阶段的函数:map函数和reduce函数。
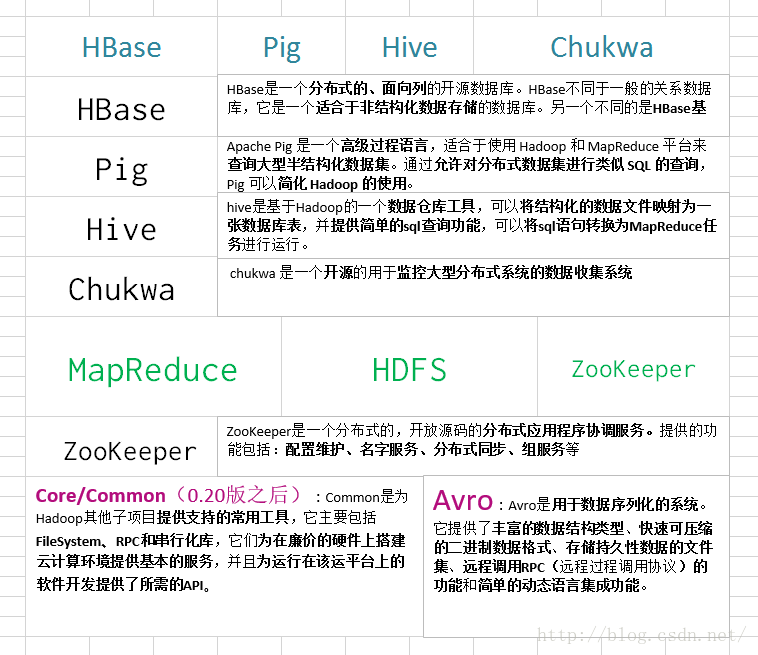
3)子项目家族















 3279
3279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











