







在知乎网站上看到一个关于词向量的问题:词向量( Distributed Representation)工作原理是什么,哪位大咖能否举个通俗的例子说明一下? 恰好最近在学习 word2vec, 尝试着根据对所读文献的理解写了个回答,供大家参考。
要将自然语言交给机器学习算法来处理,通常需要首先将语言数学化,词向量就是用来将语言中的词进行数学化的一种方式。
一种最简单的词向量方式是 one-hot representation,就是用一个很长的向量来表示一个词,向量的长度为词典的大小,向量的分量只有一个 1,其他全为 0, 1 的位置对应该词在词典中的位置。但这种词向量表示有两个缺点:(1)容易受维数灾难的困扰,尤其是将其用于 Deep Learning 的一些算法时;(2)不能很好地刻画词与词之间的相似性(术语好像叫做“词汇鸿沟”)。
另一种就是你提到的 Distributed Representation 这种表示,它最早是 Hinton 于 1986 年提出的,可以克服 one-hot representation 的上述缺点。其基本想法是:通过训练将某种语言中的每一个词映射成一个固定长度的短向量(当然这里的“短”是相对于 one-hot representation 的“长”而言的),将所有这些向量放在一起形成一个词向量空间,而每一向量则可视为该空间中的一个点,在这个空间上引入“距离”,则可以根据词之间的距离来判断它们之间的(词法、语义上的)相似性了。
为更好地理解上述思想,我们来举一个通俗的例子:假设在二维平面上分布有 N 个不同的点,给定其中的某个点,现在想在平面上找到与这个点最相近的一个点,我们是怎么做的呢?首先,建立一个直角坐标系,基于该坐标系,其上的每个点就唯一地对应一个坐标 (x,y);接着引入欧氏距离;最后分别计算这个词与其他 N-1 个词之间的距离,对应最小距离值的那个词便是我们要找的词了。
上面的例子中,坐标(x,y) 的地位就相当于词向量,它用来将平面上一个点的位置在数学上作量化。坐标系建立好以后,要得到某个点的坐标是很容易的。然而,在 NLP 任务中,要得到词向量就复杂得多了,而且词向量并不唯一,其质量依赖于训练语料、训练算法和词向量长度等因素。
一种生成词向量的途径是利用神经网络算法,当然,词向量通常和语言模型捆绑在一起,即训练完后两者同时得到。用神经网络来训练语言模型的思想最早由百度 IDL(深度学习研究院)的徐伟提出。这方面最经典的文章要数 Bengio 于 2003 年发表在 JMLR 上的《A Neural Probabilistic Language Model》,其后有一系列相关的研究工作,其中包括谷歌 Tomas Mikolov 团队的 word2vec。
最近了解到词向量在机器翻译领域的一个应用,报道是这样的:
谷歌的 Tomas Mikolov 团队开发了一种词典和术语表的自动生成技术,能够把一种语言转变成另一种语言。该技术利用数据挖掘来构建两种语言的结构模型,然后加以对比。每种语言词语之间的关系集合即“语言空间”,可以被表征为数学意义上的向量集合。在向量空间内,不同的语言享有许多共性,只要实现一个向量空间向另一个向量空间的映射和转换,语言翻译即可实现。该技术效果非常不错,对英语和西语间的翻译准确率高达 90%。
我读了一下那篇文章《Exploiting Similarities among Languages for Machine Translation》,引言中介绍算法工作原理的时候举了一个例子,我觉得它可以帮助我们更好地理解词向量的工作原理,特介绍如下:
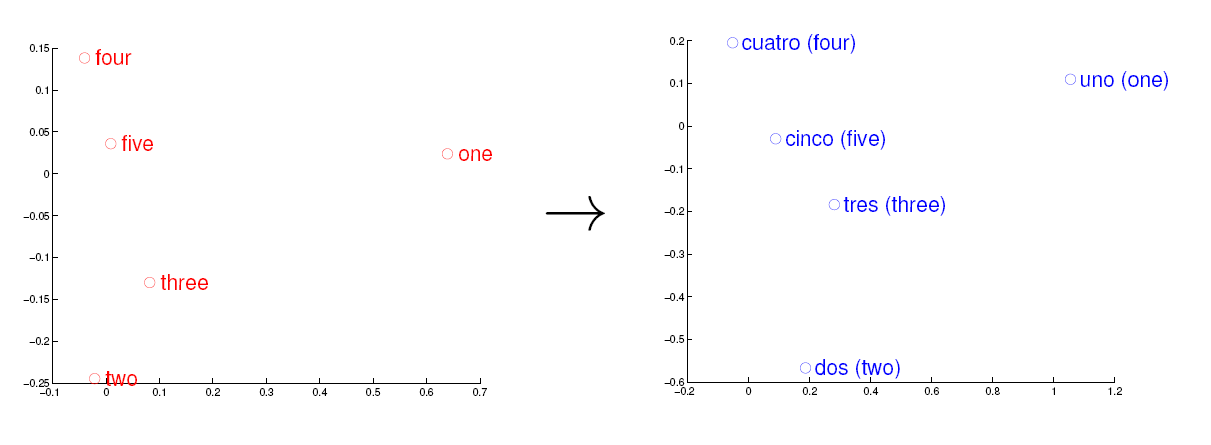
考虑英语和西班牙语两种语言,通过训练分别得到它们对应的词向量空间 E 和 S。从英语中取出五个词 one,two,three,four,five,设其在 E 中对应的词向量分别为 v1,v2,v3,v4,v5,为方便作图,利用主成分分析(PCA)降维,得到相应的二维向量 u1,u2,u3,u4,u5,在二维平面上将这五个点描出来,如下图左图所示。类似地,在西班牙语中取出(与 one,two,three,four,five 对应的) uno,dos,tres,cuatro,cinco,设其在 S 中对应的词向量分别为 s1,s2,s3,s4,s5,用 PCA 降维后的二维向量分别为 t1,t2,t3,t4,t5,将它们在二维平面上描出来(可能还需作适当的旋转),如下图右图所示:
观察左、右两幅图,容易发现:五个词在两个向量空间中的相对位置差不多,这说明两种不同语言对应向量空间的结构之间具有相似性,从而进一步说明了在词向量空间中利用距离刻画词之间相似性的合理性。
作者: peghoty
出处: http://blog.csdn.net/itplus/article/details/12782781
欢迎转载/分享, 但请务必声明文章出处.














 1109
1109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









