







 MLBase是一款基于Spark的分布式机器学习系统,旨在降低机器学习的门槛,使非专业人士也能轻松进行数据分析。通过其独特的优化器,MLBase能够自动选择合适的算法及参数,简化机器学习流程。
MLBase是一款基于Spark的分布式机器学习系统,旨在降低机器学习的门槛,使非专业人士也能轻松进行数据分析。通过其独特的优化器,MLBase能够自动选择合适的算法及参数,简化机器学习流程。
MLBase背景
MLBase是Spark生态圈里的一部分,专门负责机器学习这块(除它之外,还有负责图计算的GraphX、SQL ad-hoc查询的Shark、具备容错性查询能力的BlinkDB等)。看了MLBase的论文后,我是迫不及待想要分享一下这个ML系统。虽然对具体ML算法了解不多,但是对比类似的系统,比如Weka,Mahout而言,我感到MLBase的构想有更进一步的创新和独到之处。而且更重要的是,Spark上支持python算法包这件事情,我现在考虑的是:能打通策略组同学写的算法程序能依赖各节点上已经分配好的或自动依赖的函数库,而MLBase非常值得关注,他的实现本身其实很符合我们想要做的事,下面会具体说。
之前在youtube上,AMP实验室对MLBase有个介绍,并且说会在今年夏天release MLlib和MLI两个部分,在冬天发布ML Optimizer,从MLlib,MLI到ML Optimizer,是针对不同程度的算法科学家使用的不同抽象程度的接口。且MLlib会在Spark0.8版本里自带,现在我使用的Spark是0.7.2版本的。更多这三者的介绍请参考他的官网,里面一共也就这么点介绍。其实我蛮担心一个问题,就是Spark0.8发布后,开发机上不具备联网编译能力,到时候是不是又要想个办法在别的地方先编译一下Spark再拷进去,太囧了。
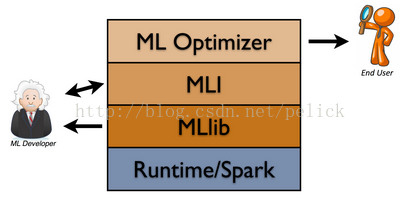
MLbase处理数据
MLbase想要让机器学习的门槛更低,让一些可能并不了解ML的用户也能使用MLbase这个工具来处理自己的数据,这份数据可以小,也可以是大数据。那MLBase怎么做到这件事呢?一方面,MLbase提供了一套类Pig的语言,他是声明式的。这件事其实是我们想做的,因为我在之前一篇文章中说,想要在Spark之上加一层DSL,MLBase的做法看上去恰恰很符合这点。比如说,我们要做分类,我们只需要写这么几行scala代码:
var X = load("some_data", 2 to 10)
var y = load("some_data", 1)
var (fn-model, summary) = doClassify(X, y)
MLbase架构核心
MLbase有一个新颖的优化器,会选择它认为最适合的已经在内部实现好了的机器学习算法和相关参数,来处理用户输入的数据,并返回模型或别的帮助分析的结果。总体上的处理流程如下图:
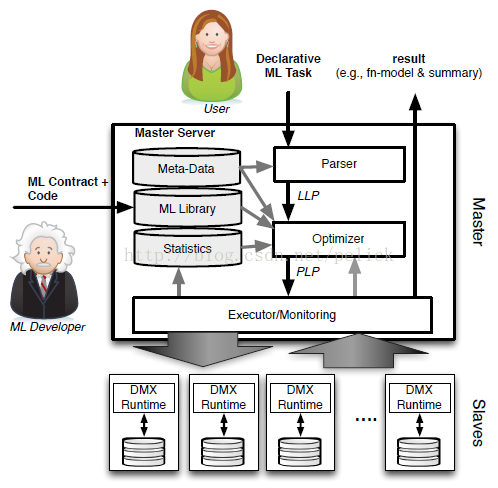
用户输入的类Pig的Task,比如doClassify(X, y),或者还可以做协同过滤doCollabFilter(X, y),还可以做一些图计算findTopKDegreeNodes(G, k = 1000)之类的事情,先会传给Parser处理,然后交给LLP。LLP是logical learning plan,即是逻辑上的一个学习选择过程,在这个过程里选择该用什么ML算法,他的特征提取应该用什么做,参数应该选什么,数据集怎么拆子数据集的策略等事情,LLP决定之后交给Optimizer。优化器是MLbase的核心,简单说他会把数据拆分成若干份,对每一份使用不同的算法和参数来运算出结果,看哪一种搭配方式得到的结果最优(注意这次最优结果是初步的),优化器做完这些事之后就交给PLP。PLP是physical learning plan,即物理(实际上)要执行的计划,他会让MLbase的master把任务分配给具体slave去最后执行之前选好的算法方案,把结果计算出来返回,同时返回这次计算的学习模型。
总结一些,这个流程是Task -> Parser -> LLP -> Optimizer -> PLP -> Execute -> Result/Model,即先从逻辑上,在已有的算法里选几个适合这个场景的套餐,让优化器都去做一遍,把认为当时最优的套餐给实际执行的部分去执行,返回结果。具体LLP,优化器内部包含的内容,执行过程我就不具体写了,论文中有介绍一些,这里就关注一下他的思想,下面再贴一个图吧。
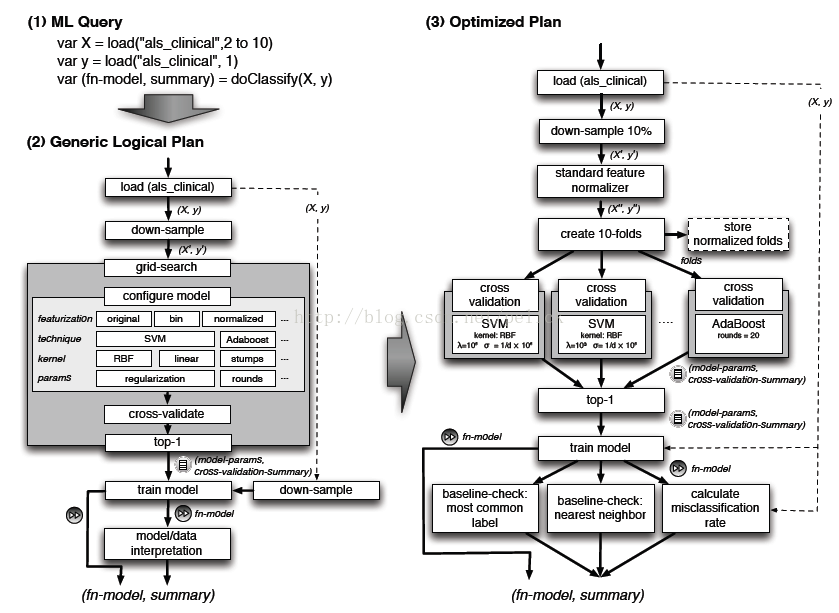
更激动人心的是,MLbase并不止于把结果返回给用户,他还有后续工作要做。大致做法是,在LLP、优化器部分,他会存储一些中间结果和特征,然后会后续继续搜寻和测试结果更好的算法和相关参数,并且会通知用户(具体也不知道后续通知是怎么个形式,文中只说会 inform the user about it )。除此之外,LLP内部实现的算法,是可以扩充的,MLbase考虑到了他的可扩展性,就是想让ML专家增加新的ML算法得到MLbase里去,应该是按照MLI,MLlib这些接口(第一张图)来扩充。大体上最关键的就是这几点:会自动找算法;自己会选择和优化;可以扩充。
MLbase特性总结
本文主要介绍了MLbase能做的事,并把最关键的实现方式简单介绍了一下,希望可以让读者感受到MLBase的设计思想和独到的地方。总的来说,Mlbase的核心是他的优化器,把声明式的task转化成复杂的学习计划,产出最优的模型和计算结果。与Weka,mahout不同的是,
首先MLbase是分布式的,Weka是一个单机的系统;
其次,Mlbase是自动化的,Weka和mahout都需要使用者具备机器学习技能,来选择自己想要的算法和参数来做处理;
再者,MLbase提供了不同抽象程度的接口,让算法可以扩充,让会ML的与不会ML的人都可以使用他;
最后,他可以基于Spark这个平台,这也是很大一个看点。
让我们期待它的发布!
(全文完)

















 1934
1934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









