







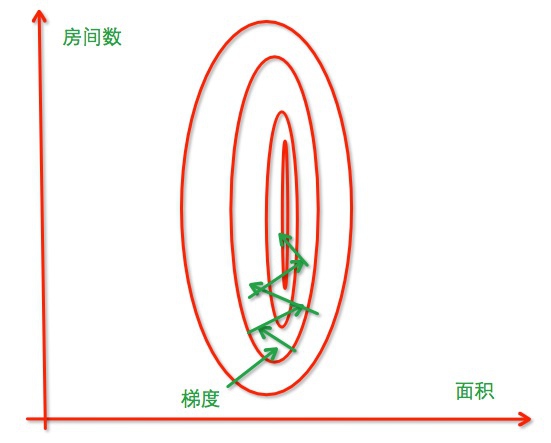
#归一化前:
#归一化后:
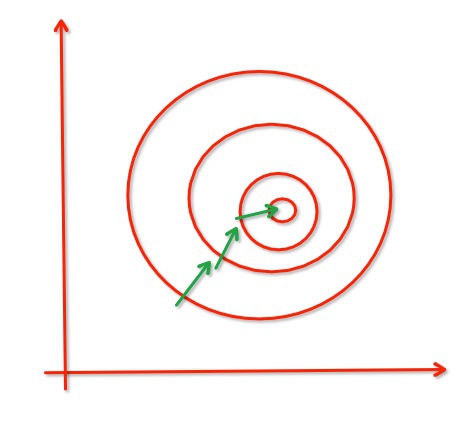
进行归一化的原因是把各个特征的尺度控制在相同的范围内,这样可以便于找到最优解,不进行归一化时如上图,进行归一化后如下图,可发现能提高收敛效率,省事多了。
在统计学中,归一化的具体作用是归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在-1–+1之间是统计的坐标分布。
假设有两个变量,都是均匀分布,X1范围是100000到200000,X2的范围是1到2。现在请在一张A4纸上画个坐标,点出这些点。很显然,你会点出很多处于同一直线上的点,我们称这条直线为L。也就是说,如果现在我们要做一个classification的话,X2几乎可以被忽略。X2很无辜的被干掉了,仅仅因为所谓量纲的问题。即便X2不被干掉,我们现在继续求解,来做 gradient descent。 很显然,如果某一步我们求得的下降方向不在直线L上,几乎可以肯定肯定这步不会下降。这就会导致不收敛,或者收敛但很慢。再来,我们做一遍归一化,全部化为[0,1]区间上。现在再在纸上画个坐标,点出这些点。好了,他们现在均匀的分布在一个圆的范围内。X2不会被忽略了,收敛的问题也解决了。
在量纲不一而对比标准统一的时候需要做归一化,归一化也有很多方法,正确选择方法对数据处理的有效性和精确性影响很大。
一张表有两个变量,一个是体重kg,一个是身高cm。假设一般情况下体重这个变量均值为60(kg),身高均值为170(cm)。1,这两个变量对应的单位不一样,同样是100,对于身高来说很矮,但对于体重来说已经是超重了。2,单位越小,数值越大,对结果的影响也越大,譬如170cm=1.7m。 简单讲,归一化的目的是可以用数值来直接进行比较,如果不归一化由于变量特性不同,同样加10,代表的意义不一样。
去均值
各维度都减对应维度的均值,使得输入数据各个维度都中心化为0,进行去均值的原因是因为如果不去均值的话会不容易拟合。 这是因为如果在神经网络中,特征值x比较大的时候,会导致W*x+b的结果也会很大,这样进行激活函数(如relu)输出时,会导致对应位置数值变化量太小,进行反向传播时因为要使用这里的梯度进行计算,所以会导致梯度消散问题,导致参数改变量很小,也就会不易于拟合,效果不好。
import numpy as np
# 假设有一个数组 a
a = np.array([1, 2, 3, 4, 5,6])
# 计算 a 的均值和标准差
mean = np.mean(a)
std = np.std(a)
# 对 a 进行归一化处理
a_normalized = (a - mean) / std
归一化
一种是最值归一化,比如把最大值归一化成1,最小值归一化成-1;或把最大值归一化成1,最小值归一化成0。适用于本来就分布在有限范围内的数据。
另一种是均值方差归一化,一般是把均值归一化成0,方差归一化成1。适用于分布没有明显边界的情况。














 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









