







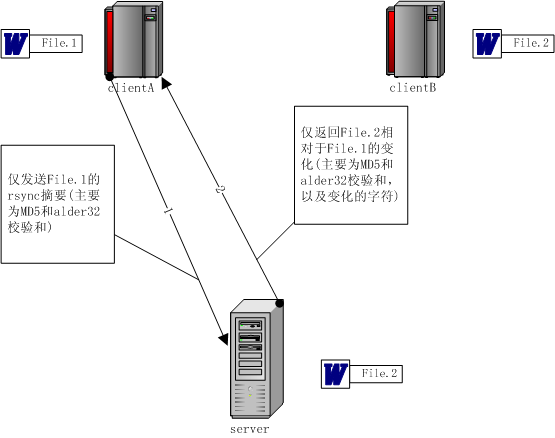
先看下图中的场景,客户端A和B,以及服务器server都保存了同一个文件,最初,A、B和server上的文件内容都是相同的(记为File.1)。某一时刻,B修改了文件内容,上传到SERVER上(记为File.2)。客户端A这时试图向服务器SERVER更新文件到最新内容,也就是File.1更新为File.2。
上面这个场景很常见,例如现在流行的网盘。假设我有一个文件a.txt在网盘上,上班时在公司的单位PC上更新了文件a.txt,下班后回到家里,家里PC硬盘上的a.txt就不是最新的内容,这时网盘就试图从服务器上去拿最新的a.txt了。
那么问题来了,如果在公司电脑上我只是更新了a.txt里很少的一部分内容,例如a.txt共有20M,我只更新了10个字节,难道家里的电脑上,网盘要从服务器上下载20M大小的文件?这明显很浪费带宽。
更有用的场景,假设我的手机android上也用了这个网盘(手机上网费贵得多),只改了几十字节的内容,就要下载20M的文件,得不偿失。或者我把这个文件共享给其他朋友,也有同样的问题:修改少量的内容,却同步完整的文件!
rsync算法就是用来解决上述问题的。client A发送它所保存的旧文件File.1少量的rsync摘要,server拿到后对比本地的File.2内容,得到File.2相对于File.1的变化,然后通过仅发送这个变化来代替发送完整的File.2内容,这样大大减少了网络传输数据。client A收到这个变化后,更新本地的File.1到最新的File.2。就是这么简单。下面详述rsync算法的步骤。
rsync首先需要客户端与服务器之间约定一个块大小,例如1K。然后把File.1等分成多个1K大小的字符串块,每块各计算出MD5摘要和Alder32校验和,如下图。
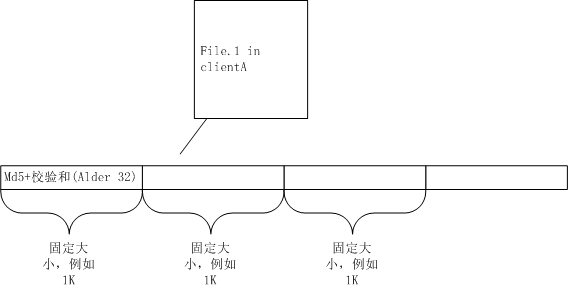
这里简单介绍下MD5和校验和。MD5是种哈希算法,用于把任意长度的字符串转化为固定为128位的定长字符串,这里可以保证,相同的字符串不可能计算出不同的MD5值。MD5的碰撞率是有的,就是说,两个不同的字符串有可能计算出相同的MD5值,但是这个机率非常小,这里我们忽略不计。例如,在rsync算法里,同一个文件按1K切分成多块,每块都有一个MD5值,如果两块字符串的MD5值相同,则我们认为这两块数据完全相同。
校验和是把上述1K块数据映射为32位大小整型数字上,我们采用Alder32算法,这里同样可以保证,相同的字符串不可能计算出不同的Alder32值。Alder32有两个优点:1、计算非常快,比MD5快多了,成本小;2、当我们有了从0-1024长度的校验和后,计算出1-1025或者2-1026等其他校验和非常方便,只要少量运算即可。当然,它的缺点也很明显,就是碰撞率比MD5高多了,所以,我们要把每个rynsc块同时计算出Alder32校验和与MD5值。Alder32算法我会在本文最后解释。
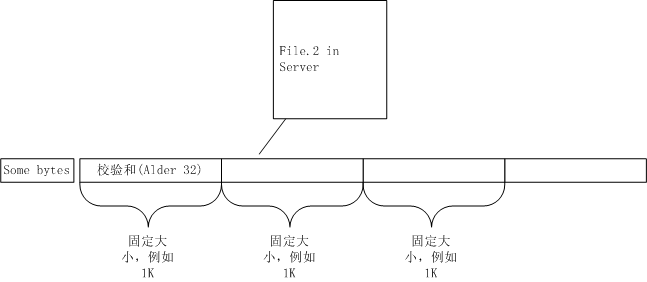
客户端按1K大小划分File.1文件为许多块,并对每块计算出MD5、Alder32校验和。最后不满1K的数据不做计算。之后,客户端把这些MD5、Alder32校验和依序通过网络传输给服务器,最后不满1K的数据直接发给服务器。那么,服务器收到数据后怎么处理呢?看下图。
首先重申,计算Alder32校验和非常快!
所以,服务器先把最新文件File.2从0字节开始,按1K切分成许多块,每块计算出Alder32校验和,然后与客户端发来的File.1切分出来的Alder32校验和相比,如果alder32值都不一样,毫无疑问,文件内容是不相同的。接着,把File.2从1字节开始,按1K切分成许多块,每块计算出Alder32校验和,再与客户端的校验和比。如此循环下去,直到某个校验和相同了,那么把这段字符串再计算出MD5值,再与客户端过来的对应的MD5值相比(还记得吧?客户端对每个块既计算出Alder32又计算出MD5值),如果不同,则继续往后移1字节,继续比Alder32、MD5值。如果相同,则认为这1K数据,服务器与客户端保存的一致,忽略这块数据(例如1K字节),继续向下看。
全部处理完后,按File.2的文件顺序,向客户端发送以下数据:对于不能够在客户端File.1数据块中找到相同块的字符串,直接列上发出;如果可以找到,则写上MD5和Alder32值,代替原来1024字节的数据块。同样,最后不足1K大小的部分直接列上发出。
纯理论读起来会有些吃力,我再把它简化了举个例子吧。假设客户端与服务器间约定的字符块大小不是1K,而是4个字节。客户端的文件内容是:
taohuiissoman
而服务器的文件内容是:
itaohuiamsoman
现在我们来看看,rsync算法是怎么运作的。
首先,客户端开始分块并计算出MD5和Alder32值。

如上图,像taoh是一块,对taoh分别计算出MD5和alder32值。以此类推,最后一个n字母不足4位保留。于是,客户端把计算出的MD5和alder32按顺序发出,最后发出字符n。
服务器收到后,先把自己保存的File.2的内容按4字节划分。
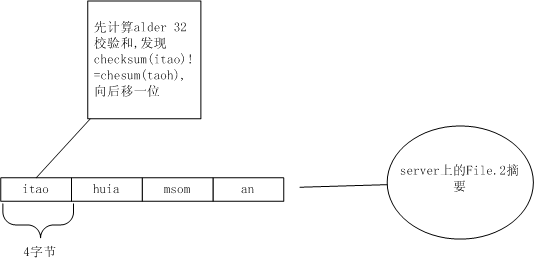
划分出itao、huia、msom、an,当然,这些串的Alder32值肯定无法从File.1里划分出的:taoh、uiis、soma、n找出相同的。于是向后移一个字节,从t开始继续按4字节划分。
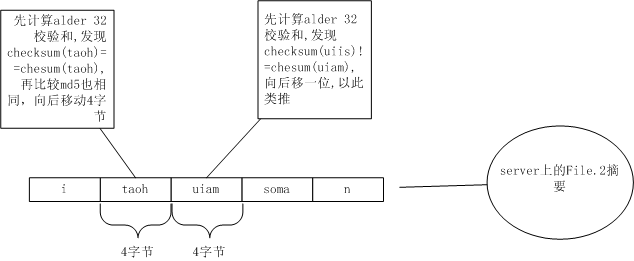
从taoh上找到了alder32相同的块,接着再比较MD5值,也相同!于是记下来,跳过taoh这4个字符,看uiam,又找不到File.1上相同的块了。继续向后跳1个字节从i开始看。还是没有找到Alder32相同,继续向后移,以此类推。
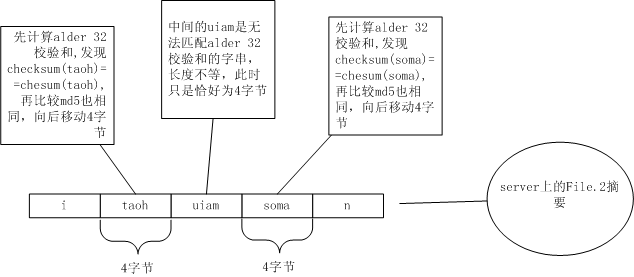
到了soma,又找到相同的块了。
重复上面的步骤,直到File.2文件结束。
那么,最终客户端与服务器间传输的数据如下图所示。
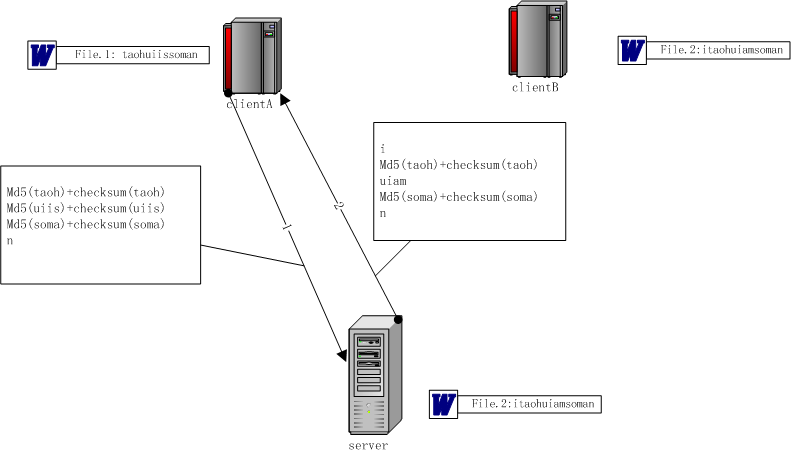
上面这个例子很简单,可由此推导出复杂的情况,包括File.2对File.1在任意位置上做了增、改、删,都能够完成。
如果这是个大文本文件,应用rsync算法就非常有意义,例如20M的文件,实际可能只传输1M的数据量!这样用户体验会好很多,特别是网速慢的场景。
同时增加的消耗,就是在PC上计算的MD5值和Alder32校验和,这只消耗少量的CPU和内存而已。
最后列下Alder32的算法:
- A = 1 + D1 + D2 + ... + Dn (mod 65521)
- B = (1 + D1) + (1 + D1 + D2) + ... + (1 + D1 + D2 + ... + Dn) (mod 65521)
- = n×D1 + (n−1)×D2 + (n−2)×D3 + ... + Dn + n (mod 65521)
- Adler-32(D) = B × 65536 + A
D1到Dn就是待计算的字符串块,所有位上的ASC字符。它的C代码实现为:
- const int MOD_ADLER = 65521;
- unsigned long adler32(unsigned char *data, int len) /* where data is the location of the data in physical memory and
- len is the length of the data in bytes */
- {
- unsigned long a = 1, b = 0;
- int index;
- /* Process each byte of the data in order */
- for (index = 0; index < len; ++index)
- {
- a = (a + data[index]) % MOD_ADLER;
- b = (b + a) % MOD_ADLER;
- }
- return (b << 16) | a;
- }














 1041
1041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









